Configuration des intervalles de communication VRRP
Dans un déploiement actif-actif, tous les nœuds NetScaler utilisent le protocole VRRP (Virtual Router Redundancy Protocol) pour publier leurs adresses VIP principales et les priorités correspondantes dans des paquets publicitaires VRRP (messages d’accueil) à intervalles réguliers.
Le VRRP utilise les intervalles de communication suivants :
- Hello Interval. Intervalle entre les messages d’accueil VRRP qu’un nœud d’une adresse VIP principale envoie à ses nœuds homologues.
- Dead Interval. Délai au bout duquel le nœud d’une adresse VIP de secours considère que l’état de l’adresse VIP principale est DOWN si aucun message d’bonjour VRRP n’est reçu du nœud de l’adresse VIP principale. Après l’intervalle mort, l’adresse VIP de sauvegarde prend le relais et devient l’adresse VIP principale.
Vous pouvez modifier ces intervalles à la valeur souhaitée. Ces deux intervalles de communication sont définis par nœud pour toutes les adresses VIP de ce nœud.
Pour configurer les intervalles de communication VRRP à l’aide de l’interface de ligne de commande :
À l’invite de commandes, tapez :
- set vrIDParam [-**helloInterval** \<msecs>] [-**deadInterval** \<secs>]
- sh vrIDParam
Exemple :
> set vrIDParam -helloInterval 500 -deadInterval 2
Done
<!--NeedCopy-->
Pour configurer les intervalles de communication VRRP à l’aide de l’interface graphique :
- Accédez à Système > Réseau, dans le groupe Paramètres, cliquez sur Paramètres du routeur virtuel.
- Dans Configurer le paramètre du routeur virtuel, définissez les paramètres Hello Interval et Dead Interval .
- Cliquez sur OK.
Exemple 1 : Nœuds avec les mêmes intervalles morts VRRP
Envisagez un déploiement actif-actif composé de NetScalers NS1, NS2 et NS3. Les adresses IP virtuelles VIP1, VIP2, VIP3 sont configurées sur chacun de ces ADC. En raison de leurs priorités, VIP1 est actif sur NS1, VIP2 est actif sur NS2 et VIP3 est actif sur NS3.
Comme indiqué dans le tableau ci-dessous, l’intervalle mort est défini sur la même valeur (2 secondes) sur les trois nœuds. Les intervalles de communication VRRP (intervalle bonjour et intervalle mort) d’un nœud s’appliquent à tous les VRID configurés sur le nœud et, à leur tour, à toutes les adresses VIP associées aux VRID du nœud.
Sur chaque nœud, les adresses VIP actives (master) sur ce nœud utilisent l’intervalle hello, et l’intervalle mort est utilisé par les adresses VIP inactives (sauvegarde) sur ce nœud. La préemption est désactivée pour les adresses VIP des trois nœuds.
Le tableau suivant répertorie les paramètres utilisés dans cet exemple : paramètres de l’exemple 1 de l’intervalle VRRP.
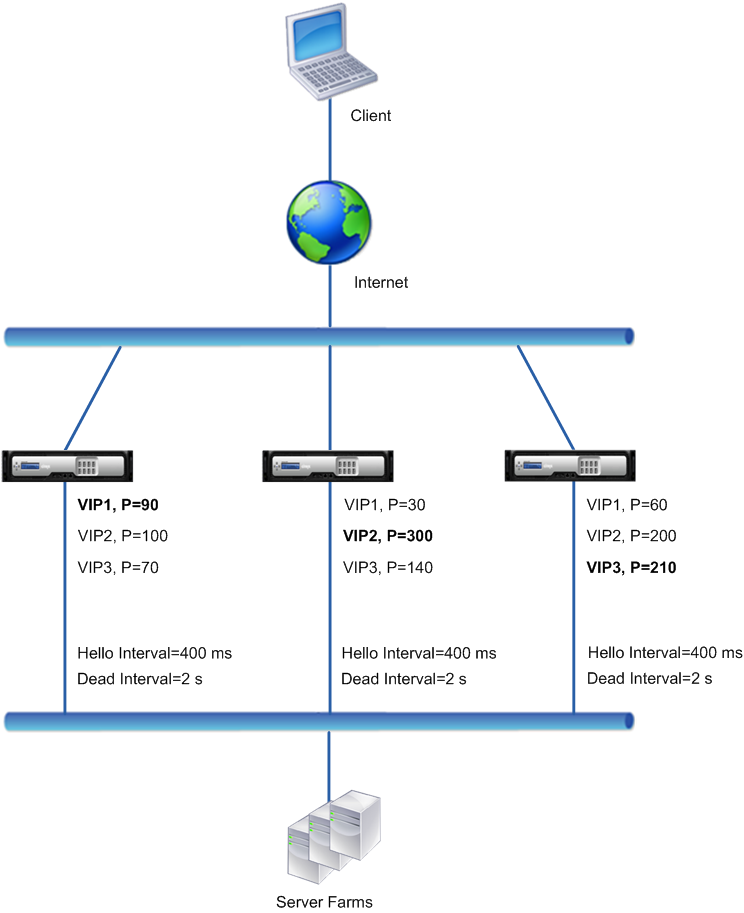
Le flux d’exécution est le suivant :
- NS1 envoie des messages bonjour à un intervalle défini de 400 ms à NS2 et NS3 pour l’adresse VIP1, car VIP1 est actif (le maître) sur NS1. De même, NS2 envoie des messages d’bonjour pour VIP2 et NS3 envoie des messages d’bonjour pour VIP3.
