Surveillance de l’expérience réseau
Présentation
Le service de surveillance de l’expérience réseau (NEM) (anciennement appelé Netscope) permet aux fournisseurs de services, aux entreprises, aux FAI et aux fournisseurs de services tiers d’accéder à des journaux de mesure Radar détaillés et à des rapports standard sous forme de données exploitables et synthétisées. Le NEM propose plusieurs journaux et rapports standard que les clients peuvent utiliser pour mesurer la qualité de leurs services.
Cette solution inclut la livraison de mesures Radar « brutes » et l’accès à l’API de données ITM. Le NEM fournit à la fois les données granulaires (sous forme de mesures brutes ou d’agrégats de données) et des alertes de seuil de données. Ces services aident à la découverte, à l’isolement de la disponibilité de la plate-forme et aux problèmes de performances chez les pairs de la plate-forme et les FAI sous-jacents.
Mesures Radar « brutes » : les mesures Radar fournissent des informations granulaires par événement, regroupées quotidiennement. Les mesures Radar incluent les données de mesure publiques de la communauté et privées collectées par la balise. Des données telles que la disponibilité, le temps de réponse et le débit pour les mesures HTTP et HTTPS sont incluses. Les champs de données suivants sont fournis :
- ID du fournisseur, IP du résolveur, adresses IP client obscurcies (/28)
- En-tête de référent obscurci, agent utilisateur, ASN de l’utilisateur final
- Données géographiques pour les champs du résolveur et du client
Les métriques Radar disponibles dans les mesures « brutes » sont :
- Disponibilité, temps de réponse et débit (le cas échéant)
- Temps de recherche DNS (facultatif), temps de connexion TCP (facultatif) et temps de connexion sécurisée (facultatif)
- Latence (facultatif)
- Temps de téléchargement (facultatif)
Les mesures Radar sont disponibles pour permettre aux clients d’effectuer leur propre analyse des données collectées. L’ensemble de données comprend des informations sur les performances et la disponibilité (erreurs) des fournisseurs pour une gamme de protocoles de communication.
Les données des fichiers journaux sont disponibles pendant 7 jours, à partir d’un compartiment AWS S3 ou Google Cloud Storage. Les clients peuvent récupérer les fichiers journaux des données communautaires et privées à l’aide des méthodes d’accès standard aux compartiments.
Mesures Radar « brutes » en temps réel (facultatif) : les mesures Radar brutes sont livrées en temps réel à un compartiment AWS S3. Ces journaux sont généralement disponibles dans les 5 minutes suivant la collecte. Ils offrent la même granularité que les mesures Radar brutes mentionnées précédemment.
API de données : l’API de données ITM Radar fournit des agrégats des données de mesure publiques de la communauté et privées de Radar. Les données sont mises à jour en continu et regroupées toutes les 60 secondes environ pour être récupérées par l’API. L’API de données est fournie pour permettre aux clients d’intégrer les données Radar dans leurs propres rapports et tableaux de bord.
Partage et livraison des journaux
- Les journaux Radar peuvent être livrés en temps réel et quotidiennement.
- Les rapports sont exécutés quotidiennement.
- Les résultats sont enregistrés dans AWS S3 (S3) ou Google Cloud Storage (GCS).
- Les journaux et les rapports ont tous deux une période de rétention de 7 jours et sont automatiquement supprimés une semaine après leur création.
- Les rapports sont généralement au format TSV (valeurs séparées par des tabulations) ou JSON, selon le type de rapport.
Les clients reçoivent des informations de connexion pour accéder aux compartiments S3 et GCS. Un outil en ligne de commande tel que s3cmd ou l’AWS CLI pour S3, ou gsutil pour GCS, peut être utilisé pour se connecter. Le fichier de configuration s3cmd reconnaît les clés d’accès reçues via l’interface utilisateur du portail et aide l’utilisateur à se connecter au compartiment S3.
L’AWS CLI doit être installé sur l’ordinateur du client pour se connecter à S3 et accéder aux journaux. Pour GCS, le client reçoit le fichier de clé d’accès sous forme de téléchargement via l’interface utilisateur du portail, qui peut être utilisé avec l’outil gsutil. Pour plus d’informations, reportez-vous à la FAQ.
Les clients reçoivent des notifications par e-mail dès que les rapports sont disponibles.
Paramètres de la plate-forme
Vous devez configurer votre plate-forme pour prendre en charge et produire les données requises pour Netscope NEM. Avant de commencer, assurez-vous que les paramètres suivants sont activés pour votre plate-forme :
- Pour les détails de synchronisation des ressources, activez Inclure les horodatages dans les Paramètres Radar avancés.
Navigation
Dans le menu principal, sélectionnez Netscope NEM. La page de configuration de la surveillance de l’expérience réseau s’ouvre.
Plates-formes
Sélectionnez les plates-formes requises pour démarrer le processus de configuration.
REMARQUE :
Les journaux et les rapports ne peuvent être configurés et générés que si au moins une plate-forme ou un réseau est sélectionné.
Les données synthétisées que le client reçoit incluent les mesures Radar des plates-formes sélectionnées (pour tous les réseaux associés).
Sélection des plates-formes
Pour les fournisseurs de services de contenu ou les entreprises, sélectionnez des plates-formes telles que les CDN, les clouds, les centres de données ou d’autres points d’extrémité. Sélectionnez les plates-formes pour lesquelles des mesures sont requises.

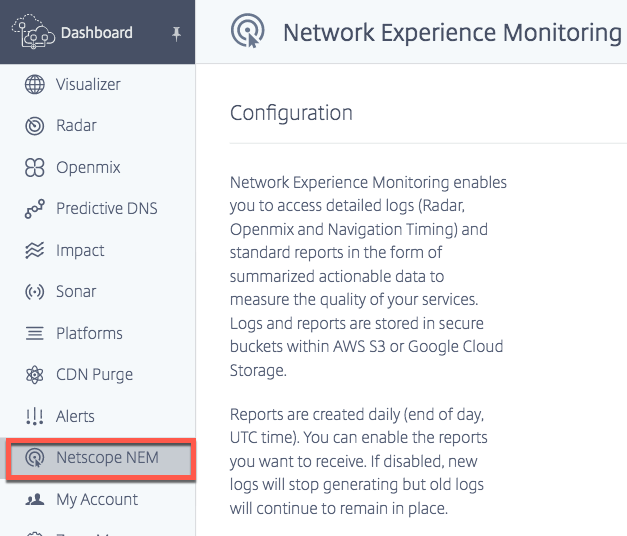
Journaux Radar
- Les journaux Radar sont disponibles pour les plates-formes.
- Ils incluent un sous-ensemble des champs disponibles dans les journaux bruts, avec certaines données anonymisées : IP client /28, référent haché MD5.
- Chaque mesure prise pour les plates-formes publiques est fournie, quelle que soit la page qui a généré la mesure.
