-
Getting Started with NetScaler
-
Solutions for Telecom Service Providers
-
Load Balance Control-Plane Traffic that is based on Diameter, SIP, and SMPP Protocols
-
Provide Subscriber Load Distribution Using GSLB Across Core-Networks of a Telecom Service Provider
-
Authentication, authorization, and auditing application traffic
-
Basic components of authentication, authorization, and auditing configuration
-
-
Web proxy support for outbound calls to IDP or third party endpoints
-
Web Application Firewall protection for VPN virtual servers and authentication virtual servers
-
On-premises NetScaler Gateway as an identity provider to Citrix Cloud™
-
Authentication, authorization, and auditing configuration for commonly used protocols
-
Troubleshoot authentication and authorization related issues
-
-
-
-
-
-
-
Configure DNS resource records
-
Configure NetScaler as a non-validating security aware stub-resolver
-
Jumbo frames support for DNS to handle responses of large sizes
-
Caching of EDNS0 client subnet data when the NetScaler appliance is in proxy mode
-
Use case - configure the automatic DNSSEC key management feature
-
Use Case - configure the automatic DNSSEC key management on GSLB deployment
-
-
-
Source IP address whitelisting for GSLB communication channels
-
Use case: Deployment of domain name based autoscale service group
-
Use case: Deployment of IP address based autoscale service group
-
-
Persistence and persistent connections
-
Advanced load balancing settings
-
Gradually stepping up the load on a new service with virtual server–level slow start
-
Protect applications on protected servers against traffic surges
-
Retrieve location details from user IP address using geolocation database
-
Use source IP address of the client when connecting to the server
-
Use client source IP address for backend communication in a v4-v6 load balancing configuration
-
Set a limit on number of requests per connection to the server
-
Configure automatic state transition based on percentage health of bound services
-
-
Use case 2: Configure rule based persistence based on a name-value pair in a TCP byte stream
-
Use case 3: Configure load balancing in direct server return mode
-
Use case 6: Configure load balancing in DSR mode for IPv6 networks by using the TOS field
-
Use case 7: Configure load balancing in DSR mode by using IP Over IP
-
Use case 10: Load balancing of intrusion detection system servers
-
Use case 11: Isolating network traffic using listen policies
-
Use case 12: Configure Citrix Virtual Desktops for load balancing
-
Use case 13: Configure Citrix Virtual Apps and Desktops for load balancing
-
Use case 14: ShareFile wizard for load balancing Citrix ShareFile
-
Use case 15: Configure layer 4 load balancing on the NetScaler appliance
-
-
-
-
Authentication and authorization for System Users
-
-
-
Configuring a CloudBridge Connector Tunnel between two Datacenters
-
Configuring CloudBridge Connector between Datacenter and AWS Cloud
-
Configuring a CloudBridge Connector Tunnel Between a Datacenter and Azure Cloud
-
Configuring CloudBridge Connector Tunnel between Datacenter and SoftLayer Enterprise Cloud
-
Configuring a CloudBridge Connector Tunnel Between a NetScaler Appliance and Cisco IOS Device
-
CloudBridge Connector Tunnel Diagnostics and Troubleshooting
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Getting started with NetScaler
This topic describes the basic features and configuration details of a NetScaler appliance. System and network administrators who install and configure network equipment can refer to the content.
Understanding NetScaler
The NetScaler appliance is an application switch that performs application-specific traffic analysis to intelligently distribute, optimize, and secure Layer 4-Layer 7 (L4–L7) network traffic for web applications. For example, a NetScaler appliance load balances decisions on individual HTTP requests instead of long-lived TCP connections. The load balancing feature helps slow down the failure of a server with less disruption to clients. The ADC features can be broadly classified as:
- Data switching
- Firewall security
- Optimization
- Policy infrastructure
- Packet flow
Data switching
When deployed in front of application servers, a NetScaler ensures optimal distribution of traffic by how it directs client requests. Administrators can segment application traffic according to information in the body of an HTTP or TCP request, and based on L4–L7 header information such as URL, application data type, or cookie. Numerous load balancing algorithms and extensive server health checks improve application availability by ensuring that client requests are directed to the appropriate servers.