- Sur NS1, l’intervalle mort défini s’applique à VIP2 et VIP3, car ils sont inactifs (sauvegardes) sur NS1. De même, sur NS2, l’intervalle mort défini s’applique à VIP1 et VIP3, et sur NS3, l’intervalle mort défini s’applique à VIP1 et VIP2.
- Si NS1 tombe en panne, NS2 et NS3 considèrent que NS1 est hors service s’ils ne reçoivent aucun message d’accueil de NS1 pendant 2 secondes (intervalle d’inactivité). VIP1 sur NS3 prend le relais et devient actif (master) car sa priorité VRID (60) est supérieure à celle de VIP1 sur NS2 (30).
Exemple 2 : Nœuds avec différents intervalles morts VRRP
Envisagez un déploiement VRRP similaire au déploiement décrit dans l’exemple 1, mais avec un intervalle mort différent sur chaque nœud (NS1, NS2 et NS3). La préemption est désactivée pour les adresses VIP des trois nœuds.
Le tableau suivant répertorie les paramètres utilisés dans cet exemple : paramètres de l’exemple 2 de l’intervalle VRRP.
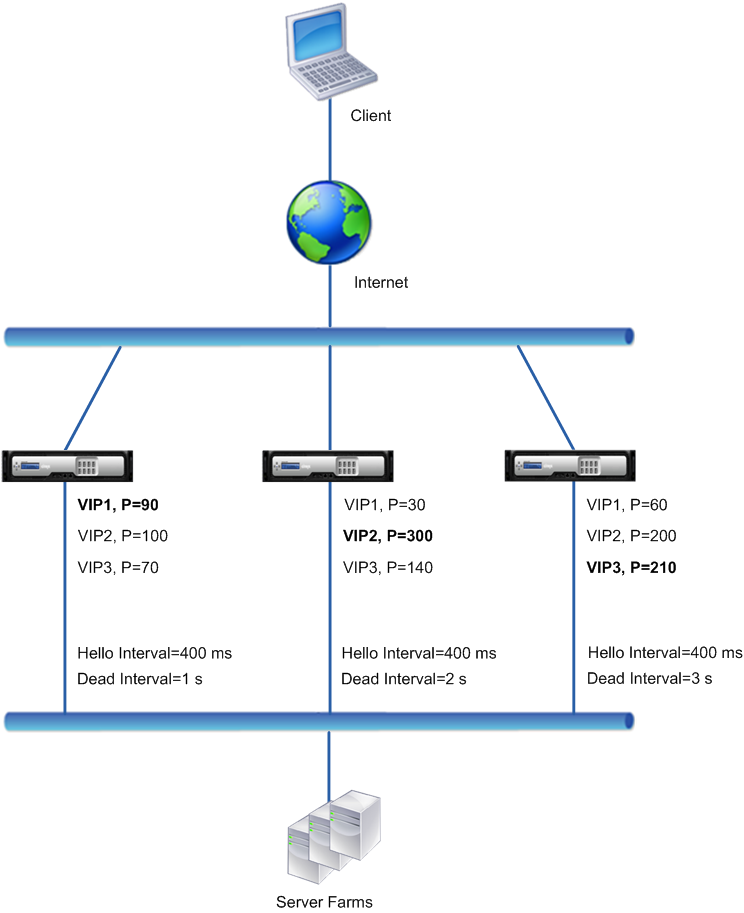
Le flux d’exécution est le suivant lorsque NS1 tombe en panne :
- NS2 considère que NS1 est hors service après n’avoir reçu aucun message d’accueil de NS1 pendant 2 secondes (intervalle mort de NS2).