REMARQUE :
Le NEM n’expose jamais les adresses IP client complètes. Au lieu de cela, il expose le /28. Par exemple, une adresse IP de 255.255.255.255 est affichée dans un rapport comme 255.255.255.240/28.
Fréquence des journaux
Les journaux Radar peuvent être générés quotidiennement (toutes les 24 heures), c’est-à-dire en fin de journée, heure UTC. Les journaux peuvent également être générés en temps réel (minute par minute).
Format de fichier
Choisissez TSV ou JSON pour recevoir les journaux et les rapports dans l’un de ces formats.
Type de mesure
Vous pouvez configurer les journaux pour les types de mesure suivants : Disponibilité, Temps de réponse et Débit. Dans le rapport, 1 : Disponibilité, 0 : Temps de réponse HTTP et 14 : Débit HTTP.
Détails de la synchronisation des ressources
Vous pouvez également choisir d’inclure les détails de la synchronisation des ressources en cliquant sur les boutons Oui ou Non. Les détails de la synchronisation des ressources incluent :
- Temps de recherche DNS
- Temps de connexion TCP
- Temps de connexion sécurisée
- Temps de téléchargement
Pour les descriptions des journaux, reportez-vous à Descriptions des journaux Radar et rapports pour les fournisseurs de services et les entreprises.
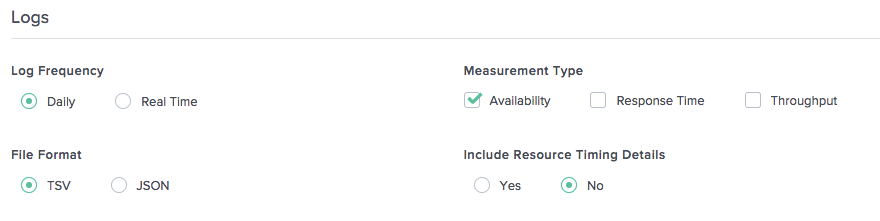
Journaux de synchronisation de la navigation
Fréquence des journaux
Les journaux de synchronisation de la navigation peuvent être générés quotidiennement (toutes les 24 heures), c’est-à-dire en fin de journée, heure UTC. Les journaux peuvent également être générés en temps réel (minute par minute).
Format de fichier
Choisissez TSV ou JSON pour recevoir les journaux de synchronisation de la navigation dans l’un de ces formats. Pour les descriptions des journaux, reportez-vous à Descriptions des journaux de synchronisation de la navigation.
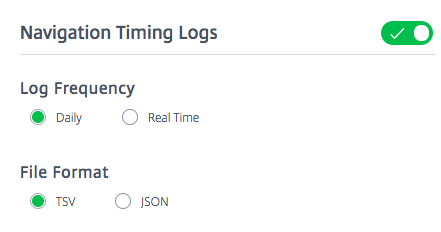
Journaux Openmix
Fréquence des journaux
Les journaux Openmix sont générés en temps réel (c’est-à-dire minute par minute). Ces journaux fournissent des mesures en temps réel prises pour les clients Openmix.
Format de fichier
Choisissez TSV ou JSON pour recevoir les journaux Openmix et HTTP Openmix dans l’un de ces formats. JSON est cependant le format recommandé.
Pour les descriptions des journaux, reportez-vous à Descriptions des journaux Openmix.
Livraison de services cloud
Cette option vous permet de sélectionner le mode de livraison. Vous pouvez choisir de recevoir les journaux et les rapports dans le compartiment AWS S3 ou dans le compartiment Google Cloud Storage (GCS). Vous pouvez accéder aux compartiments S3 et GCS avec les informations de connexion fournies et utiliser s3cmd ou l’AWS CLI pour S3, ainsi que la ligne de commande gsutil pour GCS.
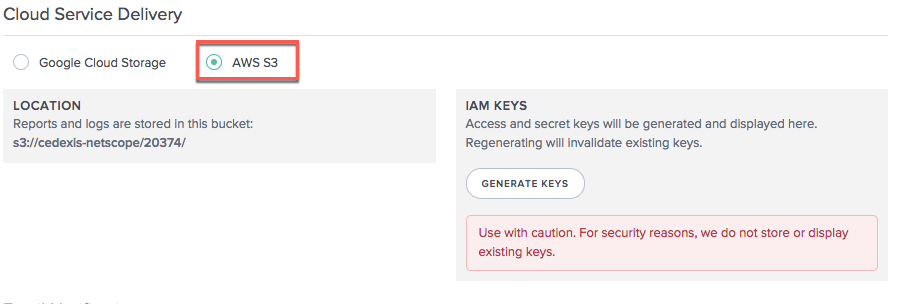
AWS S3
Pour que les journaux et les rapports soient livrés au compartiment AWS S3, sélectionnez AWS S3.
Emplacement
L’emplacement représente le compartiment dans AWS S3 où les journaux et les rapports sont enregistrés.
Clés IAM
Si vous sélectionnez le bouton Générer les clés sous AWS S3, les clés IAM AWS (clés d’accès et secrètes) sont générées et affichées sous Clés IAM. Assurez-vous d’enregistrer les clés, car elles ne sont stockées nulle part pour être consultées ultérieurement.
REMARQUE :
La paire de clés d’accès et secrètes est la seule copie des clés privées. Le client doit les stocker en toute sécurité. La régénération de nouvelles clés invalide les clés existantes. Le fichier de configuration s3cmd reconnaît les clés d’accès (reçues via l’interface utilisateur du portail) et aide le client à se connecter au compartiment S3. L’AWS CLI doit être installé sur la machine du client pour se connecter à S3.
Pour savoir comment utiliser les clés d’accès et secrètes avec s3cmd pour télécharger des rapports depuis le compartiment S3, reportez-vous à la FAQ.
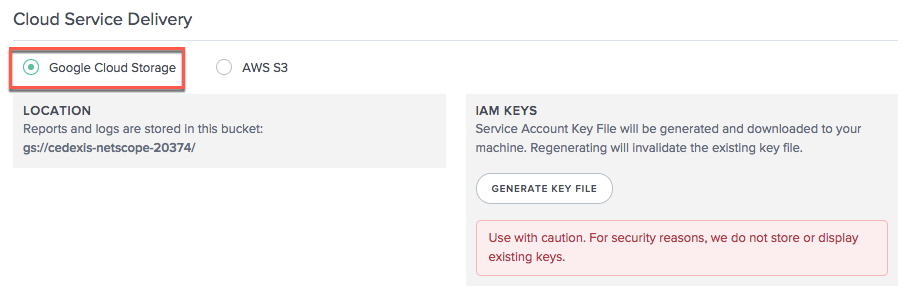
Google Cloud Storage
Pour que les journaux et les rapports soient livrés à GCS, sélectionnez Google Cloud Storage.
Emplacement
L’emplacement représente le compartiment dans Google Cloud Storage où les journaux et les rapports sont enregistrés.
