Autoscale architecture for Microsoft Azure
NetScaler Console handles the client traffic distribution using Azure DNS or Azure Load Balancer (ALB).
Traffic distribution using Azure DNS
The following diagram illustrates how the DNS based autoscaling occurs using the Azure traffic manager as the traffic distributor:
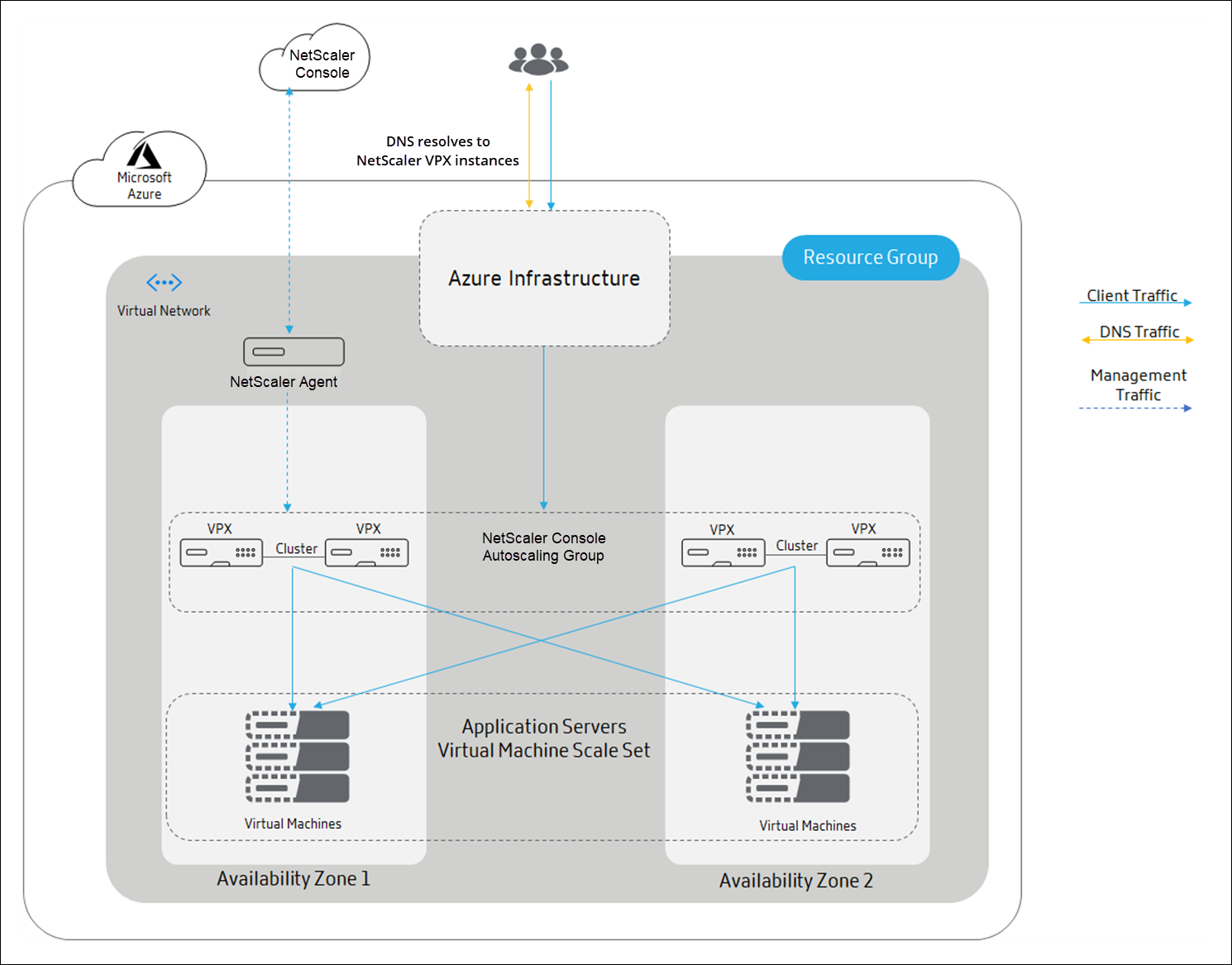
In DNS based autoscaling, DNS acts as a distribution layer. The Azure traffic manager is the DNS based load balancer in Microsoft Azure. Traffic manager directs the client traffic to the appropriate NetScaler instance that is available in the NetScaler Console autoscaling group.
