AWS FAQs
-
Does a NetScaler VPX instance support the encrypted volumes in AWS?
Encryption and decryption happen at the hypervisor level, and hence it works seamlessly with any instance. For more information about the encrypted volumes see the following AWS document:
https://docs.aws.amazon.com/kms/latest/developerguide/services-ebs.html
-
What is the best way to provision NetScaler VPX instance on AWS?
You can provision a NetScaler VPX instance on AWS by any of the following ways:
- AWS CloudFormation Template (CFT) in AWS marketplace
- NetScaler ADM
- AWS Quick Starts
- Citrix® AWS CFTs in GitHub
- Citrix Terraform Scripts in GitHub
- Citrix Ansible Playbooks in GitHub
- AWS EC2 launch workflow
You can choose any of the listed options based on the automation tool that you use.
For more details about the options, see NetScaler VPX on AWS.
-
How to upgrade NetScaler VPX instance in AWS?
To upgrade the NetScaler VPX instance in AWS, you can upgrade the system software or upgrade to a new NetScaler VPX Amazon Machine Image (AMI) by following the procedure at Upgrade a NetScaler VPX instance on AWS.
The recommended way to upgrade a NetScaler VPX instance is using the ADM service by following the procedure at Use jobs to upgrade NetScaler instances.
-
What is the HA failover time for NetScaler VPX in AWS?
- HA failover of NetScaler VPX within the AWS availability zone takes around 3 seconds.
- HA failover of NetScaler VPX across AWS availability zones takes around 5 seconds.
-
What level of support is provided for NetScaler VPX marketplace subscription customers who provide the technical support PIN?
By default, the “Select for Software” service is provided to customers who provide the technical support PIN.
-
In High availability across different zones using Elastic IP deployment, do we need to create Multiple IPSets for each application?
Yes. If there are multiple applications with multiple VIPs mapped to multiple EIPs then multiple IPSets are required. Therefore during HA failover, all the primary VIP mappings of EIPs are changed to secondary (new primary) VIPs.
-
Why is INC mode enabled in high availability across different zone deployments?
HA pairs across availability zones are in different networks. For HA synchronization, network configuration must not be synchronized. This is achieved by enabling INC mode on HA pair.
-
Can HA node in one availability zone communicate with back-end servers in another availability zone, provided those availabilty zones are in same VPC?
Yes, subnets in different availability zones of the same VPC are reachable by adding an extra route pointing to the backend-server subnet via SNIP. For example, if the SNIP subnet of ADC in AZ1 is 192.168.3.0/24 and the backend-server subnet in AZ2 is 192.168.6.0/24, then a route must be added in the NetScaler appliance present in AZ1 as 192.168.6.0 255.255.255.0 192.168.3.1.
-
Can High availability across different zones using Elastic IP and High availability across different zones using Private IP deployments work together?
Yes, both the configurations can be applied on the same HA Pair.
-
In High availability across different zones using Private IP deployment, if there are multiple subnets with multiple route tables in a VPC, how does a secondary node in HA pair know about the route table to be checked during HA failover?
Secondary node is aware of the primary NICs and searches across all the route tables in a VPC.
-
What is the size of the
/varpartition when using the default image for VPX on AWS? How to increase the disk space?The size of the root disk is limited to 20 GB to keep the disk image small.
If you want to increase the
/var/core/or the/var/crash/directory space, attach an extra disk. To increase the/varsize, currently, you must attach an extra disk and create a symbolic link to/var, after copying the critical contents to the new disk. -
How many packet engines are activated and allocated to vCPUs?
The packet engines (PEs) are limited by the number of licensed vCPUs. The NetScaler daemons are not pinned to any particular vCPU and might run on any of the non-PE vCPUs. According to AWS, the C5.9xlarge is a 36vCPU instance with 72 GB memory. With pooled licensing, the NetScaler VPX instance deploys with the maximum number of PEs. In this case, 19 PEs run on cores 1–19. However, ADC management processes run from CPUs 20–31.
-
How to decide the right AWS instance for ADC?
- Understand your use case and requirements like throughput, PPS, SSL requirement, and average packet size.
- Choose the right ADC offering and licensing that meets your requirements, such as VPX bandwidth offerings or vCPU based licensing.
- Based on the chosen offering, decide on the AWS instance.
Example:
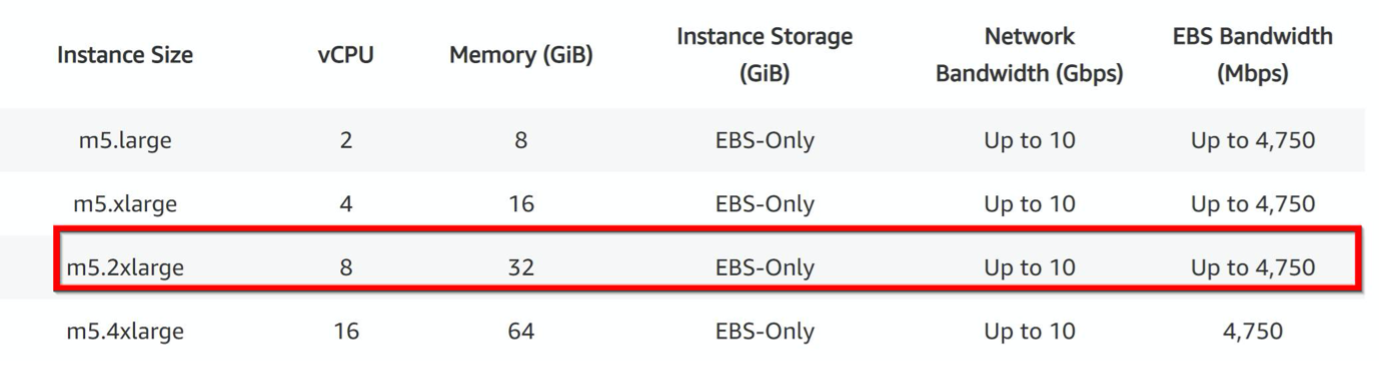
A 5 Gbps license enables 5 data packet engines. Hence, the vCPU requirement is 6 (5+1 for management). But 6 vCPU instance is not available. So an 8 vCPU is good enough to reach that throughput provided you choose a network that supports 5 Gbps bandwidth. For example, you must choose m5.2xlarge for a 5 Gbps bandwidth license to enable max PE allocation for 5 Gbps license. But if you use vCPU license that is not limited by throughput, you might get 5 Gbps throughput using the m5.xlarge instance itself.
-
Is three NICs-three subnets deployment mandatory for ADC in AWS?
Three NICs-three subnets is the recommended deployment, where each one for management, client and server network. This deployment gives better traffic isolation and VPX performance. Two NICs-two subnets, and one NIC-one subnet are the other available options. It is not recommended to have multiple NICs sharing a subnet in AWS, such as a two NICs–one subnet deployment. This scenario can cause networking issues like asymmetric routing. For more information, see Best practices for configuring network interfaces in AWS.
-
Why does an ENA driver on AWS always indicate a 1Gbps (1/1) link speed, irrespective of the instance’s network capabilities?
The reported speed of an AWS Elastic Network Adapter (ENA) is often displayed as 1Gbps (1/1) regardless of the selected instance type. This is because the indicated speed does not directly reflect the actual network performance. Unlike traditional network interfaces, ENA speeds can dynamically scale based on the instance’s requirements and workload. The true network performance is primarily determined by the instance type and size. Therefore, the actual network throughput can vary significantly depending on the specific instance type and the current network load.