Analyse de l’infrastructure
Un objectif clé pour les administrateurs réseau est de surveiller les instances NetScaler. Les instances ADC offrent des informations intéressantes sur l’utilisation et les performances des applications et des bureaux accessibles par leur intermédiaire. Les administrateurs doivent surveiller l’instance ADC et analyser les flux d’applications traités par chaque instance ADC. Ils doivent être en mesure de remédier à tout problème probable de configuration, d’installation, de connectivité, de certificats et autres qui pourraient avoir un impact sur l’utilisation ou les performances des applications. Par exemple, un changement soudain dans le modèle de trafic d’application peut être dû à une modification de la configuration SSL, comme la désactivation d’un protocole SSL. Les administrateurs doivent être en mesure d’identifier rapidement la corrélation entre ces points de données pour garantir les éléments suivants :
-
La disponibilité des applications est dans un état optimal.
-
Il n’y a pas de problèmes de consommation de ressources, de matériel, de capacité ou de modification de configuration.
-
Il n’y a pas d’inventaires inutilisés.
-
Il n’y a pas de certificats expirés.
La fonctionnalité d’analyse de l’infrastructure simplifie le processus d’analyse des données en corrélant plusieurs sources de données et en les quantifiant en un score mesurable qui définit l’état de santé d’une instance. Grâce à cette fonctionnalité, les administrateurs disposent d’un point de contact unique pour comprendre s’il y a un problème, l’origine du problème et les solutions probables qu’ils peuvent mettre en œuvre.
Analyse de l’infrastructure
La fonctionnalité d’analyse de l’infrastructure de NetScaler Application Delivery Management (ADM) rassemble toutes les données collectées à partir des instances NetScaler et les quantifie en un score d’instance qui définit l’état de santé des instances. Le score d’instance est résumé dans une vue tabulaire ou sous forme de visualisation en cercle. La fonctionnalité d’analyse de l’infrastructure vous aide à visualiser les facteurs qui ont entraîné ou pourraient entraîner un problème sur les instances. Cette visualisation vous aide également à déterminer les actions à effectuer pour prévenir le problème et sa récurrence.
Score d’instance
Le score d’instance indique l’état de santé d’une instance ADC. Un score de 100 signifie une instance parfaitement saine sans aucun problème. Le score d’instance capture différents niveaux de problèmes potentiels sur l’instance. Il s’agit d’une mesure quantifiable de l’état de santé de l’instance et plusieurs « indicateurs de santé » contribuent au score.
Les indicateurs de santé sont les éléments constitutifs du score d’instance, où le score est calculé périodiquement pour une « période de surveillance » prédéfinie, en fonction de tous les indicateurs détectés dans cette fenêtre de temps. Actuellement, l’analyse de l’infrastructure calcule le score d’instance une fois toutes les heures en fonction des données collectées à partir des instances. Un indicateur peut être défini comme toute activité (un événement ou un problème) appartenant à l’une des catégories suivantes sur les instances.
-
Indicateurs de ressources système
-
Indicateurs d’événements critiques
-
Indicateurs de configuration SSL
-
Indicateurs d’écart de configuration
Indicateurs de santé
-
Indicateurs de ressources système
Voici les problèmes critiques de ressources système qui peuvent survenir sur les instances NetScaler et qui sont surveillés par NetScaler ADM.
-
Utilisation élevée du CPU. L’utilisation du CPU a dépassé la valeur de seuil supérieure dans l’instance NetScaler.
-
Utilisation élevée de la mémoire. L’utilisation de la mémoire a dépassé la valeur de seuil supérieure dans l’instance NetScaler.
-
Utilisation élevée du disque. L’utilisation du disque a dépassé la valeur de seuil supérieure dans l’instance NetScaler.
-
Erreurs de disque. Il y a des erreurs sur le disque dur 0 ou le disque dur 1 sur l’hyperviseur où l’instance ADC est installée.
-
Panne de courant. L’alimentation électrique a échoué ou a été déconnectée de l’instance ADC.
-
Défaillance de la carte SSL. La carte SSL installée sur l’instance a échoué.
-
Erreurs Flash. Des erreurs de Compact Flash sont détectées sur l’instance NetScaler.
-
Rejets NIC. Les paquets rejetés par la carte NIC ont dépassé la valeur de seuil supérieure dans l’instance NetScaler.
-
Pour plus d’informations sur ces erreurs de ressources système, consultez Le tableau de bord de l’instance.
-
Indicateurs d’événements critiques
Les événements critiques suivants sont identifiés par les événements de la fonctionnalité de gestion des événements d’ADM qui sont configurés avec une gravité critique.
-
Échec de la synchronisation HA. La synchronisation de la configuration entre les instances ADC en haute disponibilité a échoué sur le serveur secondaire.
-
HA sans pulsations. Le serveur principal d’une paire d’instances ADC en haute disponibilité ne reçoit pas de pulsations du serveur secondaire.
-
État secondaire HA incorrect. Le serveur secondaire d’une paire d’instances ADC en haute disponibilité est dans un état Hors service, Inconnu ou Secondaire permanent.
-
Incompatibilité de version HA. La version des images logicielles ADC installées sur une paire d’instances ADC en haute disponibilité ne correspond pas.
-
Échec de la synchronisation du cluster. La synchronisation de la configuration entre les instances ADC en mode cluster a échoué.
-
Incompatibilité de version du cluster. La version des images logicielles ADC installées sur les instances ADC en mode cluster ne correspond pas.
-
Échec de la propagation du cluster. La propagation des configurations à toutes les instances d’un cluster a échoué.
Remarque
Vous pouvez personnaliser votre liste d’événements SNMP critiques en modifiant les niveaux de gravité des événements. Pour plus d’informations sur la modification des niveaux de gravité, consultez Modifier la gravité signalée des événements qui se produisent sur les instances NetScaler.
Pour plus d’informations sur les événements dans NetScaler ADM, consultez Événements.
-
-
Indicateurs de configuration SSL
-
Force de clé non recommandée. La force de clé des certificats SSL n’est pas conforme aux normes NetScaler®.
-
Émetteur non recommandé. L’émetteur du certificat SSL n’est pas recommandé par Citrix.
-
Certificats SSL expirés. Le certificat SSL installé dans l’instance ADC a expiré.
-
Expiration des certificats SSL imminente. Le certificat SSL installé dans l’instance ADC est sur le point d’expirer dans la semaine à venir.
-
Algorithmes non recommandés. Les algorithmes de signature des certificats SSL installés dans l’instance ADC ne sont pas conformes aux normes NetScaler.
-
Pour plus d’informations sur les certificats SSL, consultez Tableau de bord SSL.
-
Indicateurs d’écart de configuration
-
Modèle d’écart de configuration. Il y a un écart (modifications non enregistrées) dans la configuration par rapport aux modèles d’audit que vous avez créés avec des configurations spécifiques que vous souhaitez auditer sur certaines instances.
-
Valeur par défaut d’écart de configuration. Il y a un écart (modifications non enregistrées) dans la configuration par rapport aux fichiers de configuration par défaut.
-
Pour plus d’informations sur les écarts de configuration et sur la façon d’exécuter des rapports d’audit pour vérifier les écarts de configuration, consultez Afficher les rapports d’audit.
Afficher les problèmes de capacité ADC
Lorsqu’une instance ADC a consommé la majeure partie de sa capacité disponible, une perte de paquets peut se produire lors du traitement du trafic client. Ce problème entraîne de faibles performances dans une instance ADC. En comprenant ces problèmes de capacité ADC, vous pouvez allouer des licences supplémentaires de manière proactive pour stabiliser les performances ADC.
Pour afficher les problèmes de capacité ADC :
- Accédez à Infrastructure > Infrastructure Analytics.
- Développez l’instance pour laquelle vous souhaitez afficher les problèmes de capacité.
L’ADM interroge ces événements toutes les cinq minutes à partir de l’instance ADC et affiche les pertes de paquets ou les incréments de compteur de limitation de débit, s’ils existent. Les problèmes sont classés selon les paramètres de capacité suivants :
- Limite de débit atteinte – Le nombre de paquets perdus dans l’instance après que la limite de débit a été atteinte.
- Limite de CPU PE atteinte - Le nombre de paquets perdus sur toutes les cartes NIC après que la limite de CPU PE a été atteinte.
- Limite PPS atteinte – Le nombre de paquets perdus dans l’instance après que la limite PPS a été atteinte.
- Limite de débit SSL – Le nombre de fois où la limite de débit SSL a été atteinte.
- Limite TPS SSL – Le nombre de fois où la limite TPS SSL a été atteinte.
L’ADM calcule le score d’instance sur le seuil de capacité défini.
-
Seuil bas – 1 perte de paquet ou incrément de compteur de limitation de débit
-
Seuil haut – 10000 pertes de paquets ou incréments de compteur de limitation de débit
Par conséquent, lorsqu’une instance ADC dépasse le seuil de capacité, le score d’instance est impacté.
Lorsque des paquets sont perdus ou que les compteurs de limitation de débit s’incrémentent, un événement est généré sous la catégorie ADCCapacityBreach. Pour afficher ces événements, accédez à Comptes > Événements système.