Clés IAM
Lorsque vous sélectionnez le bouton Générer le fichier de clé, le fichier de clé de compte de service Google est téléchargé sur votre machine.
REMARQUE :
Ce fichier de clé est la seule copie de la clé privée. Notez l’adresse e-mail de votre compte de service et stockez en toute sécurité le fichier de clé privée du compte de service. La régénération d’un nouveau fichier de clé invalide le fichier existant.
Ce fichier de clé peut être utilisé avec l’outil gsutil pour télécharger des journaux et des rapports depuis le compartiment GCS. Pour plus de détails sur l’utilisation du fichier de clé pour télécharger des fichiers journaux, reportez-vous à la FAQ.
Descriptions des journaux Radar et rapports pour les fournisseurs de services et les entreprises
Journaux Radar pour les fournisseurs
- Ces journaux fournissent des mesures Radar pour les partenaires de référence.
- Ils fournissent chaque mesure prise pour les plates-formes publiques, quelle que soit la page qui a généré la mesure.
- Les journaux Radar incluent un sous-ensemble des champs disponibles dans les journaux bruts, avec certaines données anonymisées : IP client /28, référent haché MD5.
- Voici un exemple de partage de journal Radar de plate-forme au format de fichier TSV.
REMARQUE :
- Le NEM n’expose jamais les adresses IP client complètes. Au lieu de cela, il expose le /28. Par exemple, une adresse IP de 255.255.255.255 est affichée dans un rapport comme 255.255.255.240/28.
- Les informations géographiques du client sont extraites en fonction de l’IPv4 du client, qui est plus détaillée.
Descriptions des journaux
Voici les en-têtes de colonne et les descriptions des journaux Radar. Les champs apparaissent dans l’ordre suivant dans les fichiers de sortie :
| Journal | Description |
|---|---|
| Horodatage | Il s’agit de l’heure UTC de la requête au format AAAA-MM-JJTHH:MI:SSZ. La valeur réelle (à la seconde près) dans les tables de journaux est arrondie à l’heure la plus proche (2018-03-30T23:00:00Z) ou au jour le plus proche (2018-03-30T00:00:00Z) dans les tables horaires/journalières, respectivement. L’horodatage est toujours en UTC dans tous les jeux de données. |
| ID de nœud unique | Également appelé ID de nœud de cache. C’est une valeur arbitraire. Généralement, une adresse IP que les serveurs Edge CDN renvoient pour aider les CDN à identifier en interne quel serveur a traité une requête particulière. ‘’ (chaîne vide) : provient des clients Radar qui ne prennent pas en charge la détection UNI. 0 : l’agent utilisateur ne prend pas en charge les fonctionnalités nécessaires à la détection UNI. 1 : le client a rencontré une erreur lors de la détection UNI, telle qu’une erreur HTTP 404 ou une autre réponse infructueuse. 2 : la détection UNI a été tentée mais a entraîné une erreur. |
| ID du fournisseur | ID interne de la plate-forme mesurée. |
| Type de sonde | Le type de sonde mesuré (par exemple, 1 : temps de connexion HTTP, 0 : temps de réponse HTTP, 14 : débit HTTP, etc.). Pour indiquer que le service est disponible, utilisez les informations renvoyées avec succès dans le délai autorisé. |
| Code de réponse | Résultat de la mesure. Par exemple, 0 : succès, 1 : délai d’attente, 4 : erreur. Pour les calculs de disponibilité, le pourcentage de mesures est pris avec une réponse 0 (succès) par rapport au nombre total de mesures (total, quelle que soit la réponse). Pour les autres types de sondes (RTT et débit), le filtre ne doit prendre en compte que les points de données RTT avec un code de succès 0 lors du calcul des statistiques sur le RTT. Idem pour le débit. |
| Valeur de mesure | La valeur de mesure enregistrée, dont la signification varie selon le type de sonde. Elle représente les mesures de disponibilité (1)/temps de réponse (0) en millisecondes et le débit (14) en kbit/s. |
| Marché du résolveur | Le marché du résolveur DNS qui a traité la requête. Généralement le continent où se trouve le résolveur DNS, où, 0 : Inconnu (XX), 1 : Amérique du Nord (NA), 5 : Afrique (AF), 3 : Europe (EU), 4 : Asie (AS), 2 : Océanie (OC), 6 : Amérique du Sud (SA). |
| Pays du résolveur | Le pays du résolveur DNS qui a traité la requête. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/countries.json.gz |
| Région du résolveur | La région du résolveur DNS qui a traité la requête. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/regions.json.gz Remarque : Toutes les régions du monde n’ont pas de régions définies. |
| État du résolveur | L’état du résolveur DNS qui a traité la requête. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/states.json.gz Remarque : Tous les pays du monde n’ont pas d’états définis. |
| Ville du résolveur | La ville du résolveur DNS qui a traité la requête. La ville du résolveur est ajoutée en recherchant une adresse IP de résolveur. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/cities.json.gz |
| ASN du résolveur | Le numéro de système autonome (ASN) du résolveur DNS qui a traité la requête. Généralement l’ASN qui possède le résolveur DNS. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/asns.json.gz |
| IP du résolveur | L’adresse IP du résolveur DNS à partir duquel notre infrastructure a reçu la requête DNS. |
| Marché du client | Le marché de l’utilisateur final qui a généré cette mesure. Généralement le continent où se trouve l’adresse IP du client ; où, 0 : Inconnu (XX), 1 : Amérique du Nord (NA), 5 : Afrique (AF), 3 : Europe (EU), 4 : Asie (AS), 2 : Océanie (OC), 6 : Amérique du Sud (SA). |
| Pays du client | Le pays de l’utilisateur final qui a généré cette mesure. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/countries.json.gz |
| Région du client | La région de l’utilisateur final qui a généré cette mesure. Généralement la région géographique où se trouve l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/regions.json.gz Remarque : Toutes les régions du monde n’ont pas de régions définies. |
| État du client | L’état de l’utilisateur final qui a généré cette mesure. Généralement l’état où se trouve l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/states.json.gz Remarque : Tous les pays du monde n’ont pas d’états définis. |
| Ville du client | La ville de l’utilisateur final qui a généré cette mesure. Généralement la ville où se trouve l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/cities.json.gz |
| ASN du client | Le numéro de système autonome (ASN) de l’utilisateur final qui a généré cette mesure. Généralement l’ASN qui contient l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/asns.json.gz |
| IP du client | L’adresse IP de l’utilisateur final qui a généré cette mesure. |
| Hôte référent MD5 | Les informations de référent (protocole, hôte et chemin) proviennent de l’en-tête Referer de la requête HTTP vers Radar. L’hôte référent est haché en MD5. |
| Agent utilisateur | Il s’agit de la chaîne d’agent utilisateur de la page du navigateur qui héberge la balise. Par exemple, si vous utilisez Chrome et naviguez sur une page avec la balise Radar, les mesures Radar en arrière-plan enregistrent l’agent utilisateur de votre navigateur Chrome. Les mesures incluent le navigateur Chrome, la version de Chrome, des informations sur le système d’exploitation sur lequel Chrome s’exécute, etc. |
| Temps de recherche DNS (facultatif) | Avec l’API Resource Timing, la différence entre la fin de la recherche de domaine et le début de la recherche de domaine est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme domainLookupEnd - domainLookupStart. |
| Temps de connexion TCP (facultatif) | Avec l’API Resource Timing, la différence entre la fin de la connexion et le début de la connexion est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme connectEnd - connectStart. |