Azure traffic manager resolves the FQDN to the VIP address of the NetScaler instance.
Note
In DNS based autoscaling, each NetScaler instance in the NetScaler Console Autoscale group requires a public IP address.
NetScaler Console triggers the scale-out or scale-in action at the cluster level. When a scale-out is triggered, the registered virtual machines are provisioned and added to the cluster. Similarly, when a scale-in is triggered, the nodes are removed and de-provisioned from the NetScaler VPX clusters.
Traffic distribution using Azure Load Balancer
The following diagram illustrates how the autoscaling occurs using the Azure Load Balancer as the traffic distributor:
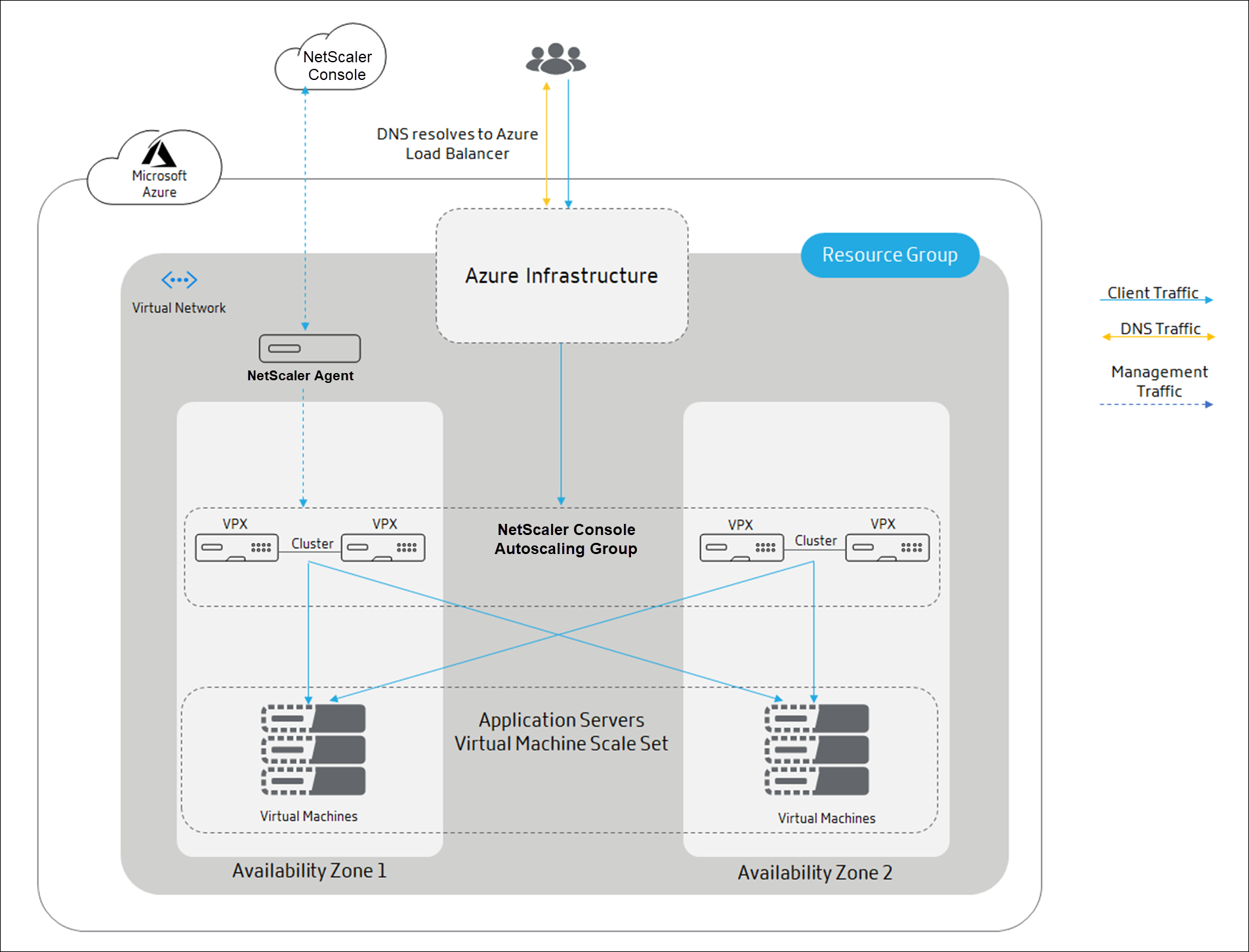
Azure Load Balancer is the distribution tier to the cluster nodes. ALB manages the client traffic and distributes it to NetScaler VPX clusters. ALB sends the client traffic to NetScaler VPX cluster nodes that are available in the NetScaler Console autoscaling group across availability zones.