Valeur des indicateurs de santé
Les indicateurs sont classés en indicateurs de haute priorité et indicateurs de basse priorité en fonction de leurs valeurs comme suit :
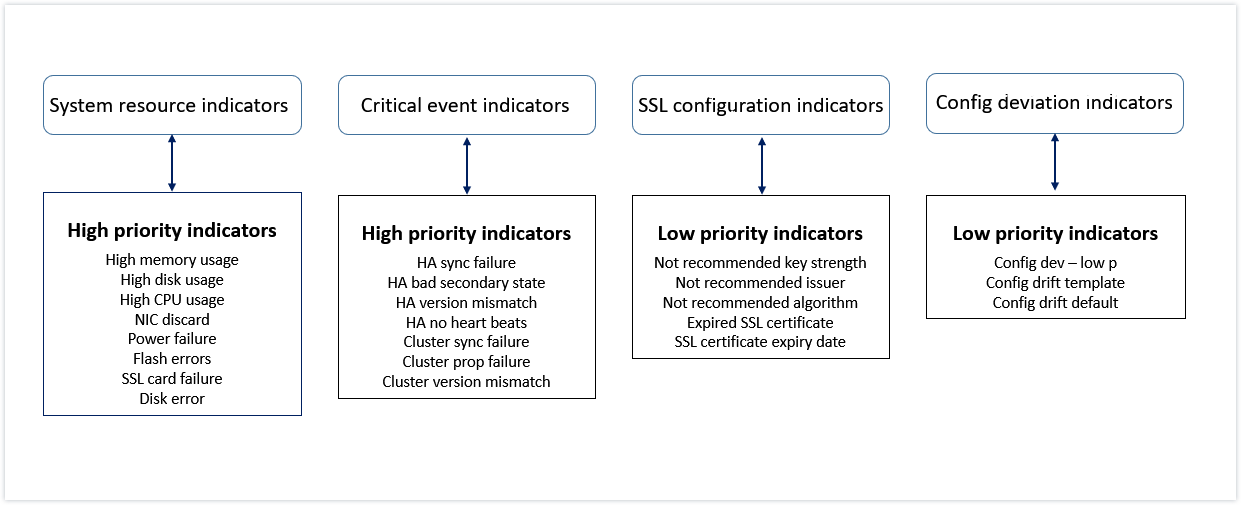
Les indicateurs de santé au sein du même groupe d’indicateurs ont des pondérations différentes. Un indicateur peut contribuer davantage à la baisse du score d’instance qu’un autre indicateur. Par exemple, une utilisation élevée de la mémoire réduit davantage le score d’instance qu’une utilisation élevée du disque, une utilisation élevée du CPU et un rejet NIC. Si un plus grand nombre d’indicateurs sont détectés sur une instance, le score d’instance est plus faible.
La valeur d’un indicateur est calculée selon les règles suivantes. L’indicateur est dit détecté de l’une des trois manières suivantes :
-
Basé sur une activité. Par exemple, un indicateur de ressource système est déclenché chaque fois qu’il y a une panne de courant sur l’instance, et cet indicateur réduit la valeur du score d’instance. Lorsque l’indicateur est effacé, la pénalité est effacée et le score d’instance augmente.
-
Basé sur le dépassement de la valeur de seuil. Par exemple, un indicateur de ressource système est déclenché lorsque la carte NIC rejette des paquets et que le niveau de seuil est dépassé.
-
Basé sur le dépassement des valeurs de seuil bas et haut. Ici, un indicateur peut être déclenché de deux manières :
-
Lorsque la valeur de l’indicateur est comprise entre les seuils bas et haut, auquel cas une pénalité partielle est appliquée au score d’instance.
-
Lorsque la valeur dépasse le seuil haut, auquel cas une pénalité complète est appliquée au score d’instance.
-
Aucune pénalité n’est appliquée au score d’instance si la valeur tombe en dessous d’un seuil bas.
-
Par exemple, l’utilisation du CPU est un indicateur de ressource système déclenché lorsque la valeur d’utilisation dépasse le seuil bas et également lorsque la valeur dépasse le seuil haut.
Tableau de bord d’analyse de l’infrastructure
Accédez à Infrastructure > Infrastructure Analytics.
L’analyse de l’infrastructure peut être affichée au format Cercle ou Tabulaire. Vous pouvez basculer entre les deux formats.
- Dans la vue tabulaire, vous pouvez rechercher une instance en saisissant le nom d’hôte ou l’adresse IP dans la barre de recherche.
- Par défaut, la page Analyse de l’infrastructure affiche le panneau Récapitulatif sur le côté droit de la page.
- Cliquez sur l’icône Paramètres pour afficher le panneau Paramètres.
- Dans les deux formats d’affichage, le panneau Récapitulatif affiche les détails de toutes les instances de votre réseau.
Vue en cercle
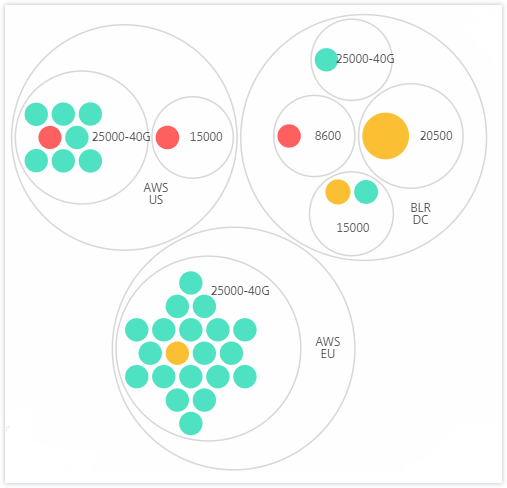
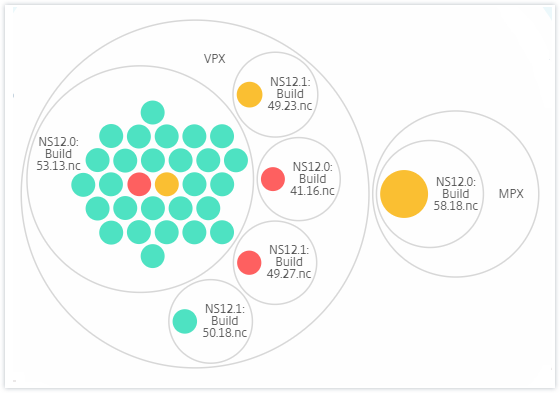
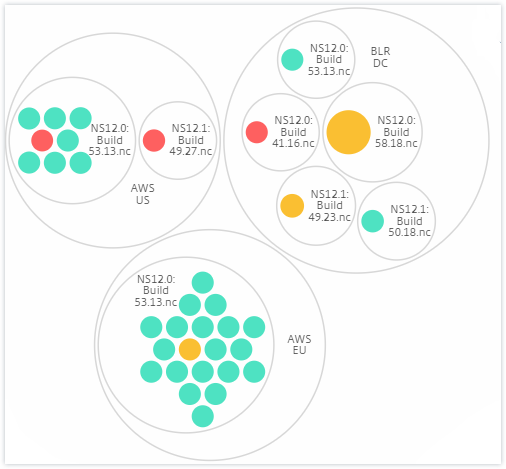
Les diagrammes en cercle montrent les groupes d’instances sous forme de cercles étroitement organisés. Ils montrent souvent des hiérarchies où les groupes d’instances plus petits sont soit colorés de manière similaire à d’autres de la même catégorie, soit imbriqués dans des groupes plus grands. Les cercles représentent des ensembles de données hiérarchiques et montrent différents niveaux de la hiérarchie et comment ils interagissent les uns avec les autres.
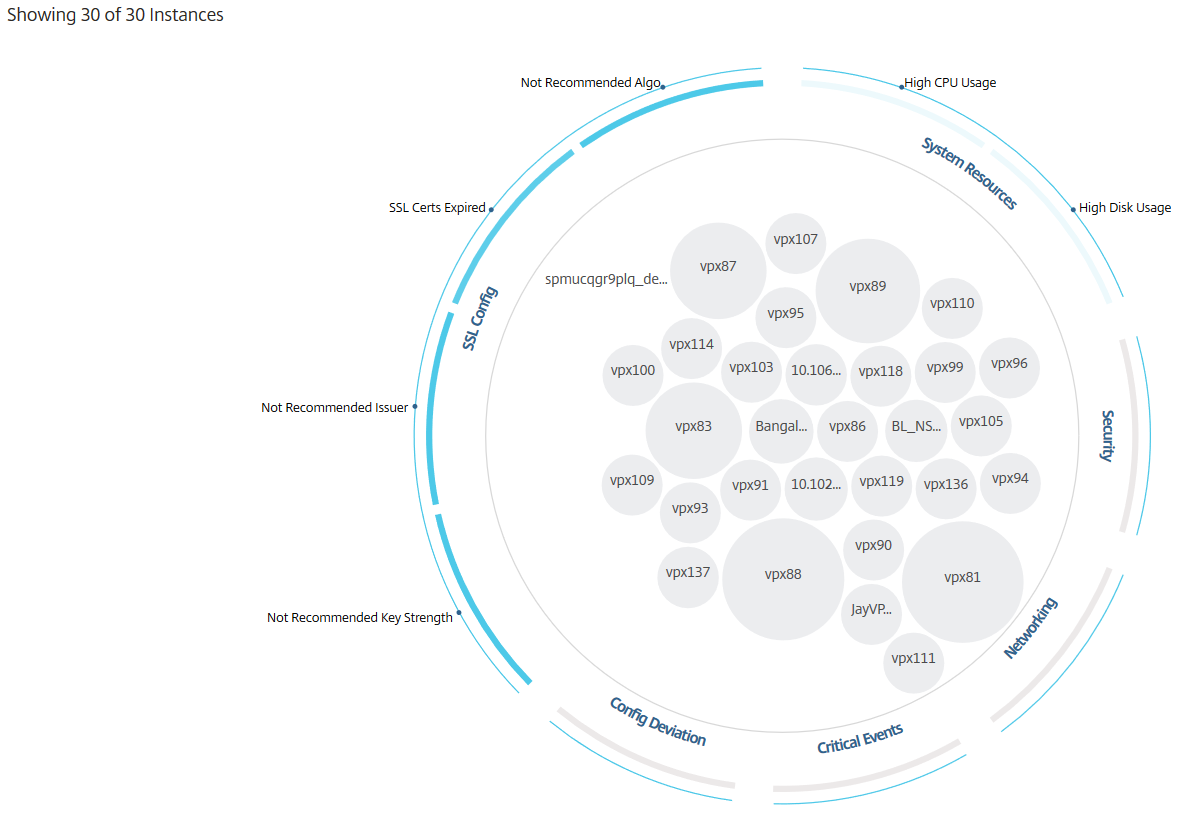
Cercles d’instances
Couleur. Chaque instance est représentée dans la vue en cercle par un cercle coloré. La couleur du cercle indique l’état de santé de cette instance.