- VIP1 sur NS2 prend le relais et devient actif (master). NS2 commence maintenant à envoyer des messages de bonjour pour VIP1.
Même si VIP1 sur NS3 a une priorité VRIP plus élevée (60) que VIP1 sur NS2 (30), l’intervalle mort plus long de NS3 (3 secondes, contre 2 secondes pour NS2) empêche VIP1 sur NS3 de prendre le relais avant que VIP 1 sur NS2 ne l’ait déjà fait.
Exemple 3 : Nœuds avec différents intervalles morts et la préemption activée
Considérez un déploiement VRRP similaire au déploiement décrit dans l’Example1, mais avec des intervalles morts différents sur les trois nœuds, NS1, NS2 et NS3, et avec la préemption activée pour l’adresse VIP1 sur NS3.
Le tableau suivant répertorie les paramètres utilisés dans cet exemple : paramètres de l’exemple 3 de l’intervalle VRRP.
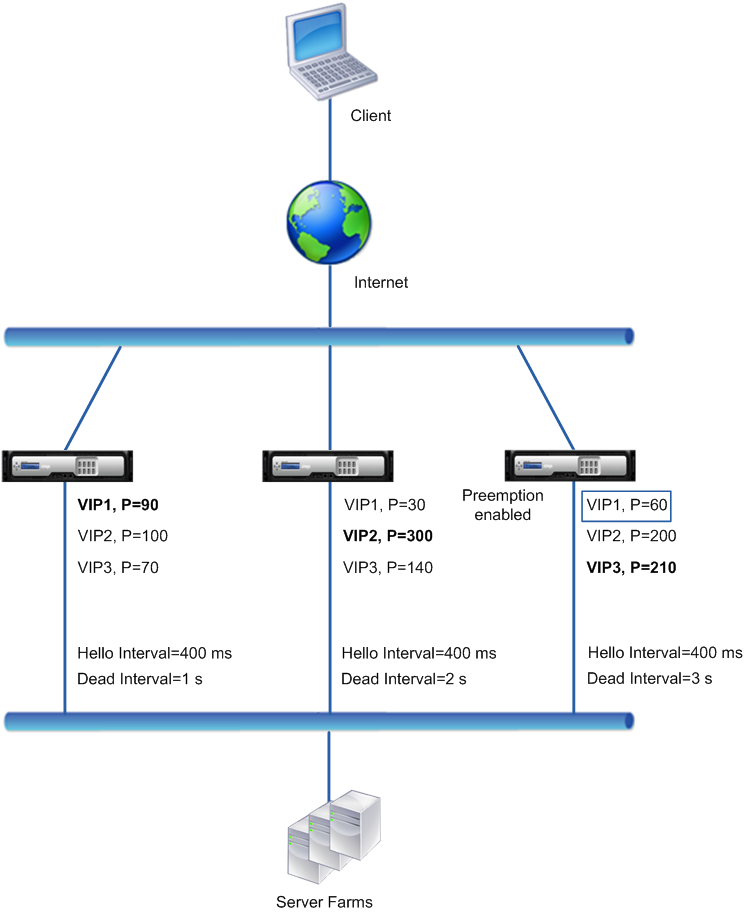
Le flux d’exécution est le suivant lorsque NS1 tombe en panne :
- NS2 considère que NS1 est hors service après n’avoir reçu aucun message d’accueil de NS1 pendant 2 secondes (intervalle mort défini par NS2). À ce stade, NS3, avec un intervalle mort de 3 secondes, ne considère pas que NS1 est en panne.
- VIP1 sur NS2 prend le relais et devient actif (master). NS2 commence maintenant à envoyer des messages de bonjour pour VIP1.
- Lors de la réception de messages bonjour de NS2 pour VIP1, NS3 préempte NS2 pour VIP1 car la préemption est activée pour VIP1 de NS3 et la priorité VRID (60) de VIP1 de NS3 est supérieure à celle (30) de VIP1 de NS2.
- VIP1 sur NS3 prend le relais et devient actif (master). NS3 commence maintenant à envoyer des messages de bonjour pour VIP1.