Note
Public IP address is allocated to Azure Load Balancer. NetScaler VPX instances do not require a public IP address.
NetScaler Console triggers the scale-out or scale-in action at the cluster level. When a scale-out is triggered the registered virtual machines are provisioned and added to the cluster. Similarly, when a scale-in is triggered, the nodes are removed and de-provisioned from the NetScaler VPX clusters.
NetScaler Console Autoscale group
Autoscale group is a group of NetScaler instances that load balance applications as a single entity and trigger autoscaling based on the configured threshold parameter values.
Resource Group
Resource group contains the resources that are related to NetScaler autoscaling. This resource group helps you to manage the resources required for autoscaling. For more information, see Manage resource groups.
Azure back-end virtual machine scale set
Azure virtual machine scale is a collection of identical VM instances. The number of VM instances can increase or decrease depending on the client traffic. This set provides high-availability to your applications. For more information, see Virtual machine scale sets.
Availability zones
Availability Zones are isolated locations within an Azure region. Each region is made up of several availability zones. Each availability zone belongs to a single region. Each availability zone has one NetScaler VPX cluster. For more information, see Availability zones in Azure.
Availability sets
An availability set is a logical grouping of a NetScaler VPX cluster and application servers. Availability Sets are helpful to deploy NetScaler instances across multiple isolated hardware nodes in a cluster. With an availability set, you can ensure a reliable NetScaler Console autoscaling if there is hardware or software failure within Azure. For more information, see Availability sets.
The following diagram illustrates the autoscaling in an availability set:
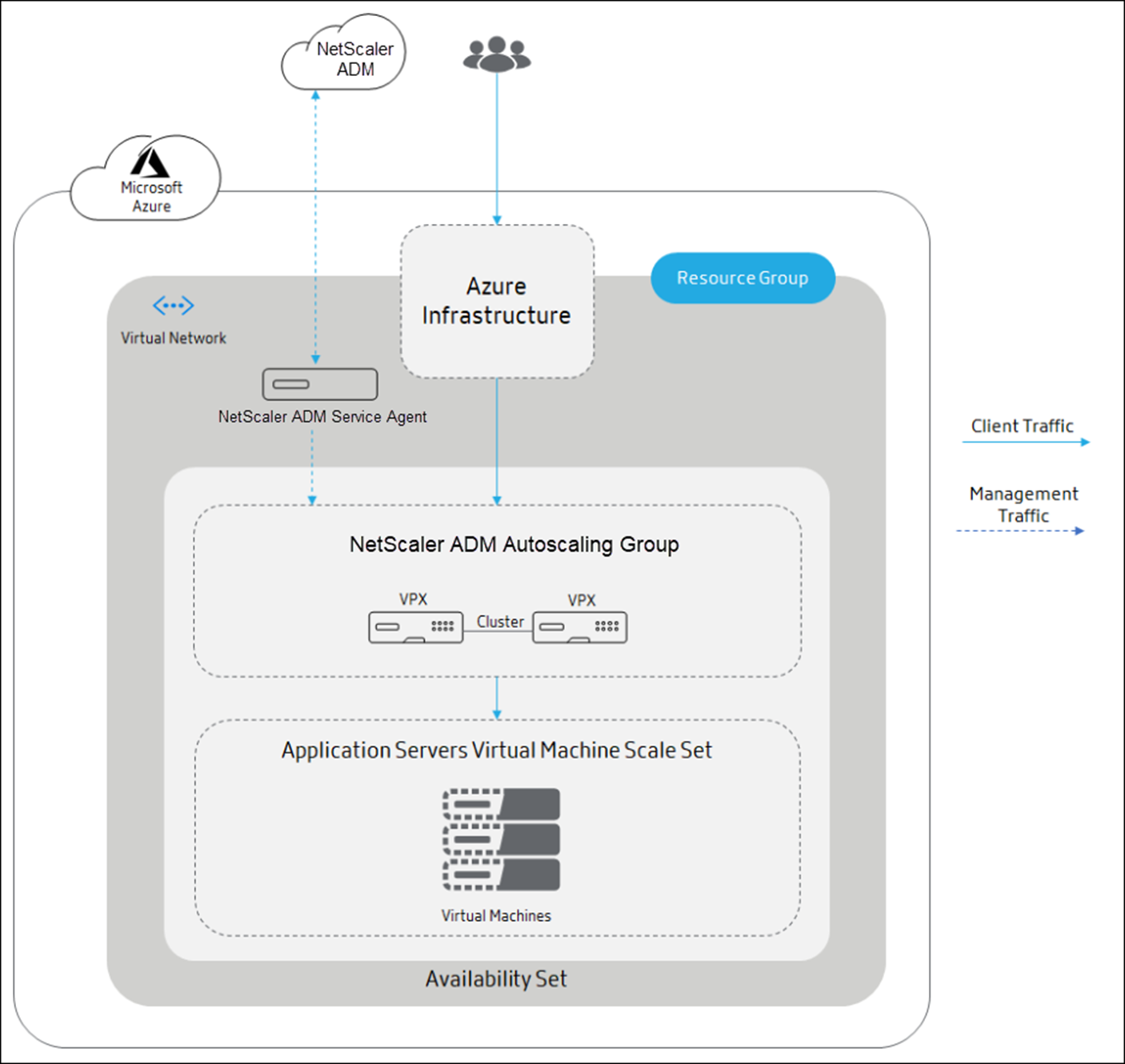
The Azure infrastructure (ALB or Azure traffic manager) sends the client traffic to a NetScaler Console autoscaling group in the availability set. NetScaler Console triggers the scale-out or scale-in action at the cluster level.
How the autoscaling works
The following flowchart illustrates the autoscaling workflow:
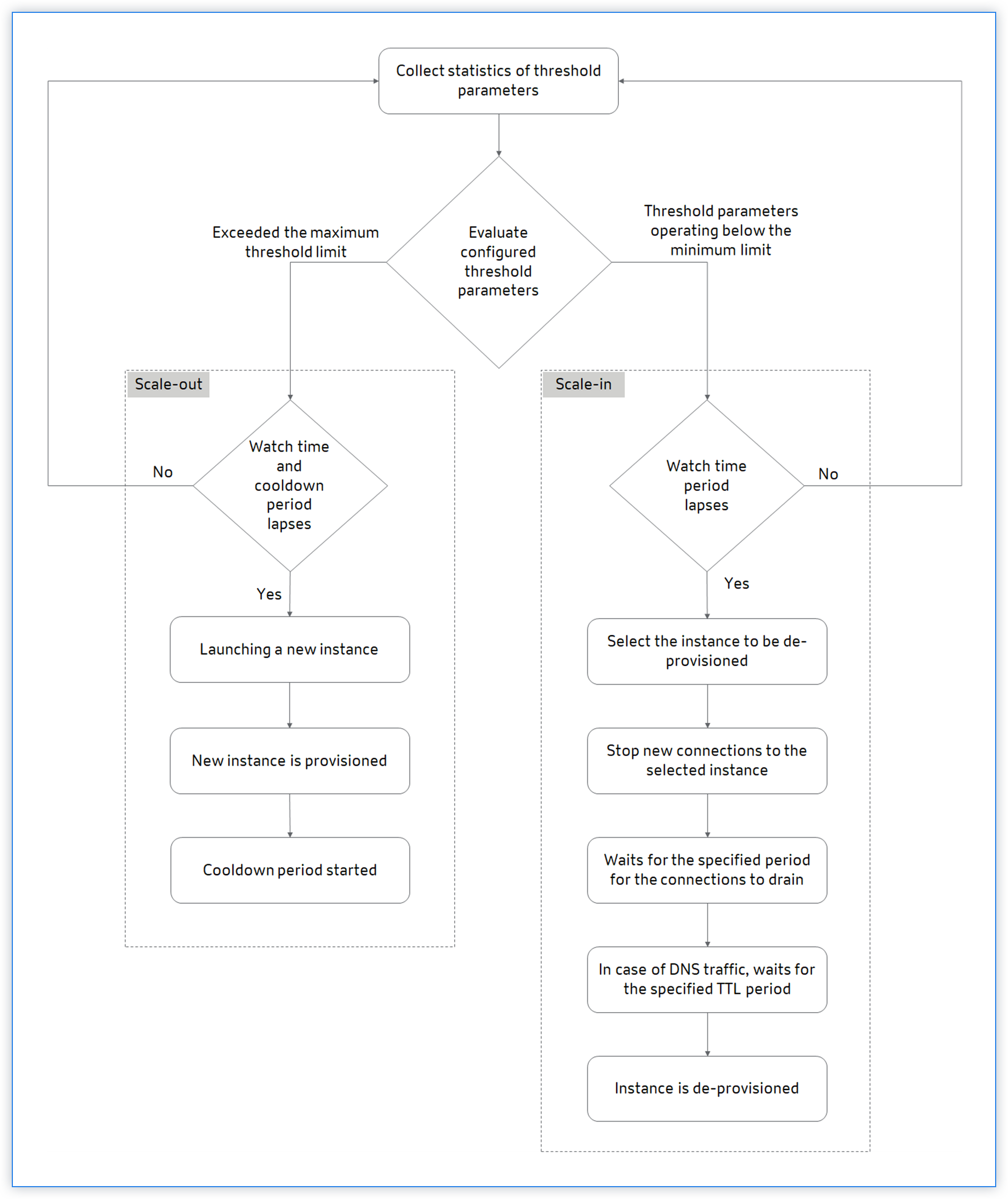
The NetScaler Console collects the statistics (CPU, Memory, and throughput) from the Autoscale provisioned clusters for every minute.
The statistics are evaluated against the configuration thresholds. Depending on the statistics, scale out or scale in is triggered. Scale-out is triggered when the statistics exceed the maximum threshold. Scale-in is triggered when the statistics are operating below the minimum threshold.
If a scale-out is triggered:
-
New node is provisioned.
-
The node is attached to the cluster and the configuration is synchronized from the cluster to the new node.
-
The node is registered with NetScaler Console.