- Vert - le score d’instance est compris entre 100 et 80. L’instance est saine.
- Jaune - le score d’instance est compris entre 80 et 50 ; certains problèmes ont été détectés et nécessitent un examen.
- Rouge - le score d’instance est inférieur à 50. L’instance est dans un état critique car plusieurs problèmes ont été détectés sur cette instance.
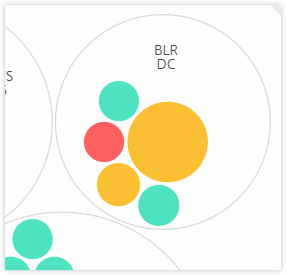
Taille. La taille de ces cercles colorés indique le nombre de serveurs virtuels configurés sur cette instance. Un cercle plus grand indique un plus grand nombre de serveurs virtuels.
Vous pouvez survoler le pointeur de la souris sur chacun des cercles d’instances (cercles colorés) pour afficher un résumé. L’info-bulle affiche le nom d’hôte de l’instance, le nombre de serveurs virtuels actifs et le nombre d’applications configurées sur cette instance.
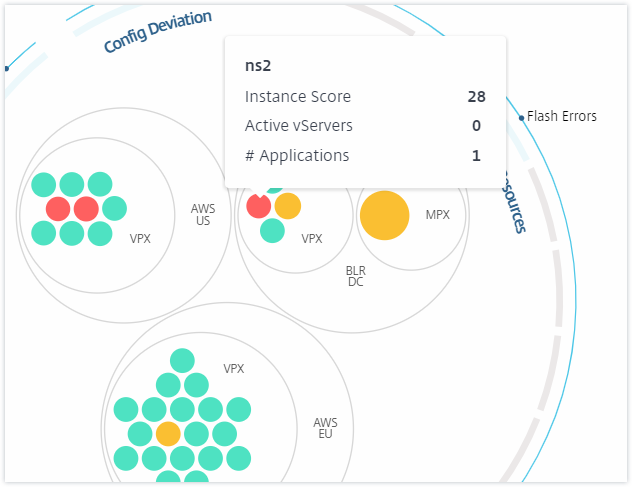
Cercles d’instances groupés
La vue en cercle, au départ, comprend des cercles d’instances qui sont regroupés, imbriqués ou empaquetés à l’intérieur d’un autre cercle en fonction des critères suivants :
-
le site où ils sont déployés
-
le type d’instances déployées - VPX, MPX, SDX et CPX
-
le modèle virtuel ou physique de l’instance ADC
-
la version de l’image ADC installée sur les instances
L’image suivante montre une vue en cercle où les instances sont d’abord regroupées par le site ou le centre de données où elles sont déployées, puis elles sont regroupées en fonction de leur type, VPX et MPX.
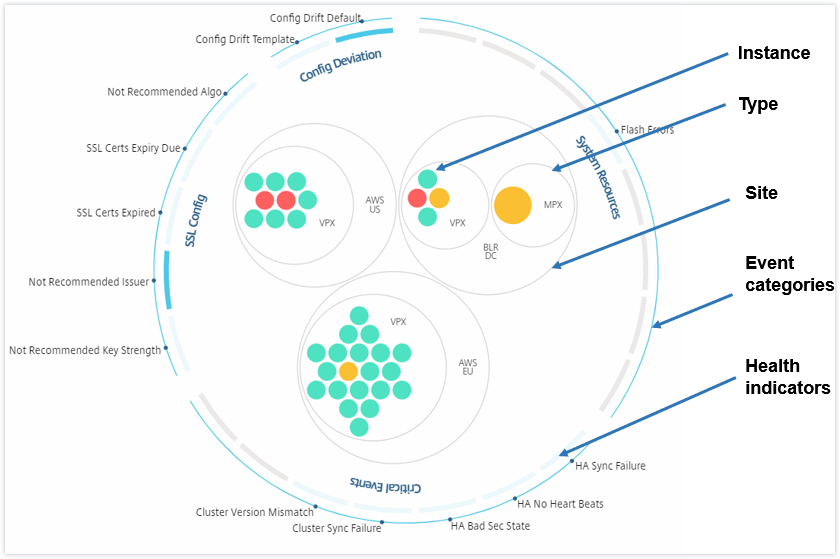
Tous ces cercles imbriqués sont délimités par deux cercles extérieurs. Les deux cercles extérieurs représentent les quatre catégories d’événements surveillés par NetScaler ADM (ressources système, événements critiques, configuration SSL et écart de configuration) et les indicateurs de santé contributifs.
Cercles d’instances en cluster
NetScaler ADM surveille de nombreuses instances. Pour faciliter la surveillance et la maintenance de ces instances, l’analyse de l’infrastructure vous permet de les regrouper à deux niveaux. Autrement dit, les regroupements d’instances peuvent être imbriqués dans un autre regroupement.
Par exemple, le centre de données BLR contient deux types d’instances ADC - VPX et MPX, déployées. Vous pouvez d’abord regrouper les instances ADC par leur type, puis regrouper toutes les instances par le site où elles sont regroupées. Vous pouvez maintenant facilement identifier combien de types d’instances sont déployés dans les sites que vous gérez.
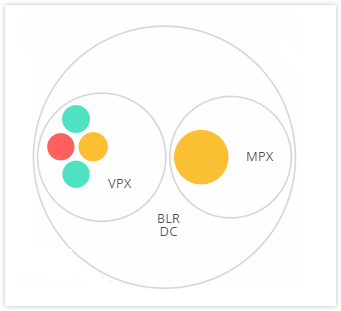
Voici quelques autres exemples de regroupement à deux niveaux :
Site et modèle :
Type et version :
Site et version :
Comment utiliser la vue en cercle
Cliquez sur chacun des cercles colorés pour mettre en évidence cette instance.
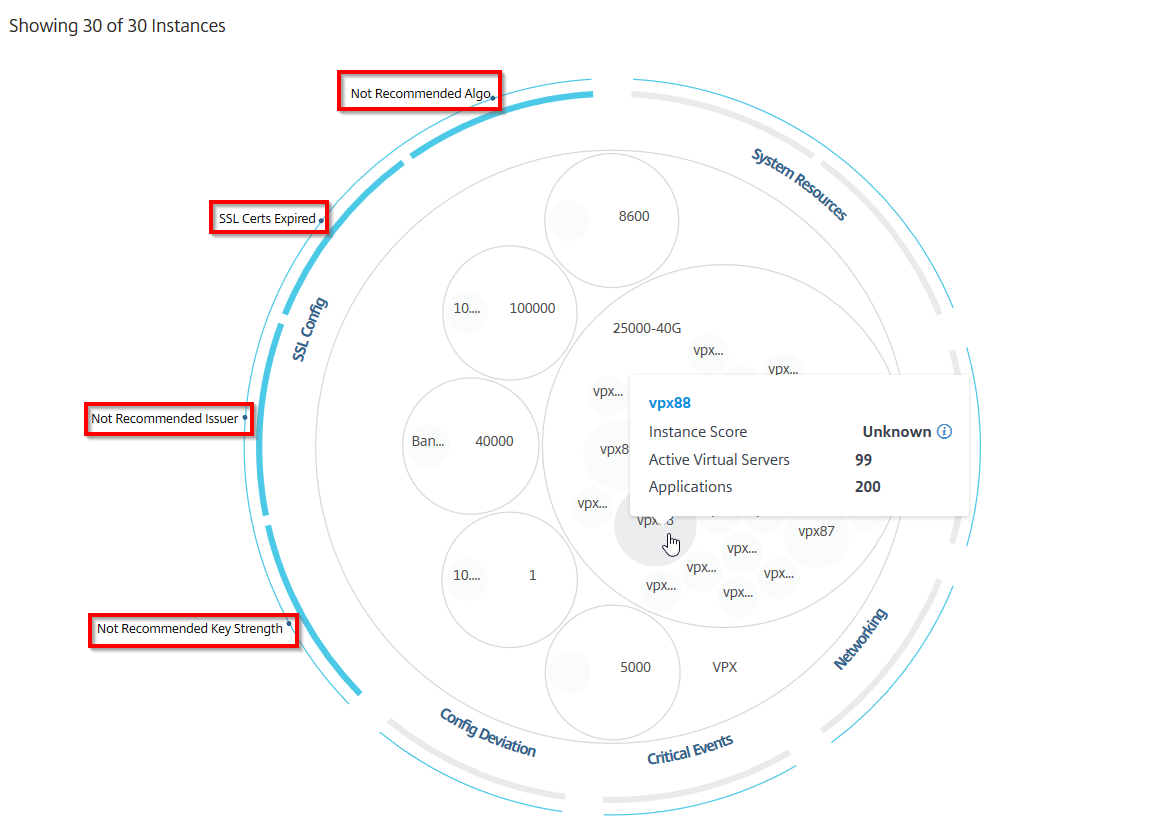
Selon les événements qui se sont produits dans cette instance, seuls les indicateurs de santé sont mis en évidence sur les cercles extérieurs. Par exemple, les deux images suivantes de la vue en cercle affichent différents ensembles d’indicateurs de risque, bien que les deux instances soient dans un état critique.