Firewall security
The NetScaler security and protection protect web applications from Application Layer attacks. An ADC appliance allows legitimate client requests and can block malicious requests. It provides built-in defenses against denial-of-service (DoS) attacks and supports features that protect against legitimate surges in application traffic that overwhelms the servers. An available built-in firewall protects web applications from Application Layer attacks, including buffer overflow exploits, SQL injection attempts, cross-site scripting attacks, and more. In addition, the firewall provides identity theft protection by securing confidential corporate information and sensitive customer data.
Optimization
Optimization offloads resource-intensive operations, such as Secure Sockets Layer (SSL) processing, data compression, client keep-alive, TCP buffering, and the caching of static and dynamic content from servers. This improves the performance of the servers in the server farm and therefore speeds up applications. An ADC appliance supports several transparent TCP optimizations, which mitigate problems caused by high latency and congested network links. This accelerates the delivery of applications while requiring no configuration changes to clients or servers.
Policy infrastructure
A policy defines specific details of traffic filtering and management on a NetScaler. It consists of two parts: the expression and the action. The expression defines the types of requests that the policy matches. The action tells the ADC appliance what to do when a request matches the expression. For example, the expression might be to match a specific URL pattern for a security attack with the configured to drop or reset the connection. Each policy has a priority, and the priorities determine the order in which the policies are evaluated.