| Temps de connexion sécurisée (facultatif) | Avec l’API Resource Timing, la différence entre la fin de la connexion et le début de la connexion sécurisée est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme connectEnd - secureConnectionStart. |
| Latence (facultatif) | Avec l’API Resource Timing, la différence entre le début de la réponse et le début de la requête est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de début de la réponse est supérieure à l’heure de début de la requête. Elle est calculée comme responseStart - requestStart |
| Temps de téléchargement (facultatif) | Avec l’API Resource Timing, la différence entre la fin de la réponse et le début de la réponse est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme responseEnd - responseStart. |
| Profil client | Ce champ permet d’identifier si les données proviennent d’applications mobiles ou de navigateurs. Il nous permet également de différencier les applications iOS, Android et les navigateurs. Un nombre est utilisé pour identifier chaque profil client. Les valeurs de ce champ sont : null, 0, 1, 2, 3, 4. Où, null : implique généralement un client Radar plus ancien qui ne prend pas en charge l’envoi de la valeur client_profile. 0 : Navigateur ; 1 : iOS - Radar runner pour application iOS écrite en Swift ; 2 : Android ; 3 : Navigateur sur version mobile du site Web ; 4 : iOS - Radar Runner pour application iOS écrite en Objective-C. |
| Version du profil client | La version du profil client nous indique quelle version du code Radar Runner (pour iOS) ou du SDK AndroidRadar (pour Android) a été utilisée dans l’application mobile. Ce champ est destiné à un usage interne uniquement. |
| Catégorie d’appareil | Tous les appareils sont classés dans l’une des catégories suivantes : Smartphone, Tablette, PC, Smart TV et Autre. « Autre » est utilisé comme valeur par défaut si l’analyseur est incapable de déterminer la valeur pour l’un des champs. |
| Appareil | Le type d’appareil utilisé par l’utilisateur, par exemple un Apple iPhone. La chaîne d’agent utilisateur le détecte à partir du navigateur exécuté sur la page qui héberge la balise Radar. |
| Navigateur | Le type de navigateur utilisé par l’utilisateur, par exemple Mobile Safari UI/WKWebView 0.0.0. La chaîne d’agent utilisateur le détecte à partir du navigateur exécuté sur la page qui héberge la balise Radar. |
| Système d’exploitation | Le système d’exploitation utilisé. Par exemple, iOS 11.0.3. La chaîne d’agent utilisateur le détecte à partir du navigateur exécuté sur la page qui héberge la balise Radar. |
| IP du client de rapport | Cette adresse IP est l’adresse IP publique masquée /48 de l’utilisateur effectuant la mesure. Il peut s’agir d’IPv4 ou d’IPv6 (lorsque pris en charge). |
Descriptions des journaux de synchronisation de la navigation
Données de synchronisation de la navigation
Les données de synchronisation de la navigation fournissent des informations sur les différentes parties du processus de chargement d’une page Web.
Ces données varient en fonction de l’emplacement de l’utilisateur final, des problèmes de réseau, des modifications apportées par le fournisseur, etc. Les clients peuvent utiliser les données de synchronisation de la navigation pour optimiser l’expérience de l’utilisateur final lors du chargement de la page Web surveillée.
Des mesures peuvent être prises pour chaque session Radar (si activée). Chaque session est associée à un numéro d’identification qui permet de suivre toutes les mesures d’une session. Ces mesures sont partagées avec les clients sous forme de journaux de synchronisation de la navigation via NEM.
Voici un exemple des données de synchronisation de la navigation au format de fichier TSV.
Voici les en-têtes de colonne et les descriptions des journaux de synchronisation de la navigation. Les champs apparaissent dans l’ordre suivant dans les fichiers de sortie :
| Journal | Description |
|---|---|
| Horodatage | Il s’agit de l’heure UTC de la requête au format AAAA-MM-JJTHH:MI:SSZ. La valeur réelle (à la seconde près) dans les tables de journaux est arrondie à l’heure la plus proche (2018-03-30T23:00:00Z) ou au jour le plus proche (2018-03-30T00:00:00Z) dans les tables horaires/journalières, respectivement. Il est toujours en UTC dans tous les jeux de données. |
| Code de réponse | Résultat de la mesure. Par exemple, 0 : succès, 1 : délai d’attente, 4 : erreur. Pour les calculs de disponibilité, le pourcentage de mesures est pris avec une réponse 0 (succès) par rapport au nombre total de mesures (total). Pour les autres types de sondes (RTT et débit), le filtre ne doit prendre en compte que les points de données RTT avec un code de succès 0 lors du calcul des statistiques sur le RTT. Idem pour le débit. |
| Marché du résolveur | Le marché du résolveur DNS qui a traité la requête. Généralement le continent où se trouve le résolveur DNS, où, 0 : Inconnu (XX), 1 : Amérique du Nord (NA), 5 : Afrique (AF), 3 : Europe (EU), 4 : Asie (AS), 2 : Océanie (OC), 6 : Amérique du Sud (SA). |
| Pays du résolveur | Le pays du résolveur DNS qui a traité la requête. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/countries.json.gz |
| Région du résolveur | La région du résolveur DNS qui a traité la requête. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/regions.json.gz. Toutes les régions du monde n’ont pas de régions définies. |
| État du résolveur | L’état du résolveur DNS qui a traité la requête. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/states.json.gz. Toutes les régions du monde n’ont pas d’états définis. |
| ASN du résolveur | Le numéro de système autonome (ASN) du résolveur DNS qui a traité la requête. Généralement l’ASN qui possède le résolveur DNS. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/asns.json.gz |
| IP du résolveur | L’adresse IP du résolveur DNS à partir duquel notre infrastructure a reçu la requête DNS. |
| Marché du client | Le marché de l’utilisateur final qui a généré cette mesure. Généralement le continent où se trouve l’adresse IP du client ; où, 0 : Inconnu (XX), 1 : Amérique du Nord (NA), 5 : Afrique (AF), 3 : Europe (EU), 4 : Asie (AS), 2 : Océanie (OC), 6 : Amérique du Sud (SA). |
| Pays du client | Le pays de l’utilisateur final qui a généré cette mesure. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/countries.json.gz |
| Région du client | La région de l’utilisateur final qui a généré cette mesure. Généralement la région géographique où se trouve l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/regions.json.gz. Toutes les régions du monde n’ont pas de régions définies. |
| État du client | L’état de l’utilisateur final qui a généré cette mesure. Généralement l’état où se trouve l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/states.json.gz. Toutes les régions du monde n’ont pas d’états définis. |
| ASN du client | Le numéro de système autonome (ASN) de l’utilisateur final qui a généré cette mesure. Généralement l’ASN qui possède l’adresse IP du client. Les ID peuvent être mappés aux noms à l’adresse https://community-radar.citrix.com/ref/asns.json.gz |
| IP du client | L’adresse IP de l’utilisateur final qui a généré la mesure. |
| Hôte référent | Les informations de référent (protocole, hôte et chemin) proviennent de l’en-tête Referer de la requête HTTP vers Radar. |
| Protocole référent | Les informations de référent (protocole, hôte et chemin) proviennent de l’en-tête Referer de la requête HTTP vers Radar. |
| Chemin référent | Les informations de référent (protocole, hôte et chemin) proviennent de l’en-tête Referer de la requête HTTP vers Radar. |