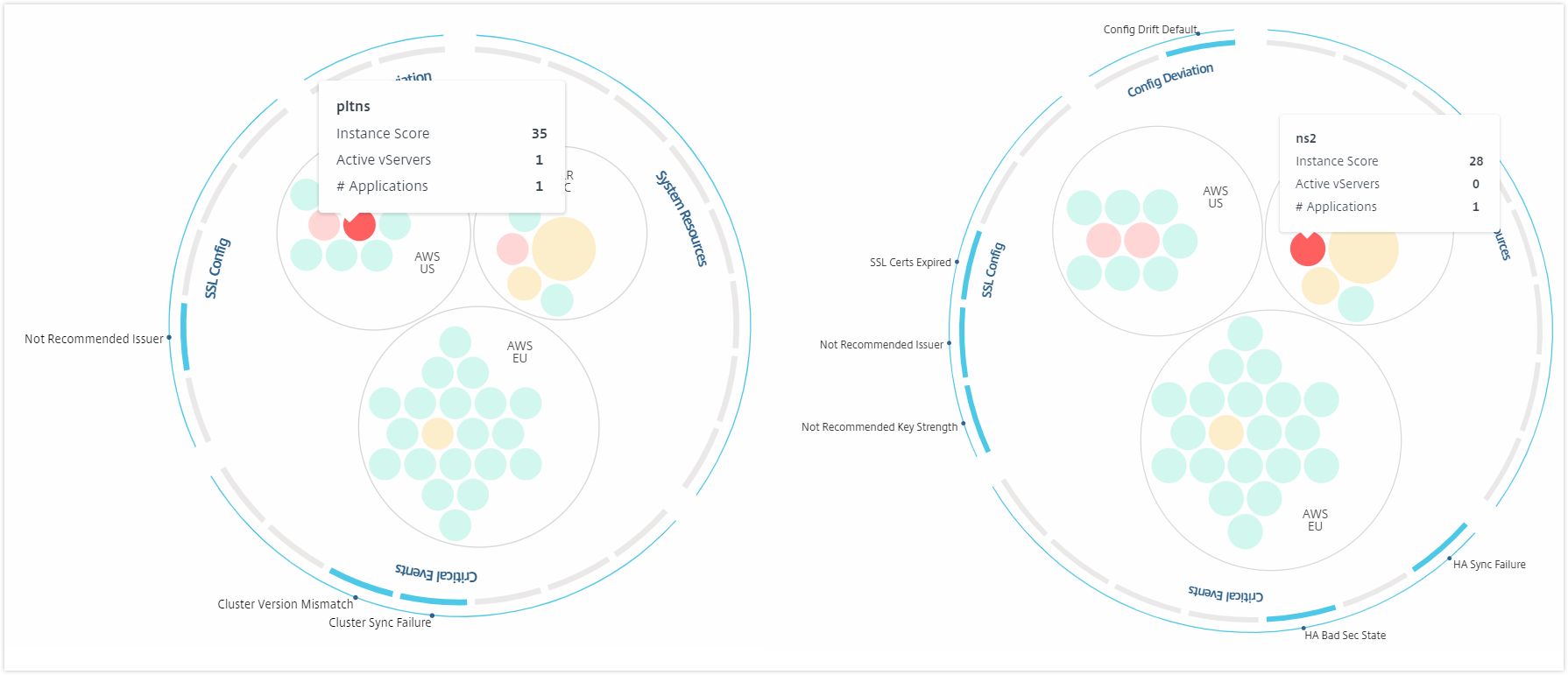
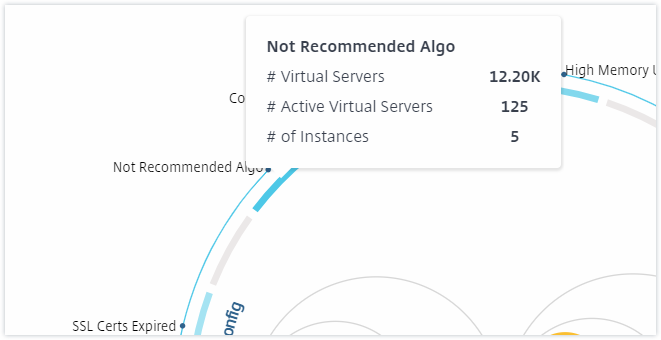
Vous pouvez également cliquer sur les indicateurs de santé pour obtenir plus de détails sur le nombre d’instances qui ont signalé cet indicateur de risque. Par exemple, cliquez sur Not recommended Algo pour afficher le rapport récapitulatif de cet indicateur de risque.
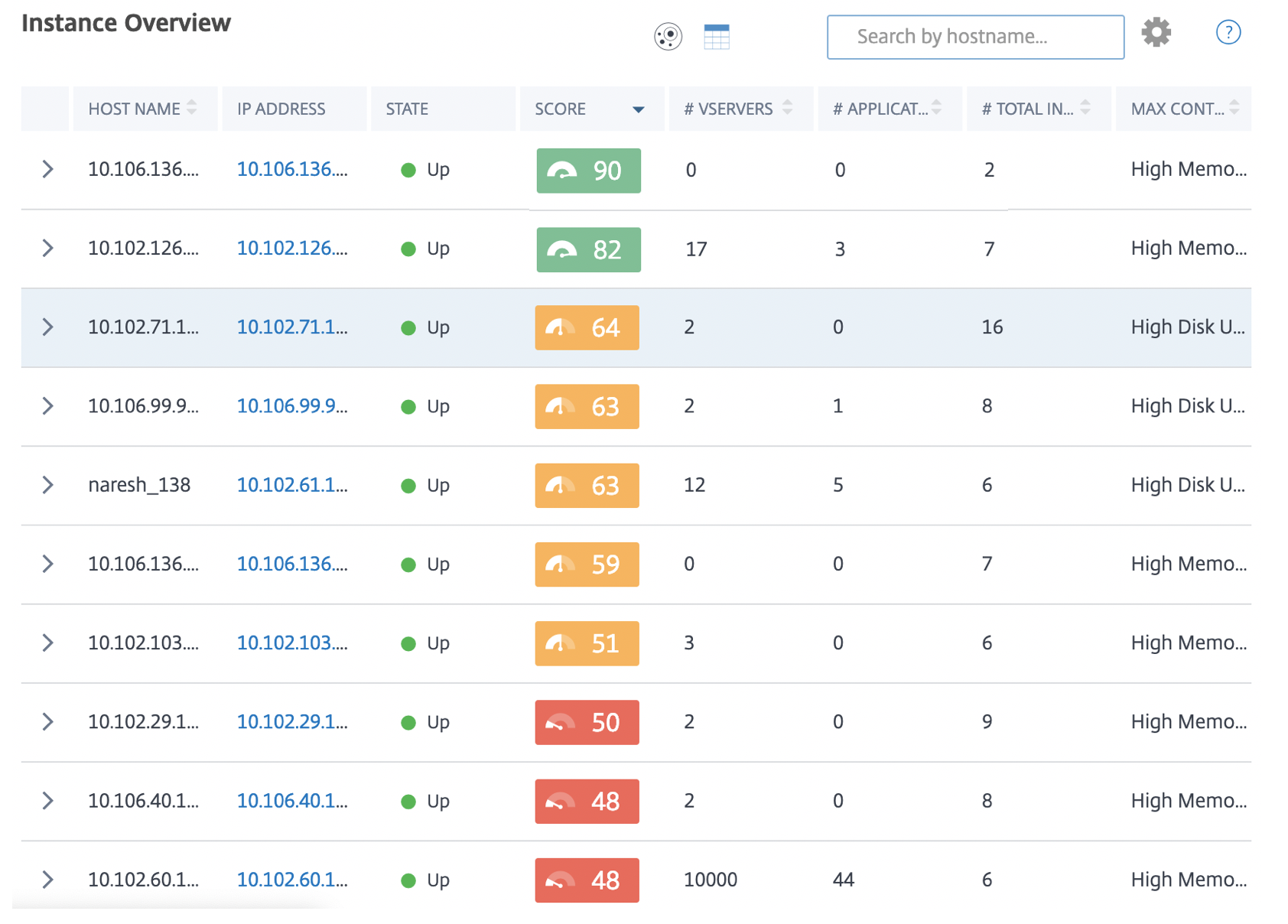
Vue tabulaire
La vue tabulaire affiche les instances et les détails de ces instances dans un format tabulaire. Les détails affichés sont les suivants :
-
Nom d’hôte de l’instance
-
L’adresse IP de l’instance
-
État de l’instance
-
Score d’instance
-
Nombre de serveurs virtuels configurés sur cette instance
-
Nombre d’applications configurées sur cette instance
-
Nombre total d’indicateurs de risque
-
L’événement qui contribue le plus à un score d’instance réduit
Les instances qui sont dans un état critique se trouvent en haut du tableau, suivies des instances qui doivent être examinées, puis des instances plus saines.
