-
-
-
在 VMware ESX、Linux KVM 和 Citrix Hypervisor 上优化 NetScaler VPX 性能
-
-
在 Microsoft Azure 上部署 NetScaler VPX 实例
-
-
-
-
-
-
-
-
-
-
-
-
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
在 VMware ESX、Linux KVM 和 Citrix Hypervisor 上优化 NetScaler VPX 性能
NetScaler VPX 的性能因虚拟机管理程序、分配的系统资源和主机配置而异。要获得所需的性能,请首先遵循 VPX 数据手册中的建议,然后使用本文档中提供的最佳实践进一步优化它。
VMware ESX 虚拟机管理程序上的 NetScaler VPX 实例
本部分包含可配置选项和设置的详细信息,以及其他有助于您在 VMware ESX 虚拟机管理程序上实现 NetScaler VPX 实例的最佳性能的建议。
- ESX 主机上的推荐配置
- 带有 E1000 网络接口的 NetScaler VPX
- 带有 VMXNET3 网络接口的 NetScaler VPX
- 具有 SR-IOV 和 PCI 直通网络接口的 NetScaler VPX
ESX 主机上的推荐配置
要使用 E1000、VMXNET3、SR-IOV 和 PCI 直通网络接口实现 VPX 的高性能,请遵循以下建议:
- ESX 主机上预配的虚拟 CPU (vCPU) 总数必须小于或等于 ESX 主机上的物理 CPU (PCU) 总数。
-
必须为 ESX 主机设置非统一内存访问 (NUMA) 关联性和 CPU 关联性才能获得良好结果。
— 要查找 Vmnic 的 NUMA 关联性,请在本地或远程登录到主机,然后键入:
#vsish -e get /net/pNics/vmnic7/properties | grep NUMA Device NUMA Node: 0 <!--NeedCopy-->- 要为虚拟机设置 NUMA 和 vCPU 关联性,请参阅 VMware 文档。
带有 E1000 网络接口的 NetScaler VPX
在 VMware ESX 主机上执行以下设置:
- 在 VMware ESX 主机上,从一台 pNIC 虚拟交换机创建两个虚拟网卡。多个 vNIC 在 ESX 主机中创建多个接收 (Rx) 线程。这会增加 pNIC 接口的 Rx 吞吐量。
- 在 vSwitch 端口组级别为已创建的每个虚拟网卡启用 VLAN。
- 要提高 vNIC 传输 (Tx) 吞吐量,请在每个 vNIC 的 ESX 主机中使用单独的 Tx 线程。使用以下 ESX 命令:
-
对于 ESX 版本 5.5:
esxcli system settings advanced set –o /Net/NetTxWorldlet –i <!--NeedCopy--> -
对于 ESX 6.0 之后的版本:
esxcli system settings advanced set -o /Net/NetVMTxType –i 1 <!--NeedCopy-->
-
-