| Catégorie d’appareil | Tous les appareils sont classés dans l’une des catégories suivantes : Smartphone, Tablette, PC, Smart TV et Autre. « Autre » est utilisé comme valeur par défaut si l’analyseur est incapable de déterminer la valeur pour l’un des champs. |
| Appareil | Le type d’appareil utilisé par l’utilisateur, par exemple un Apple iPhone. La chaîne d’agent utilisateur le détecte à partir du navigateur exécuté sur la page qui héberge la balise Radar. |
| Navigateur | Le type de navigateur utilisé par l’utilisateur, par exemple Mobile Safari UI/WKWebView 0.0.0. La chaîne d’agent utilisateur le détecte à partir du navigateur exécuté sur la page qui héberge la balise Radar. |
| Système d’exploitation | Le système d’exploitation utilisé, par exemple iOS 11.0.3. La chaîne d’agent utilisateur le détecte à partir du navigateur exécuté sur la page qui héberge la balise Radar. |
| Temps de recherche DNS | Avec l’API Resource Timing, la différence entre la fin de la recherche de domaine et le début de la recherche de domaine est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme domainLookupEnd - domainLookupStart. |
| Temps de connexion TCP | Avec l’API Resource Timing, la différence entre la fin de la connexion et le début de la connexion est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme connectEnd - connectStart. |
| Temps de connexion sécurisée | Avec l’API Resource Timing, la différence entre la fin de la connexion et le début de la connexion sécurisée est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme connectEnd - secureConnectionStart. |
| Événement de chargement | Il s’agit de la durée ou du temps nécessaire pour passer du début à la fin de l’événement de chargement. Il est calculé comme LoadEventEnd - LoadEventStart, lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. |
| Redirection | Il s’agit de la durée ou du temps nécessaire pour passer du début de la navigation au début de la récupération. Il est calculé comme FetchStart - NavigationStart, lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. |
| Chargement total de la page | Il s’agit de la durée ou du temps nécessaire pour passer du début de la navigation à la fin de l’événement de chargement de la page. Il est calculé comme Load Event End - Navigation Start lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. |
| DOM | La durée ou le temps nécessaire pour passer du chargement du DOM à la complétion du DOM. Il est calculé comme DomComplete - DomLoading lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. |
| Latence | Avec l’API Resource Timing, la différence entre le début de la réponse et le début de la requête est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de début de la réponse est supérieure à l’heure de début de la requête. Elle est calculée comme responseStart - requestStart |
| Temps de téléchargement | Avec l’API Resource Timing, la différence entre la fin de la réponse et le début de la réponse est calculée. Elle est calculée lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. Elle est calculée comme responseEnd - responseStart. |
| DOM interactif | La durée ou le temps nécessaire pour passer du début de la navigation au DOM interactif. Il est calculé comme DomInteractive - NavigationStart lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. |
| Début du rendu | La durée ou le temps nécessaire pour passer du début de la navigation au début du rendu. Il est calculé comme startRender - NavigationStart lorsque les deux valeurs ne sont pas nulles et que l’heure de fin est supérieure à l’heure de début. |
Journaux Openmix et HTTP Openmix
Les journaux Openmix et HTTP Openmix permettent aux clients d’utiliser des mesures en temps réel pour surveiller le comportement de leurs applications Openmix. Ils peuvent utiliser ces données pour identifier les domaines d’amélioration ou pour vérifier les performances attendues de leurs applications.
- Ces journaux fournissent des mesures en temps réel prises pour les clients Openmix.
- Le format de fichier recommandé pour ces journaux est JSON, mais ils sont également disponibles au format TSV.
- Voici des exemples de données de partage de journaux Openmix et HTTP Openmix au format de fichier TSV.
Descriptions des journaux Openmix
| Journal | Description |
|---|---|
| Horodatage | Il s’agit de l’heure UTC de la requête au format AAAA-MM-JJTHH:MI:SSZ. La valeur réelle (à la seconde près) dans les tables de journaux est arrondie à l’heure la plus proche (2018-03-30T23:00:00Z) ou au jour le plus proche (2018-03-30T00:00:00Z) dans les tables horaires/journalières, respectivement. L’horodatage est toujours en UTC dans tous les jeux de données. |
| ID de zone du propriétaire de l’application | L’ID de zone du propriétaire de l’application traitant la requête. Cette valeur est toujours égale à 1. |
| ID client du propriétaire de l’application | L’ID client du propriétaire de l’application qui traite la requête. Pour les requêtes HTTP, codez cet ID dans le chemin de la requête et utilisez-le pour rechercher l’application à exécuter. |
| ID de l’application | L’ID de l’application dans le compte du client qui traite la requête. Cet ID est également codé dans le chemin de la requête HTTP. Les ID d’application commencent à 1 et ne sont uniques qu’au client. Vous devez qualifier entièrement les requêtes pour un ID d’application spécifique en interrogeant sur l’appOwnerCustomerId. |
| Version de l’application | La version de l’application qui a traité le compte. Chaque fois qu’une application est mise à jour via le portail ou l’API, la version est incrémentée. La version qui était en cours d’exécution au moment de la requête est enregistrée. Ces informations peuvent être utilisées pour séparer la logique versionnée au fil du temps à mesure que les applications sont mises à jour. Les hôtes du réseau reçoivent généralement les mises à jour dans un délai similaire, mais presque jamais au même moment précis. Il est probable que des décisions qui se chevauchent dans le temps utilisent différentes versions d’une application pendant le processus de mise à jour. |
| Nom de l’application | Le nom de l’application qui a traité le compte. |
| Marché | Le marché de l’utilisateur final qui a généré cette mesure. |
| Pays | Le pays de l’utilisateur final qui a généré cette mesure. |
| Région | La région de l’utilisateur final qui a généré cette mesure. |
| État | L’état de l’utilisateur final qui a généré cette mesure. |
| ID ASN | Le numéro de système autonome (ASN) de l’utilisateur final qui a généré cette mesure. Généralement le numéro de système autonome qui possède l’adresse IP du client. |
| Nom de l’ASN | Le nom de l’ASN de l’utilisateur final qui a généré la mesure. |
| IP effective | L’adresse IP effective est l’adresse IP utilisée pour traiter la requête. C’est l’adresse IP spécifiée dans la chaîne de requête qui remplace l’adresse IP de la requête (par rapport à l’ID du résolveur/ECS/EDNS pour le flux DNS). C’est l’adresse que le système considère comme la cible lors du traitement des informations. Cette adresse IP est soit l’adresse IP du résolveur demandeur, soit l’adresse IP ECS du client si EDNS ECS est pris en charge. Ainsi, toutes les données de performance de la sonde, les informations géographiques, etc., transmises à la logique de l’application sont basées sur cette adresse IP. |
| Marché du résolveur | Le marché du résolveur DNS qui a traité la requête. |
| Pays du résolveur | Le pays du résolveur DNS qui a traité la requête. |
| Région du résolveur | La région du résolveur DNS qui a traité la requête. |
| État du résolveur | L’état du résolveur DNS qui a traité la requête. |