Cliquez sur l’adresse IP de l’instance dans la vue tabulaire pour afficher plus de détails sur cette instance sous forme de tableau de bord. Le tableau de bord de l’instance présente un aperçu de l’instance où vous pouvez voir l’utilisation du CPU, de la mémoire et du disque de l’instance. Vous pouvez également voir des détails liés à la gestion des certificats SSL, à l’audit de configuration, aux fonctions réseau et à un rapport réseau qui montre l’utilisation détaillée du réseau de l’instance. Faites défiler vers le bas pour voir la liste des fonctionnalités et des modes activés sur cette instance.
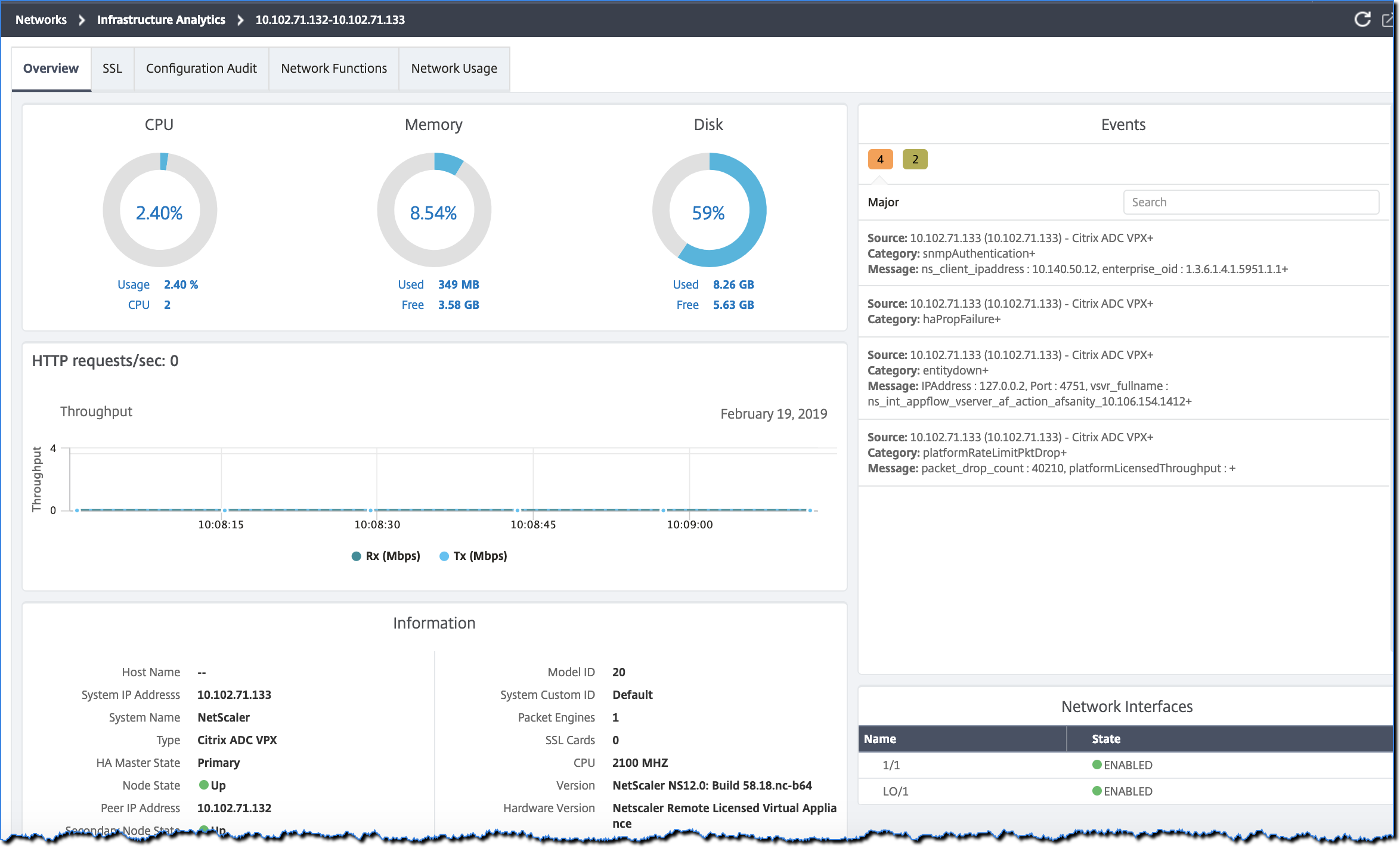
Vous pouvez également cliquer sur la flèche au début de chaque ligne pour développer la ligne et obtenir plus de détails.
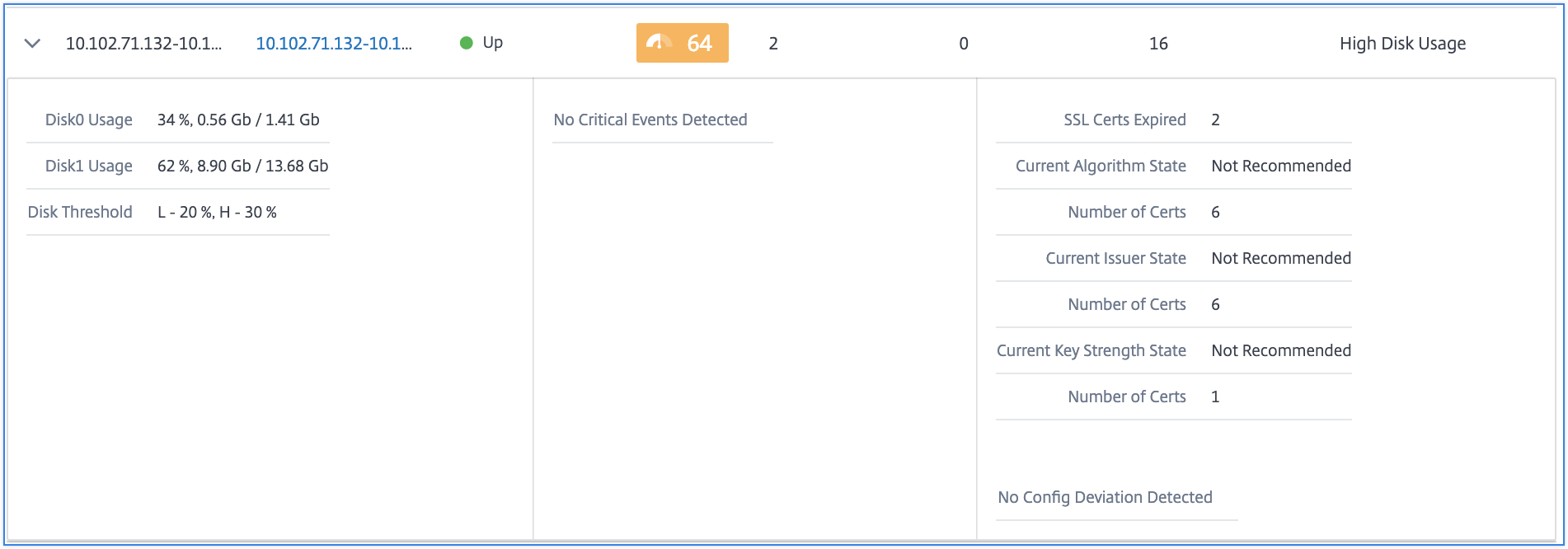
La ligne de tableau développée affiche les erreurs qui se sont produites sur l’instance pour toutes les catégories. Dans l’exemple ci-dessus, vous pouvez voir qu’il y a eu des erreurs dans les ressources système, la configuration SSL et des écarts dans les fichiers de configuration. Mais aucun événement critique n’est signalé par l’instance.
Comment utiliser le panneau Récapitulatif
Le panneau Récapitulatif vous aide à vous concentrer efficacement et rapidement sur les instances qui nécessitent un examen ou qui sont dans un état critique. Le panneau est divisé en trois onglets : Vue d’ensemble, Informations sur l’instance et Profil de trafic. Les modifications que vous apportez dans ce panneau modifient l’affichage dans les formats de vue en cercle et tabulaire. Les sections suivantes décrivent ces onglets plus en détail. Les exemples des sections suivantes vous aident à utiliser efficacement les différents critères de sélection pour analyser les problèmes signalés par les instances.