-
The new node IP addresses are updated in the Azure traffic manager.
If a scale-in is triggered:
-
The node is identified to remove.
-
Stop new connections to the selected node.
-
Waits for the specified period for the connections to drain. In DNS traffic, it also waits for the specified Time To-Live (TTL) period.
-
The node is detached from the cluster, deregistered from NetScaler Console, and then de-provisioned from Microsoft Azure.
Note
When the application is deployed, an IP set is created on clusters in every availability zone. Then, the domain and instance IP addresses are registered with the Azure traffic manager or ALB. When the application is removed, the domain and instance IP addresses are deregistered from the Azure traffic manager or ALB. Then, the IP set is deleted.
Example autoscaling scenario
Consider that you have created an Autoscale group named asg_arn in a single availability zone with the following configuration.
-
Selected threshold parameters – Memory usage.
-
Threshold limit set to memory:
-
Minimum limit: 40
-
Maximum limit: 85
-
-
Watch time – 2 minutes.
-
Cooldown period – 10 minutes.
-
Time to wait during de-provision – 10 minutes.
-
DNS time to live – 10 seconds.
After the Autoscale group is created, statistics are collected from the Autoscale group. The Autoscale policy also evaluates if any an Autoscale event is in progress. If the autoscaling is in progress, wait for that event to complete before collecting the statistics.