| ID ASN du résolveur | Le numéro de système autonome (ASN) du résolveur DNS qui a traité la requête. Généralement le numéro de système autonome qui possède le résolveur DNS. |
| Nom de l’ASN du résolveur | Le nom de l’ASN du résolveur qui a traité la requête. |
| IP du résolveur | L’adresse IP du résolveur DNS à partir duquel notre infrastructure a reçu la requête DNS. |
| Nom du fournisseur de décision | Alias de la plate-forme sélectionnée par une application. |
| Code de raison | Code de raison défini dans l’application décrivant la raison de la décision. |
| Journal de raison | Ce journal est une sortie définie par le client de l’application Openmix. C’est un champ de chaîne facultatif qui permet aux clients d’enregistrer des informations sur les décisions de leur application Openmix. |
| Mode de secours | Ce mode indique si l’application était en mode de secours lorsqu’elle a traité la requête. Le secours se produit lorsque quelque chose a échoué lors de la préparation de la requête pour l’exécution. |
| EDNS utilisé | Vrai si l’application utilise une extension de sous-réseau client EDNS. |
| TTL | Le TTL (Time To Live) qui a été renvoyé. |
| Réponse | Le CNAME renvoyé par la requête. |
| Résultat | La valeur de ce champ est toujours 1. |
| Contexte | Il s’agit du résumé des données Radar qui étaient disponibles pour Openmix lorsque la requête a été traitée. Openmix résout les données Radar par rapport aux valeurs effectives pour chaque requête, de sorte que deux clients effectuant des requêtes en même temps peuvent avoir des chaînes de contexte différentes. |
Descriptions des journaux de l’API HTTP Openmix
| Journal | Description |
|---|---|
| Horodatage | Il s’agit de l’heure UTC de la requête au format AAAA-MM-JJTHH:MI:SSZ. La valeur réelle (à la seconde près) dans les tables de journaux est arrondie à l’heure la plus proche (2018-03-30T23:00:00Z) ou au jour le plus proche (2018-03-30T00:00:00Z) dans les tables horaires/journalières, respectivement. L’horodatage est toujours en UTC dans tous les jeux de données. |
| ID de zone du propriétaire de l’application | L’ID de zone du propriétaire de l’application traitant la requête. Cette valeur est toujours égale à 1. |
| ID client du propriétaire de l’application | L’ID client du propriétaire de l’application qui traite la requête. Pour les requêtes HTTP, codez cet ID dans le chemin de la requête et utilisez-le pour rechercher l’application à exécuter. |
| ID de l’application | L’ID de l’application dans le compte du client qui traite la requête. Cet ID est également codé dans le chemin de la requête HTTP. Les ID d’application commencent à 1 et ne sont uniques qu’au client. Vous devez qualifier entièrement les requêtes pour un ID d’application spécifique en interrogeant sur l’appOwnerCustomerId. |
| Version de l’application | La version de l’application qui a traité le compte. Chaque fois qu’une application est mise à jour via le portail ou l’API, la version est incrémentée. La version qui était en cours d’exécution au moment de la requête est enregistrée. Ces informations peuvent être utilisées pour séparer la logique versionnée au fil du temps à mesure que les applications sont mises à jour. Les hôtes du réseau reçoivent généralement les mises à jour dans un délai similaire, mais presque jamais au même moment précis. Il est probable que des décisions qui se chevauchent dans le temps utilisent différentes versions d’une application pendant le processus de mise à jour. |
| Nom de l’application | Le nom de l’application qui a traité le compte. |
| Marché | Le marché de l’utilisateur final qui a généré cette mesure. |
| Pays | Le pays de l’utilisateur final qui a généré cette mesure. |
| Région | La région de l’utilisateur final qui a généré cette mesure. |
| État | L’état de l’utilisateur final qui a généré cette mesure. |
| ID ASN | L’ID du numéro de système autonome (ASN) de l’utilisateur final qui a généré cette mesure, c’est-à-dire le numéro d’ID de réseau associé au nom de l’ASN. |
| Nom de l’ASN | Le nom de l’ASN de l’utilisateur final qui a généré la mesure. |
| IP effective | L’adresse IP effective est l’adresse IP utilisée pour traiter la requête. C’est l’adresse IP spécifiée dans la chaîne de requête qui remplace l’adresse IP de la requête (par rapport à l’ID du résolveur/ECS/EDNS pour le flux DNS). C’est l’adresse que le système considère comme la cible lors du traitement des informations. Cette adresse IP est soit l’adresse IP du résolveur demandeur, soit l’adresse IP ECS du client si EDNS ECS est pris en charge. Toutes les données de performance de la sonde, les informations géographiques, etc., transmises à la logique de l’application sont basées sur cette adresse IP. |
| Nom du fournisseur de décision | Alias de la plate-forme sélectionnée par une application. |
| Code de raison | Code de raison défini dans l’application décrivant la raison de la décision. |
| Journal de raison | Ce journal est une sortie définie par le client de l’application Openmix. C’est un champ de chaîne facultatif qui permet aux clients d’enregistrer des informations sur les décisions de leur application Openmix. |
| Mode de secours | Ce mode indique si l’application était en mode de secours lorsqu’elle a traité la requête. Le secours se produit lorsque quelque chose a échoué lors de la préparation de la requête pour l’exécution. |
| Code de réponse | Résultat de la mesure. Par exemple, 0 : succès, 1 : délai d’attente, 4 : erreur. Pour les calculs de disponibilité, le pourcentage de mesures est pris avec une réponse 0 (succès) par rapport au nombre total de mesures (quelle que soit la réponse). Pour les autres types de sondes (RTT et débit), le filtre ne doit prendre en compte que les points de données RTT avec un code de succès 0 lors du calcul des statistiques sur le RTT. Idem pour le débit. |
| Méthode HTTP | La méthode HTTP (GET/POST/OPTIONS/etc) est liée à la requête qui a été faite au serveur HTTP Openmix à partir d’un service client. Ensemble, ces méthodes constituent des portions de l’URL entrante et des réponses HTTP sortantes. |
| URI | Il s’agit du chemin de la requête. Si les clients n’obtiennent pas le comportement souhaité, cela peut être dû à une requête mal structurée. Les journaux montrent ce que nos serveurs reçoivent (protocole, hôte et chemin). Les informations de référent (protocole, hôte et chemin) proviennent de l’en-tête Referer de la requête HTTP vers Radar. Pour HTTP OPX, l’intégralité du référent (protocole, hôte et chemin) est incluse dans une chaîne étiquetée Referer. |
| Agent utilisateur | Il s’agit de la chaîne d’agent utilisateur de la page du navigateur qui héberge la balise. Par exemple, si vous utilisez Chrome et naviguez sur une page avec la balise Radar, les mesures Radar en arrière-plan enregistrent l’agent utilisateur de votre navigateur Chrome. Les mesures incluent le navigateur Chrome, la version de Chrome, des informations sur le système d’exploitation sur lequel Chrome s’exécute, etc. |
| Contexte | Il s’agit du résumé des données Radar qui étaient disponibles pour Openmix lorsque la requête a été traitée. Openmix résout les données Radar par rapport aux valeurs effectives pour chaque requête, de sorte que deux clients effectuant des requêtes en même temps peuvent avoir des chaînes de contexte différentes. |
Rapports personnalisés pour les organisations tierces
Les clients peuvent travailler avec NetScaler® pour obtenir des rapports personnalisés basés sur les données Radar collectées par NetScaler. NetScaler peut générer des rapports à exécuter selon un calendrier. Les rapports sont disponibles sous forme de fichiers de données, généralement au format TSV.