Vue d’ensemble :
L’onglet Vue d’ensemble vous permet de surveiller les instances en fonction des erreurs matérielles, de l’utilisation, des certificats expirés et d’indicateurs similaires qui peuvent survenir dans les instances. Les indicateurs que vous pouvez surveiller ici sont les suivants :
-
Utilisation du CPU
-
Utilisation de la mémoire
-
Utilisation du disque
-
Défaillances système
-
Événements critiques
-
Expiration des certificats SSL
Les exemples suivants illustrent comment vous pouvez interagir avec le panneau Vue d’ensemble pour isoler les instances qui signalent des erreurs.
Exemple 1 : Afficher les instances qui sont dans un état d’examen :
Sélectionnez la case à cocher Examiner pour afficher uniquement les instances qui ne signalent pas d’erreurs critiques, mais qui nécessitent toujours une attention particulière.
Les histogrammes du panneau Vue d’ensemble représentent un nombre agrégé d’instances basé sur les événements d’utilisation élevée du CPU, d’utilisation élevée de la mémoire et d’utilisation élevée du disque. Les histogrammes sont gradués à 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 % et 100 %. Survolez le pointeur de votre souris sur l’un des diagrammes à barres. La légende au bas du graphique affiche la plage d’utilisation et le nombre d’instances dans cette plage. Vous pouvez également cliquer sur le diagramme à barres pour afficher toutes les instances dans cette plage.
Exemple 2 : Afficher les instances qui consomment entre 10 % et 20 % de la mémoire allouée :
Dans la section d’utilisation de la mémoire, cliquez sur le diagramme à barres. La légende indique que la plage sélectionnée est de 10 à 20 % et qu’il y a 29 instances fonctionnant dans cette plage.
Vous pouvez également sélectionner plusieurs plages dans ces histogrammes.
Exemple 3 : Afficher les instances qui consomment beaucoup d’espace disque dans plusieurs plages :
Pour afficher les instances qui ont consommé de l’espace disque entre 0 et 10 %, faites glisser le pointeur de la souris sur les deux plages.
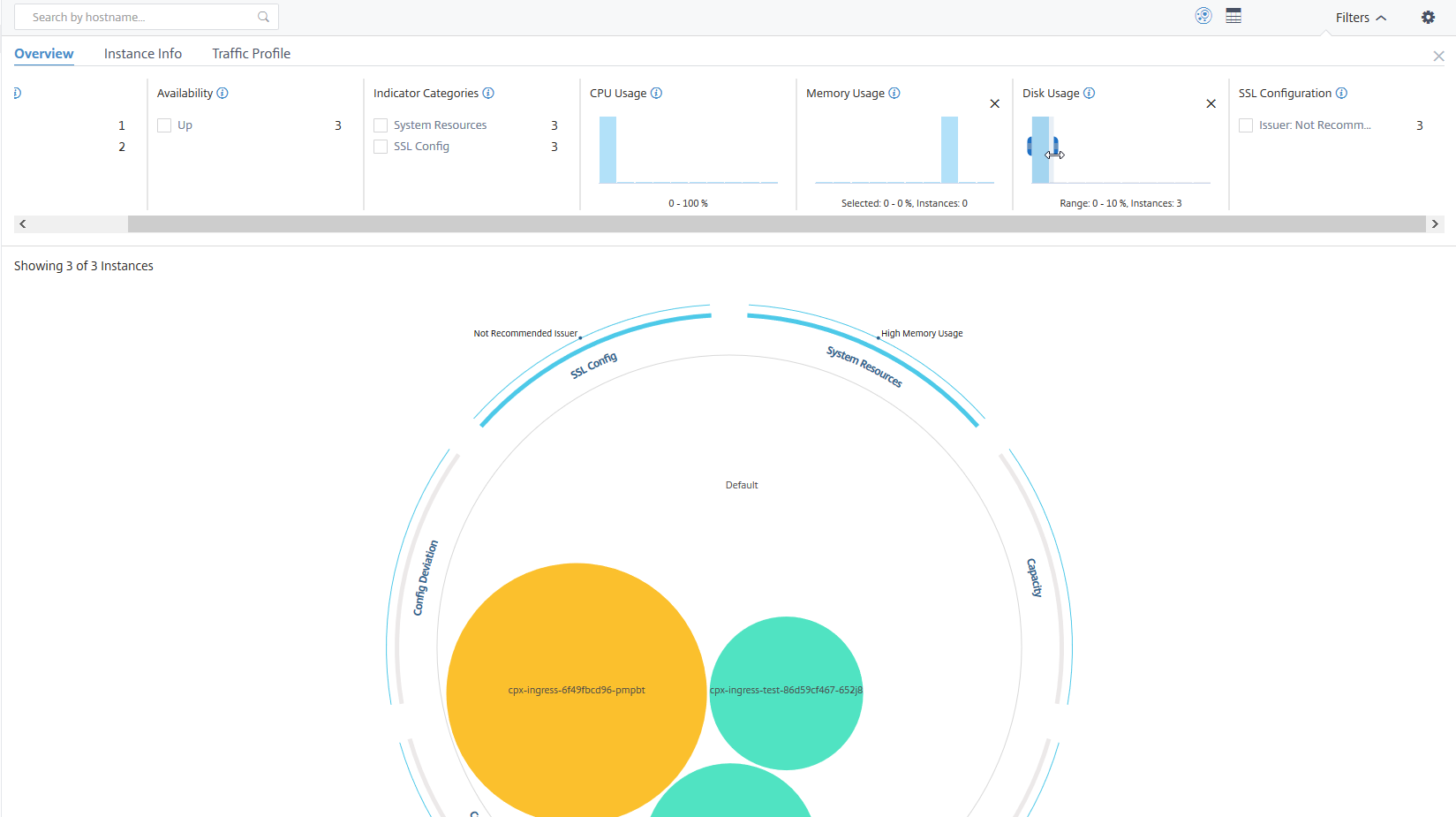
Remarque
Cliquez sur « X » pour annuler la sélection. Vous pouvez également cliquer sur Réinitialiser pour annuler plusieurs sélections.
Les diagrammes à barres horizontales du panneau Vue d’ensemble indiquent le nombre d’instances qui signalent des erreurs système, des événements critiques et l’état d’expiration des certificats SSL. Cochez la case pour afficher ces instances.
Exemple 4 : Afficher les instances pour les certificats SSL expirés :
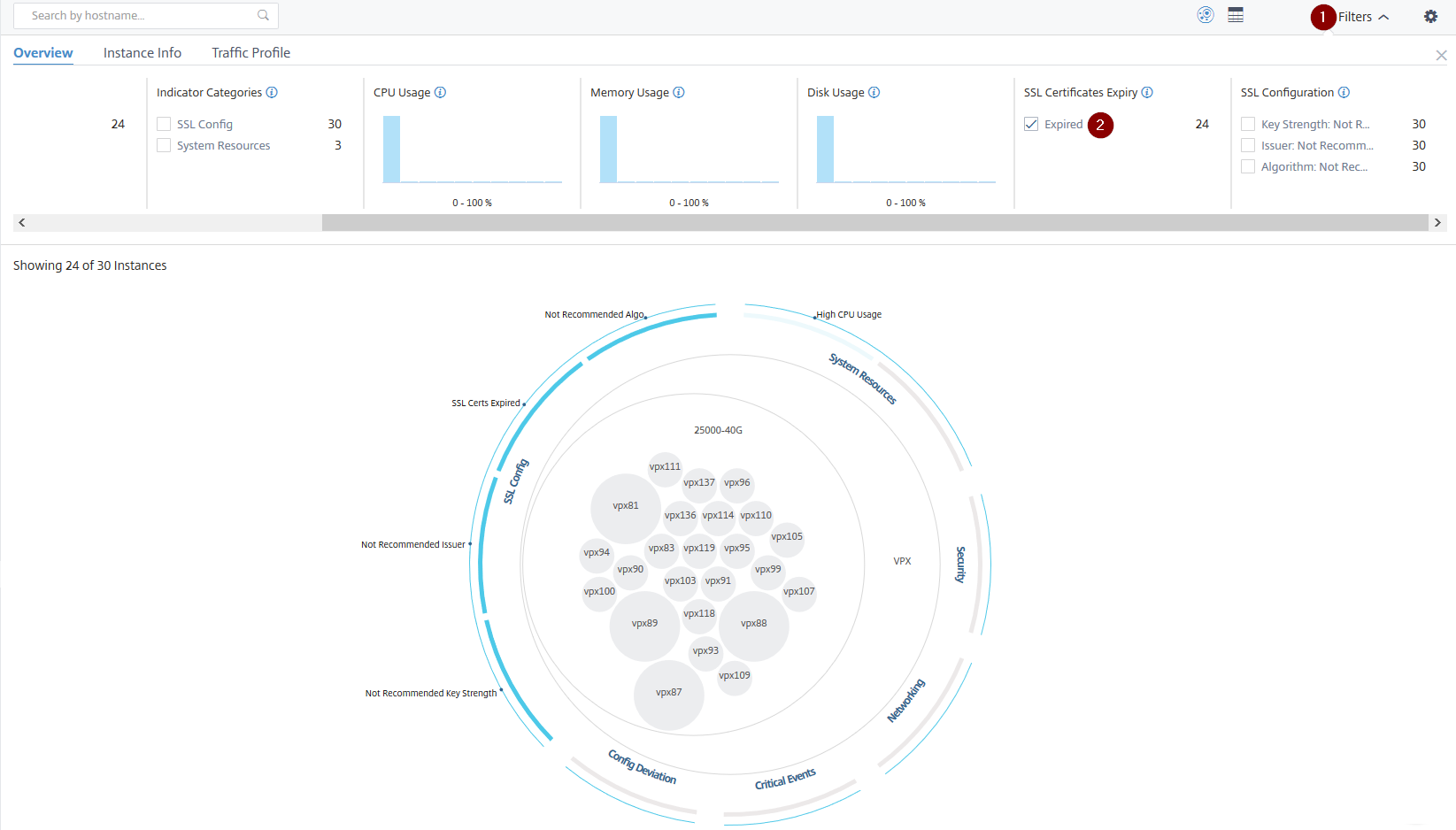
1 - Cliquez sur la liste Filtrer.