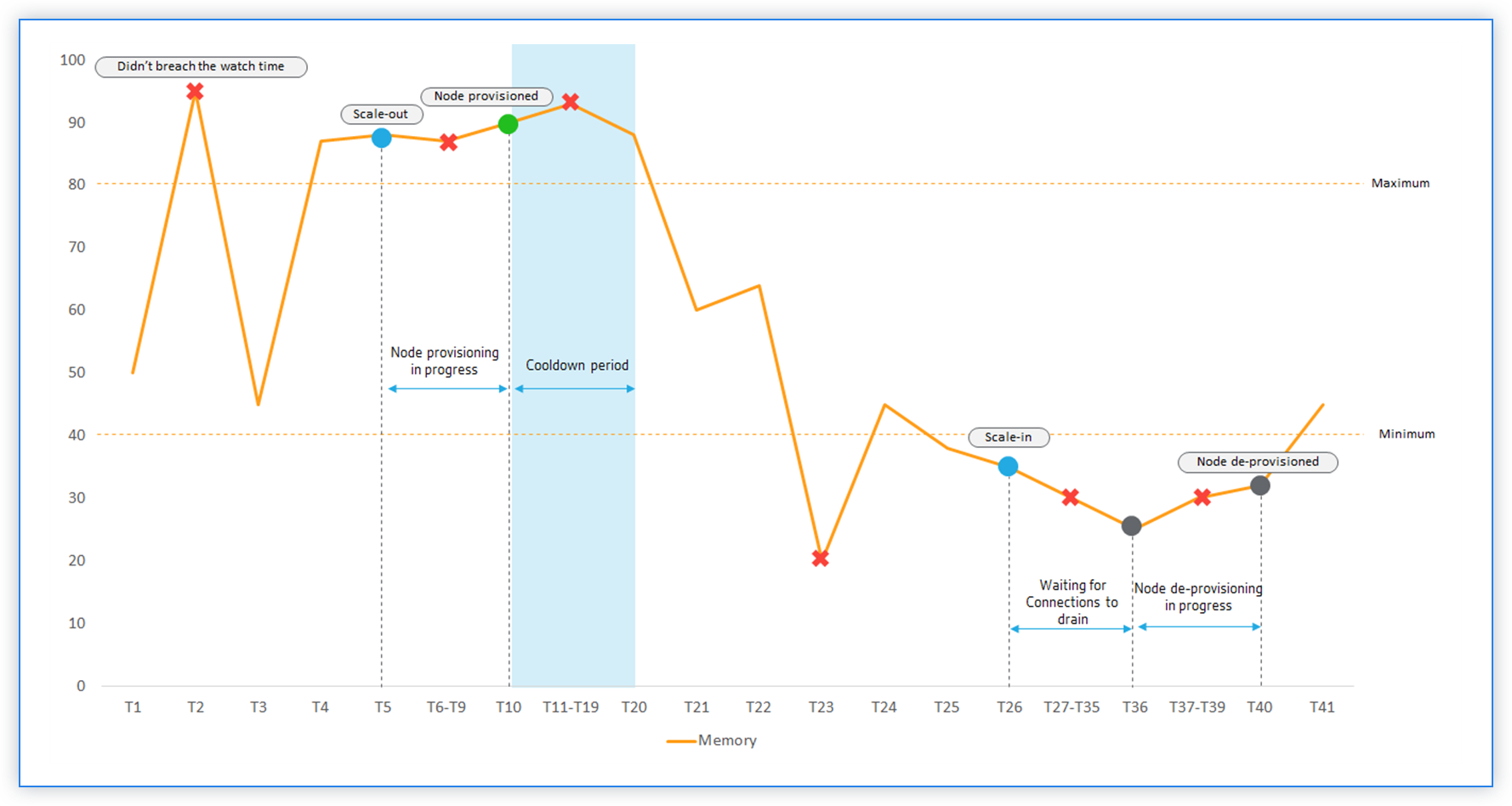
The sequence of events
-
Memory usage exceeds the threshold limit at T2. However, the scale-out is not triggered because it did not breach for the specified watch time.
-
Scale-out is triggered at T5 after a maximum threshold is breached for 2 minutes (watch time) continuously.
-
No action was taken for the breach between T5-T10 because the node provisioning is in progress.
-
Node is provisioned at T10 and added to the cluster. Cooldown period started.
-
No action was taken for the breach between T10-T20 because of the cooldown period. This period ensures the organic growing of instances of an Autoscale group. Before triggering the next scaling decision, it waits for the current traffic to stabilize and average out on the current set of instances.
-
Memory usage drops below the minimum threshold limit at T23. However, the scale-in is not triggered because it did not breach for the specified watch time.
-
Scale-in is triggered at T26 after the minimum threshold is breached for 2 minutes (watch time) continuously. A node in the cluster is identified for de-provisioning.
-
No action was taken for the breach between T26-T36 because NetScaler Console is waiting to drain existing connections. For DNS based autoscaling, TTL is in effect.
Note
For DNS based autoscaling, NetScaler Console waits for the specified Time-To-Live (TTL) period. Then, it waits for existing connections to drain before initiating node de-provisioning.
-
No action was taken for the breach between T37-T39 because the node de-provisioning is in progress.
-
Node is removed and de-provisioned at T40 from the cluster.
All the connections to the selected node were drained before initiating node de-provisioning. Therefore, the cooldown period is skipped after the node de-provision.