When an ADC appliance receives traffic, the appropriate policy list determines how to process the traffic. Each policy on the list contains one or more expressions, which together define the criteria that a connection must meet to match the policy.
For all policy types except rewrite, the appliance implements only the first policy that has a request match. For Rewrite policies, the ADC appliance evaluates the policies in order and performs the associated actions in the same order. Policy priority is important for getting the results you want.
Packet flow
Depending on requirements, you can choose to configure multiple features. For example, you might choose to configure both compression and SSL offload. As a result, an outgoing packet might be compressed and then encrypted before being sent to the client.
The following figure shows the HTTP2 packet flow in the NetScaler appliance.
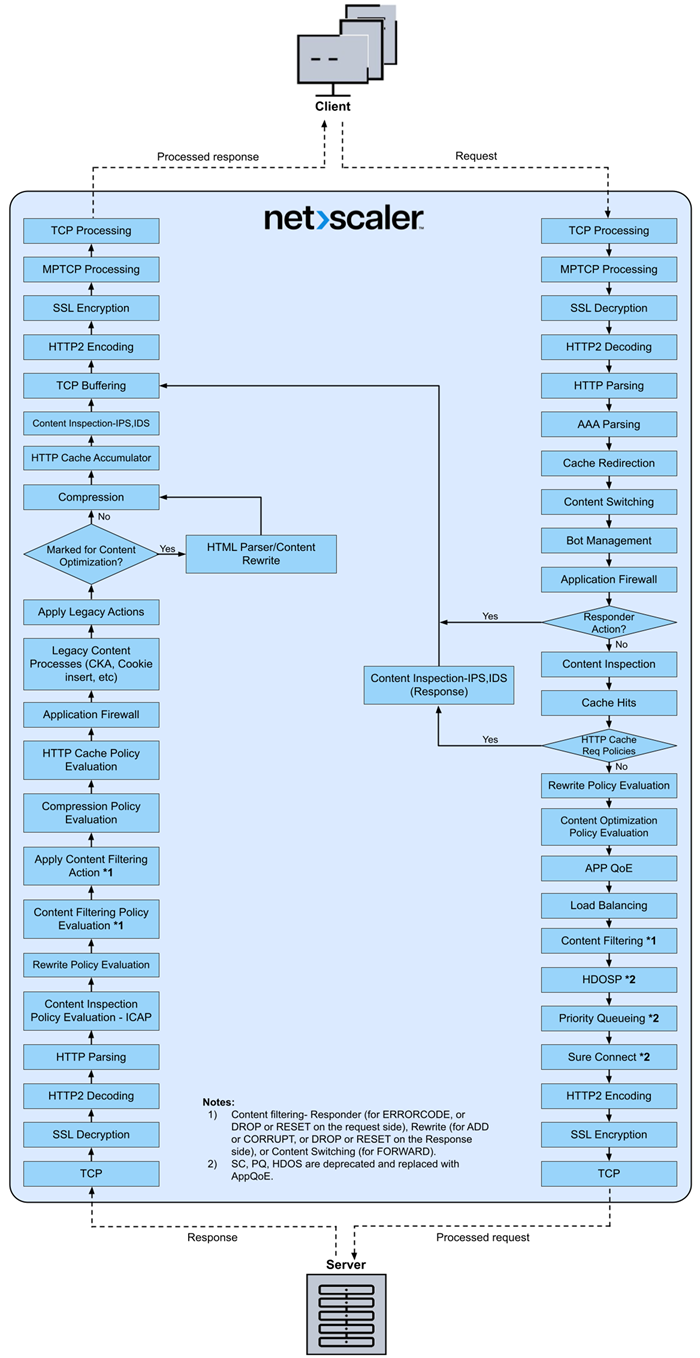
The following figure shows the data stream query processing flow in the NetScaler appliance. DataStream is supported for MySQL and MS SQL databases. For information about the DataStream feature, see DataStream.
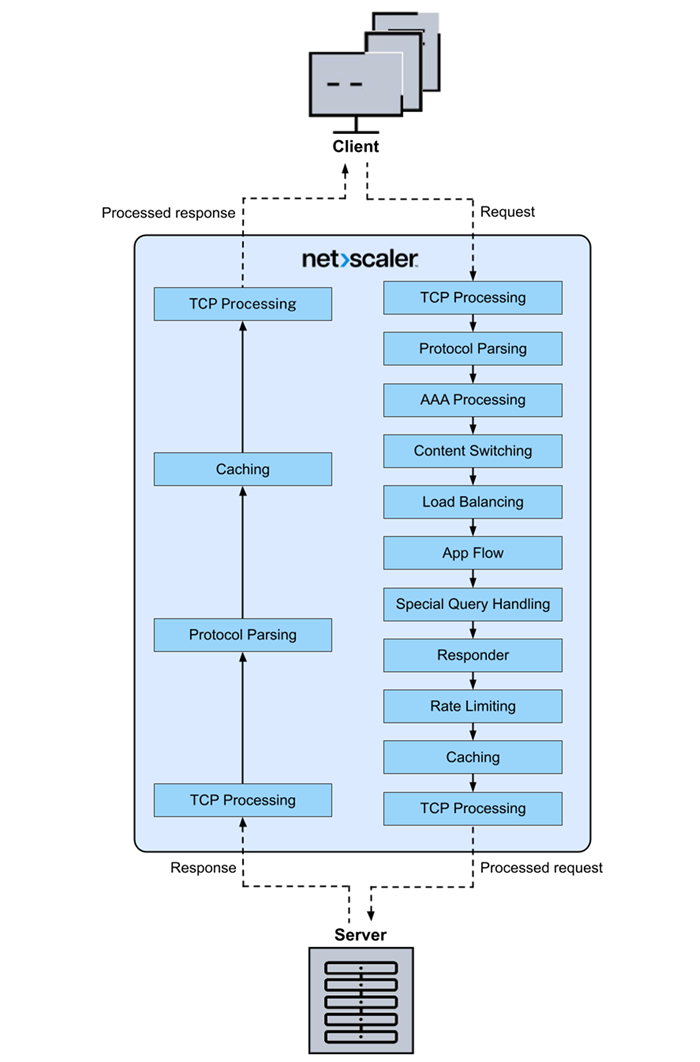
Note: If the traffic is for a content switching virtual server, the appliance evaluates policies in the following order:
- bound to global override.
- bound to load balancing virtual server.
- bound to content switching virtual server.
- bound to global default.
This way, if a policy rule is true and
gotopriorityexpressionis END, we stop further policy evaluation. In content switching, if no load balancing virtual server is selected or bound to the content switching virtual server, then we evaluate responder policies bound only to the content switching virtual server.
Share
Share
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.