2 - Dans la section Expiration des certificats SSL, cochez la case Expiré pour afficher les instances.
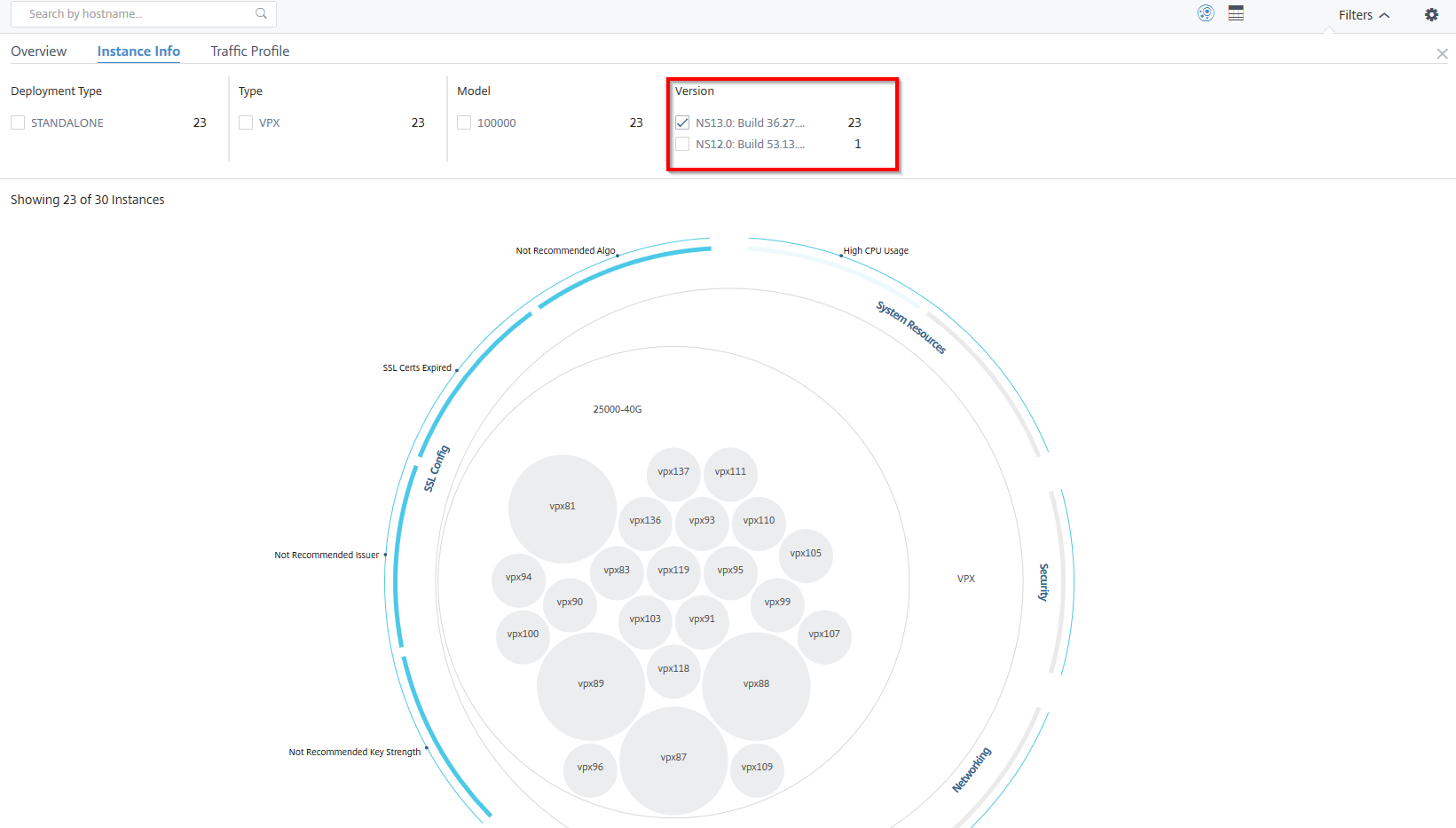
Informations sur l’instance
Le panneau Informations sur l’instance vous permet d’afficher les instances en fonction du type de déploiement, du type d’instance, du modèle et de la version du logiciel. Vous pouvez sélectionner plusieurs cases à cocher pour affiner votre sélection.
Exemple 5 : Afficher les instances NetScaler VPX avec un numéro de build spécifique :
Sélectionnez la version que vous souhaitez afficher.
Profil de trafic
Les histogrammes du panneau Profil de trafic représentent un nombre agrégé d’instances basé sur le débit sous licence sur les instances, le nombre de requêtes, de connexions et de transactions gérées par les instances. Sélectionnez le diagramme à barres pour afficher les instances dans cette plage.
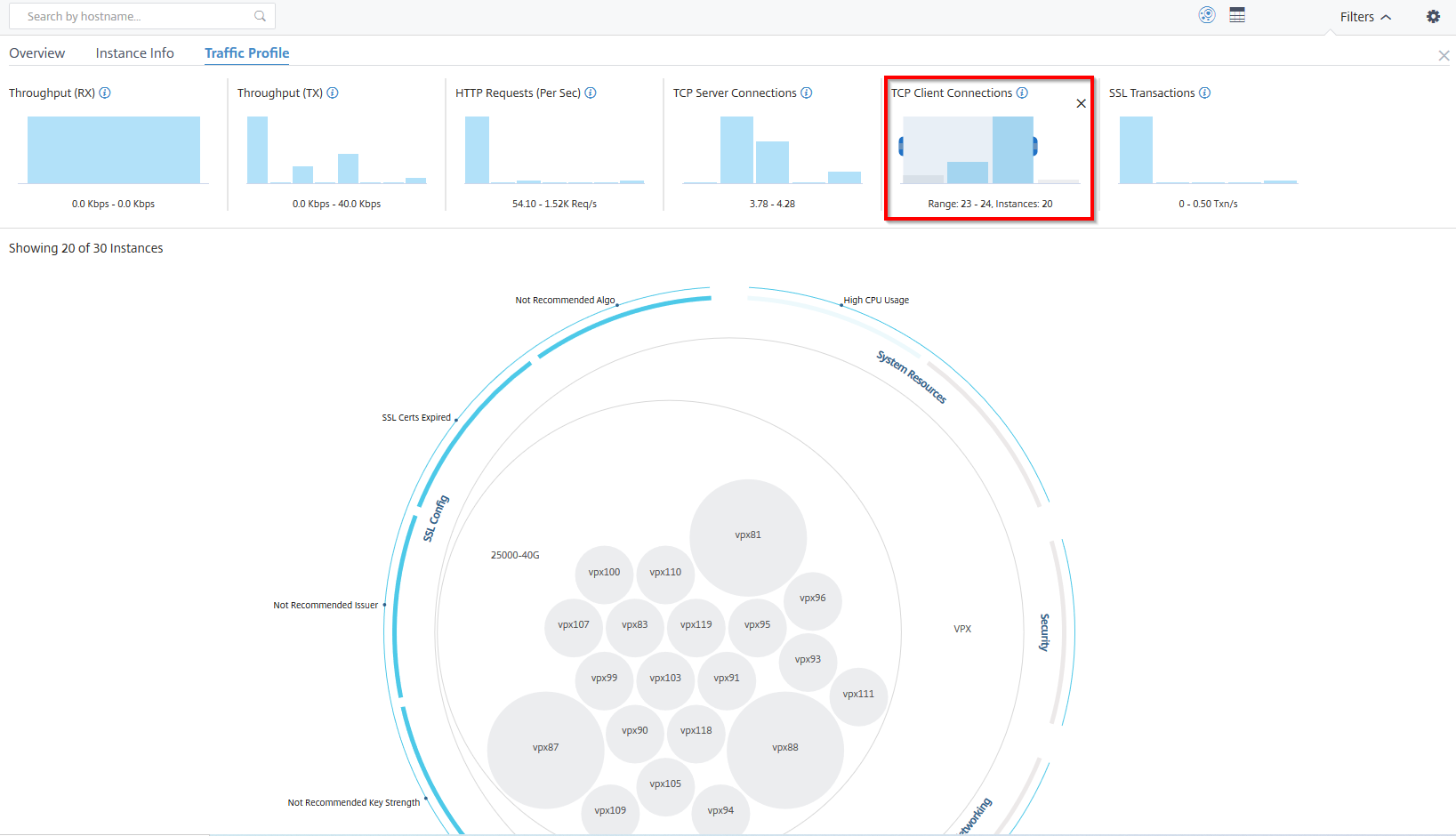
Exemple 6 : Afficher les instances prenant en charge les connexions TCP :
L’image suivante montre le nombre d’instances prenant en charge les connexions TCP.