FAQ
Radar
À quelle fréquence les fichiers sont-ils transférés vers S3 et GCS ?
La fréquence des dépôts de fichiers est d’une fois par minute pour Radar et quotidienne pour les rapports.
Où les rapports sont-ils stockés ?
S3 Hérité (Emplacement 1) :
s3://public-radar/[customer name]/
S3 (Emplacement 2) :
s3://cedexis-netscope/[customer id]/
GCS (Emplacement 3) :
gs://cedexis-netscope-[customer id]/
Comment obtenir les informations d’identification d’accès S3 si vous ne les avez pas déjà ?
Le portail fournit une clé « d’accès » et une clé « secrète ». Utilisez ces clés avec « s3cmd », « awscli » ou d’autres outils pour accéder à S3. Pour Google Storage, le portail télécharge un fichier avec les informations d’identification d’accès à utiliser avec l’outil « gsutil ».
Comment utiliser les clés d’accès et secrètes avec s3cmd pour télécharger des journaux et des rapports depuis le compartiment S3 ?
Vous devrez d’abord télécharger et installer s3cmd depuis https://s3tools.org/download, et vous référer à https://s3tools.org/usage pour l’utilisation, les options et les commandes. Exécutez ensuite la commande suivante :
s3cmd --access_key=[access key] --secret_key=[secret key] ls s3://cedexis-netscope/<customer id>/radar/
<!--NeedCopy-->
Pour télécharger les fichiers, exécutez la commande suivante :
s3cmd --access_key=[access_key] --secret_key=[secret_key] get s3://cedexis-netscope/<customer id>/radar/[the_filename_to_download] [the_name_of_the_local_file]
<!--NeedCopy-->
Comment utiliser la configuration s3cmd pour lister les fichiers dans le compartiment S3
La première étape consiste à installer s3cmd. Vous pouvez l’installer depuis http://s3tools.org/download
Pour configurer s3cmd, exécutez la commande suivante :
s3cmd ls s3://cedexis-netscope/[customer id]/
<!--NeedCopy-->
Si vous utilisez déjà s3cmd avec un autre jeu de clés d’accès et secrètes, suivez ces étapes :
Si vous utilisez déjà s3cmd, faites une copie de la configuration par défaut, à ~/.s3cfg. Par exemple, faites une copie et nommez-la ~/.s3cfg_netscope. Remplacez les entrées des clés d’accès et secrètes dans ~/.s3cfg_netscope par celles que nous fournissons.
Utilisez la nouvelle configuration au lieu de celle par défaut (de votre entreprise) pour accéder au compartiment S3 avec la commande suivante :
s3cmd -c ~/.s3cfg_netscope ls s3://cedexis-netscope/[customer id]/
<!--NeedCopy-->
La principale différence est que vous devez inclure un -c et spécifier l’emplacement du fichier de configuration contenant les clés d’accès et secrètes fournies par NetScaler.
Si vous souhaitez basculer entre des jeux de clés, intégrez-les dans un fichier. Référez-vous au fichier avec l’option -c pour spécifier la paire de clés que vous utilisez.
REMARQUE : Le paramètre
-cindique l’emplacement du fichier de configuration, qui contient les clés d’accès et secrètes.
Comment utiliser le fichier de clé avec gsutil ou gcloud pour télécharger des fichiers journaux
Une fois que vous avez téléchargé le fichier de clé JSON du compte de service Google, vous pouvez l’utiliser pour authentifier les informations d’identification de votre compte Google, afficher ou télécharger vos fichiers journaux. Par exemple, voici une façon de le faire en utilisant les utilitaires de ligne de commande Google gcloud et gsutil :
Étape 1 : Activer le fichier de clé
Les commandes d’authentification gcloud auth activate- ou gsutil config -e sont requises pour authentifier le fichier de clé afin d’exécuter les commandes gcloud ou gsutil.
Pour gcloud :
Exécutez la commande suivante en utilisant le fichier de clé téléchargé :
gcloud auth activate-service-account --key-file [downloaded config file]
<!--NeedCopy-->
Ou
gcloud auth activate-service-account --key-file=[path and file name of key file]
<!--NeedCopy-->
Pour gsutil :
Exécutez la commande suivante en utilisant le fichier de configuration téléchargé :
gsutil config -e
<!--NeedCopy-->
Étape 2 : Lister les fichiers dans le compartiment GCS (Google Cloud Storage)
Une fois que vous avez activé le fichier de clé de compte de service comme décrit à l’étape précédente, utilisez la commande suivante pour lister les fichiers dans le compartiment GCS :
gsutil ls gs://cedexis-netscope-<customer id>
<!--NeedCopy-->
Étape 3 (si nécessaire) : Restaurer les informations d’identification d’origine (ou basculer entre les comptes)
Vous pouvez basculer entre le compte NetScaler ITM et d’autres informations d’identification Google Cloud que vous avez authentifiées en procédant comme suit.
Tout d’abord, exécutez la commande suivante pour lister tous vos comptes :
gcloud auth list
<!--NeedCopy-->
Utilisez ensuite la commande suivante pour basculer vers un autre compte :
gcloud config set account [email of the account to switch to as shown in gcloud auth list]
<!--NeedCopy-->
Vous pouvez basculer entre les comptes en utilisant la même commande, en remplaçant l’e-mail par l’e-mail du compte vers lequel vous souhaitez basculer.
À quoi ressemble le nom du fichier ?
Quotidien Hérité :
Les noms des fichiers de partage de journaux quotidiens Radar ont cette structure :
<prefix><date: YYYY-MM-DD>.<customer_id>.part<uniq_id>.kr.txt.gz
Par exemple Cedexis_Daily-2017-11-07.21222.part-cc901e1dd55eal4e.kr.txt.gz (exemple non standard)
Temps réel Hérité :
Les noms des fichiers de partage de journaux Radar en temps réel ont cette structure :
<prefix><customer_id>-YYYY-MM-DDTHH:MM<uniq_id>.txt.gz
Par exemple Cedexis_3-32291-2017-11-08T20:56-cc907e8fd71eaf4e.txt.gz
Format Netscope NEM :
Le format Netscope NEM pour les fichiers de partage de journaux quotidiens et en temps réel a cette structure :
<freq><log_type><prefix><id_type><id><iso_dt><uniq_id>.<line_format>.gz
Où,
-
freq:"daily" | "rt" | "hr" -
log_type:"radar" | "opx" | "hopx" -
prefix:log_share.prefix -
id_type:"customer" | "provider" | "asn" -
id:log_share.match_id -
iso_dt:iso 8601 Date_time "YYYYMMDDTHHMMSSZ" -
uniq_id:hash(UUID) -
line_format:"tsv" | "json"
Par exemple rt-radar-TestRadar1-provider-20363-20171209183034Z-cc907e8fd71eaf4e.tsv.gz
Quel est le format du fichier de sortie ?
Pour Radar, le format du fichier de sortie est TSV (valeurs séparées par des tabulations), compressé en gzip.
Openmix et API HTTP Openmix
À quelle fréquence les fichiers sont-ils transférés vers S3 ?
La fréquence des dépôts de fichiers est d’une fois par minute pour Openmix et HTTP Openmix.
Que faire si vous ne parvenez pas à voir l’option de configuration du partage de journaux en temps réel Openmix et de l’API HTTP Openmix ?
Votre responsable de compte peut activer le rôle requis pour que vous puissiez configurer et activer le partage de journaux en temps réel Openmix et de l’API HTTP Openmix.
Comment activer le partage de journaux en temps réel Openmix et de l’API HTTP Openmix et accéder aux fichiers ?
Une fois le rôle activé sur votre compte, vous verrez l’icône Gérer les journaux. Cliquez dessus pour ouvrir la boîte de dialogue Journaux où vous pouvez accéder aux paramètres de configuration des journaux Openmix. Ces paramètres sont essentiellement tout ce dont vous avez besoin pour activer le partage de journaux en temps réel Openmix et HTTP Openmix et accéder aux fichiers.
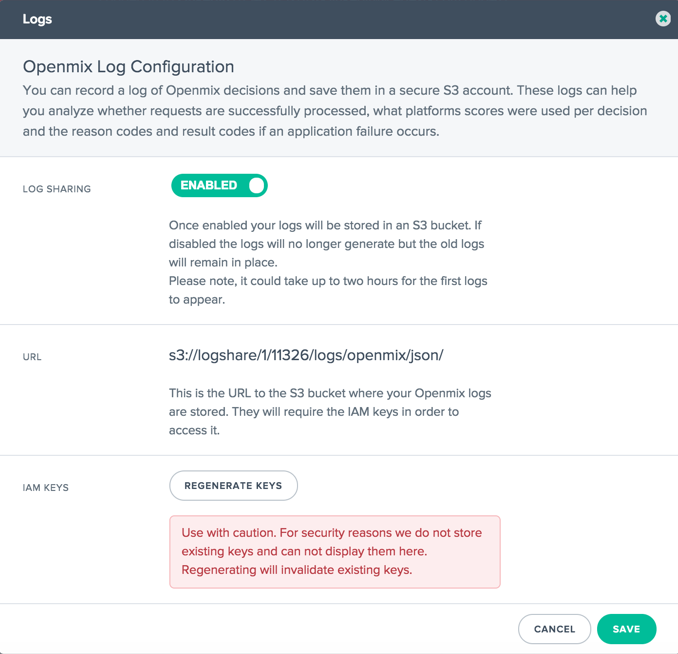
Quel est le processus back-end ?
L’activation du partage de journaux Openmix active également le partage de journaux de l’API HTTP Openmix. Les services de partage de journaux Openmix et de l’API HTTP Openmix doivent commencer à générer des journaux pour le client dans les 10 minutes.
Où les rapports Openmix et HTTP Openmix sont-ils stockés ?
S3 Hérité (Emplacement 1) :
s3://logshare/[zone ID]/[customer ID]/logs/openmix/json/[YYYY]/[MM]/[DD]/[HH]/.
S3 (Emplacement 2) :
s3://cedexis-netscope/[customer id]/
GCS (Emplacement 3) :
gs://cedexis-netscope-[customer id]/
À quoi ressemble le nom du fichier ?
La structure du nom de fichier pour Openmix et HTTP Openmix ressemble généralement à ceci :
Temps réel Hérité :
[zone ID, 1][customerID]-openmix-json[YYYY][MM][DD][HH][mm][ss]Z-m1-w9-c0.gz
Format Netscope NEM :
Le format Netscope NEM pour les fichiers de partage de journaux quotidiens et en temps réel a cette structure :
<freq><log_type><prefix><id_type><id><iso_dt><uniq_id>.<line_format>.gz
Où,
-
freq:"daily" | "rt" | "hr" -
log_type:"radar" | "opx" | "hopx" -
prefix:log_share.prefix -
id_type:"customer" | "provider" | "asn" -
idv:log_share.match_id -
iso_dt:iso 8601 Date_time "YYYYMMDDTHHMMSSZ" -
uniq_id:hash(UUID) -
line_format:"tsv" | "json"
Par exemple hr-opx-TestOpenmix1-provider-20363-20171209183034Z-cc907e8fd71eaf4e.tsv.gz
Quel est le format du fichier de sortie ?
Le format de fichier pour Openmix et une API HTTP Openmix est JSON (compressé en gzip).
Dans cet article
- Présentation
- Partage et livraison des journaux
- Navigation
- Plates-formes
- Journaux Radar
- Journaux de synchronisation de la navigation
- Journaux Openmix
- Livraison de services cloud
- Descriptions des journaux Radar et rapports pour les fournisseurs de services et les entreprises
- Descriptions des journaux de synchronisation de la navigation
- Journaux Openmix et HTTP Openmix
- Descriptions des journaux Openmix
- Descriptions des journaux de l’API HTTP Openmix
- Rapports personnalisés pour les organisations tierces
- FAQ