Comment utiliser le panneau Paramètres
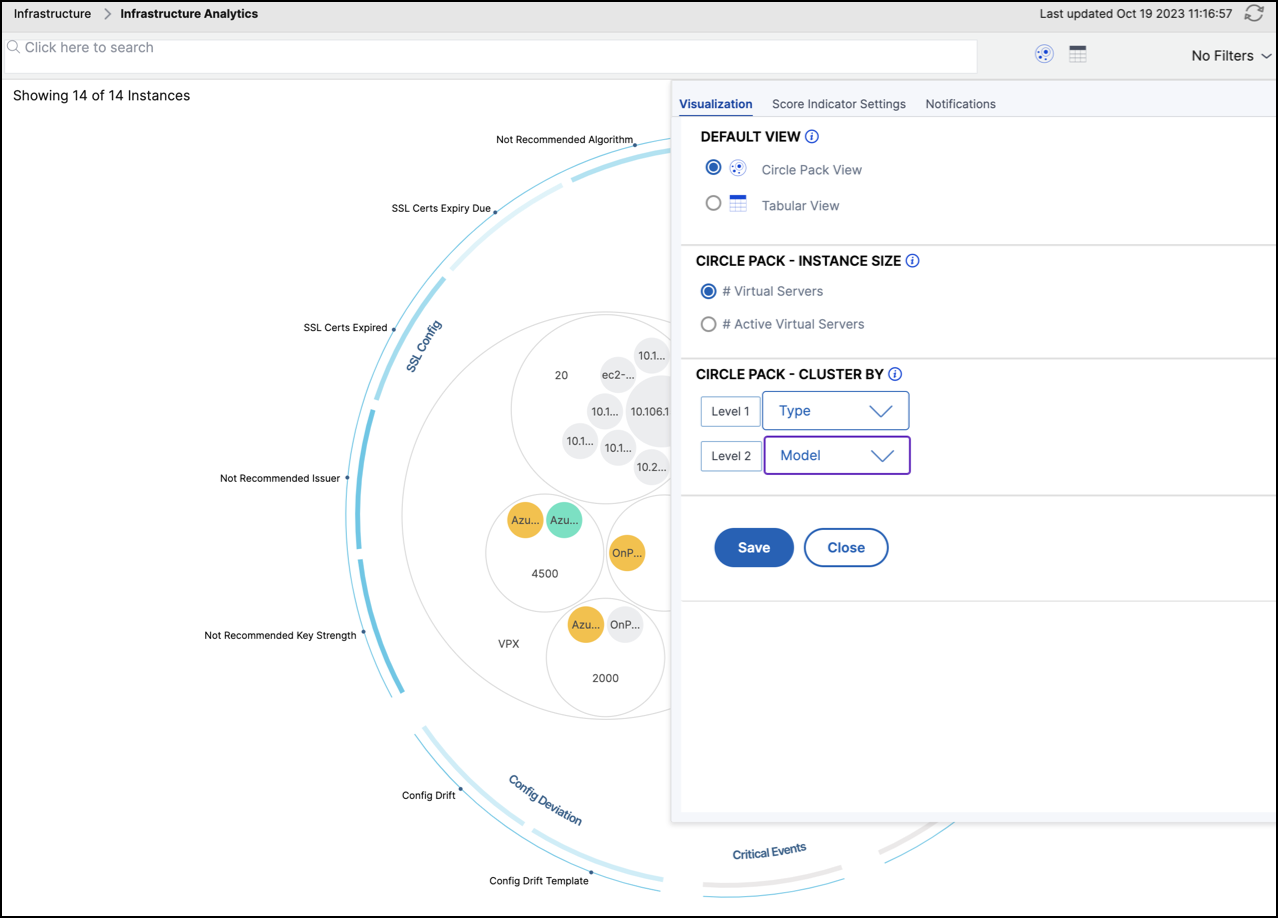
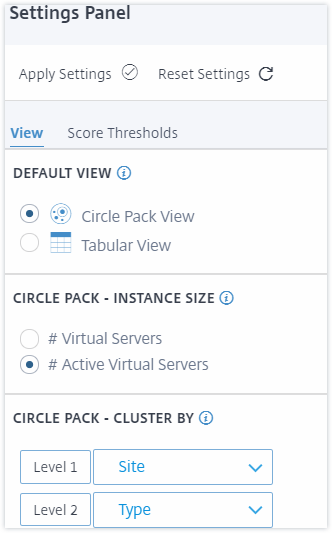
Le panneau Paramètres vous permet de définir la vue par défaut de l’analyse de l’infrastructure. Il vous permet également de définir les valeurs de seuil bas et haut pour l’utilisation élevée du CPU, l’utilisation élevée du disque et l’utilisation élevée de la mémoire. Le panneau des paramètres est divisé en deux onglets : Vue et Seuils de score.
Vue
-
Vue par défaut. Sélectionnez le format Cercle ou Tabulaire comme vue par défaut sur la page d’analyse. Le format que vous sélectionnez est celui que vous voyez chaque fois que vous accédez à la page dans NetScaler ADM.
-
Vue en cercle - Taille de l’instance. Permet de définir la taille du cercle de l’instance par le nombre de serveurs virtuels ou le nombre de serveurs virtuels actifs.
-
Vue en cercle - Regrouper par. Décidez du regroupement à deux niveaux des cercles d’instances. Pour plus d’informations sur le regroupement d’instances, consultez Cercles d’instances en cluster.
Seuils de score
Vous pouvez modifier les valeurs de seuil bas et haut pour l’utilisation élevée du CPU, de la mémoire et du disque en fonction des exigences de trafic de votre organisation. Faites glisser les poignées dans chacun des histogrammes de sélection pour définir les valeurs.
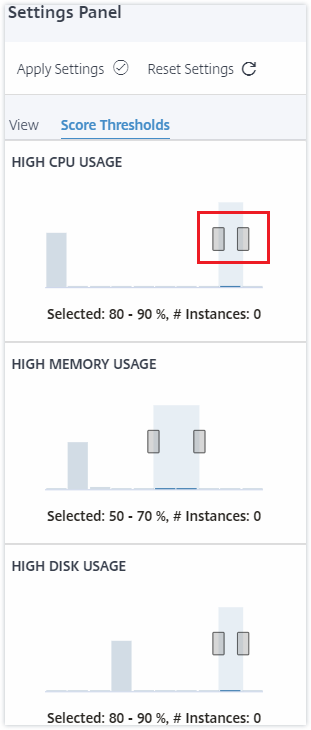
Remarque
Cliquez sur Appliquer les paramètres pour appliquer ces modifications, ou cliquez sur Réinitialiser pour annuler toutes les modifications.
Comment visualiser les données sur le tableau de bord
Grâce à l’analyse de l’infrastructure, les administrateurs réseau peuvent désormais identifier les instances nécessitant le plus d’attention en quelques secondes. Pour comprendre la visualisation des données plus en détail, prenons le cas de Chris, un administrateur réseau d’ExampleCompany.
Chris gère de nombreuses instances NetScaler au sein de l’organisation. Quelques-unes des instances traitent un trafic élevé, et Chris doit les surveiller de près. Chris remarque que quelques instances à trafic élevé ne traitent plus l’intégralité du trafic qui les traverse. Pour analyser cette réduction, Chris devait auparavant lire plusieurs rapports de données provenant de diverses sources. Chris devait passer plus de temps à essayer de corréler manuellement les données et à déterminer quelles instances n’étaient pas dans un état optimal et nécessitaient une attention particulière.
Chris utilise la fonctionnalité d’analyse de l’infrastructure pour visualiser l’état de santé de toutes les instances.
Les deux exemples suivants illustrent comment l’analyse de l’infrastructure aide Chris dans l’activité de maintenance :
Exemple 1 - Pour surveiller le trafic SSL :
Chris remarque sur la vue en cercle qu’une instance a un score d’instance faible et que cette instance est dans un état « Critique ». Chris clique sur cette instance pour voir quel est le problème. Le résumé de l’instance indique qu’il y a une défaillance de la carte SSL sur cette instance et que l’instance est incapable de traiter le trafic SSL (le trafic SSL a diminué). Chris extrait ces informations et envoie un rapport à l’équipe pour qu’elle examine le problème immédiatement.
Exemple 2 - Pour surveiller les modifications de configuration :
Chris remarque également qu’une autre instance est dans un état « Examen » et qu’il y a eu un écart de configuration récemment. Lorsque Chris clique sur l’indicateur de risque d’écart de configuration, Chris remarque que des modifications de configuration liées à RC4 Cipher, SSL v3, TLS 1.0 et TLS 1.1 ont été apportées, ce qui pourrait être dû à des problèmes de sécurité. Chris remarque également que le profil de trafic de transaction SSL pour cette instance a diminué. Chris exporte ce rapport et l’envoie à l’administrateur pour qu’il enquête plus en détail.
Dans cet article
- Analyse de l’infrastructure
- Score d’instance
- Indicateurs de santé
- Afficher les problèmes de capacité ADC
- Tableau de bord d’analyse de l’infrastructure
- Vue en cercle
- Vue tabulaire
- Comment utiliser le panneau Récapitulatif
- Comment utiliser le panneau Paramètres
- Comment visualiser les données sur le tableau de bord