要进一步提高 vNIC Tx 吞吐量,请使用单独的 Tx 完成线程和每个设备的接收线程 (NIC) 队列。使用以下 ESX 命令:
esxcli system settings advanced set -o /Net/NetNetqRxQueueFeatPairEnable -i 0 <!--NeedCopy-->
注意:
确保重新启动 VMware ESX 主机以应用更新后的设置。
每个 pNIC 部署两个 vNIC
以下是 每个 pNIC 部署两个 vNIC 模型的示例拓扑和配置命令,可提供更好的网络性能。
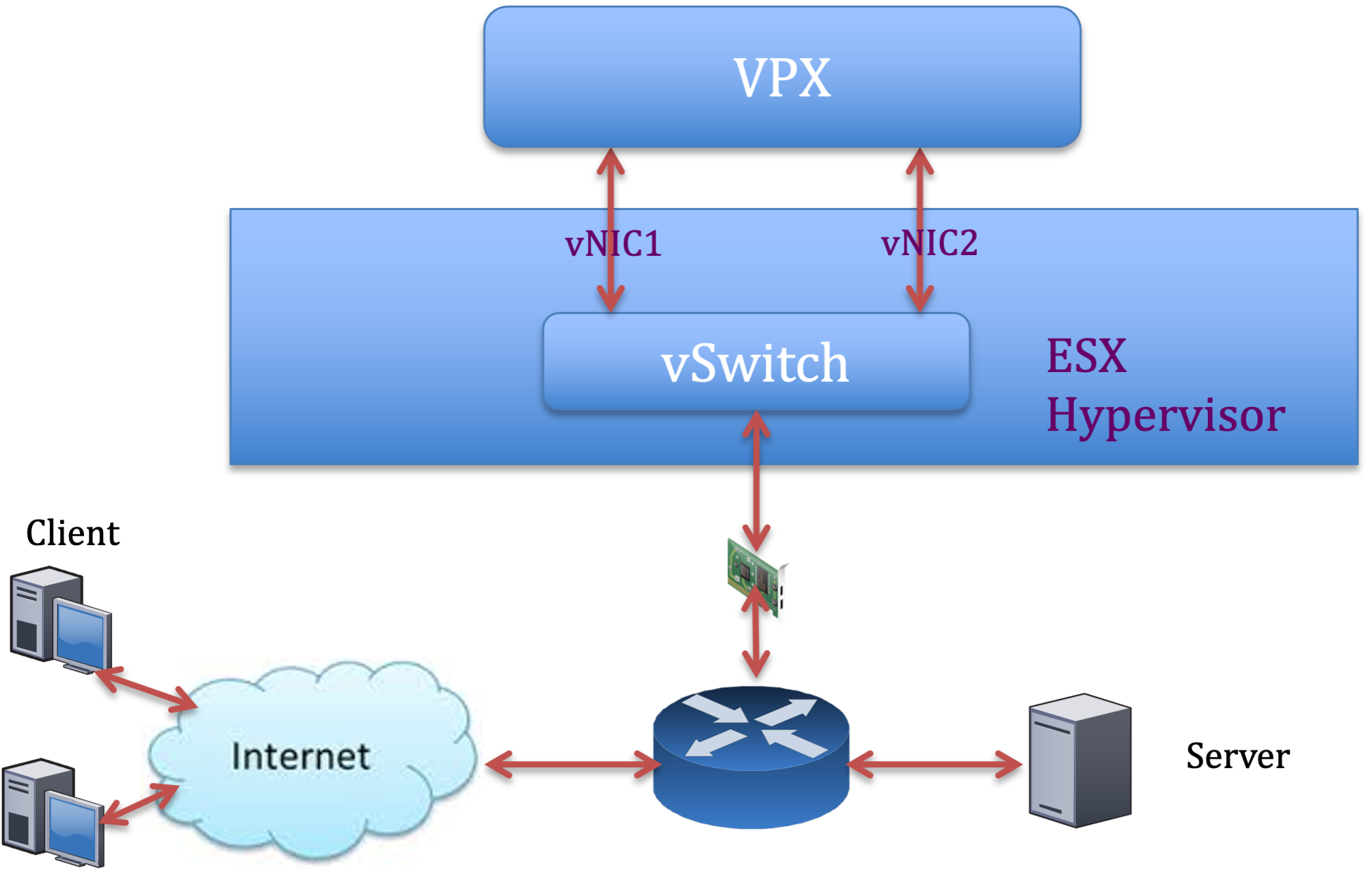
NetScaler VPX 示例配置:
要实现上述示例拓扑中显示的部署,请在 NetScaler VPX 实例上执行以下配置:
-
在客户端,将 SNIP (1.1.1.2) 绑定到网络接口 1/1 并启用 VLAN 标记模式。
bind vlan 2 -ifnum 1/1 –tagged bind vlan 2 -IPAddress 1.1.1.2 255.255.255.0 <!--NeedCopy--> -
在服务器端,将 SNIP (2.2.2.2) 绑定到网络接口 1/1 并启用 VLAN 标记模式。
bind vlan 3 -ifnum 1/2 –tagged bind vlan 3 -IPAddress 2.2.2.2 255.255.255.0 <!--NeedCopy--> -
添加 HTTP 虚拟服务器 (1.1.1.100) 并将其绑定到服务 (2.2.2.100)。
add lb vserver v1 HTTP 1.1.1.100 80 -persistenceType NONE -Listenpolicy None -cltTimeout 180 add service s1 2.2.2.100 HTTP 80 -gslb NONE -maxClient 0 -maxReq 0 -cip DISABLED -usip NO -useproxyport YES -sp ON -cltTimeout 180 -svrTimeout 360 -CKA NO -TCPB NO -CMP NO bind lb vserver v1 s1 <!--NeedCopy-->
注意:
确保在路由表中包含以下两个条目:
- 1.1.1.0/24 子网的网关指向 SNIP 1.1.1.2
- 2.2.2.0/24 子网的网关指向 SNIP 2.2.2.2
带有 VMXNET3 网络接口的 NetScaler VPX
要使用 VMXNET3 网络接口实现 VPX 的高性能,请在 VMware ESX 主机上执行以下设置:
- 从一台 pNIC vSwitch 创建两个虚拟网卡。多个虚拟网卡在 ESX 主机中创建多个 Rx 线程。这会增加 pNIC 接口的 Rx 吞吐量。
- 在 vSwitch 端口组级别为已创建的每个虚拟网卡启用 VLAN。
- 要提高 vNIC 传输 (Tx) 吞吐量,请在每个 vNIC 的 ESX 主机中使用单独的 Tx 线程。使用以下 ESX 命令:
- 对于 ESX 版本 5.5:
esxcli system settings advanced set –o /Net/NetTxWorldlet –i <!--NeedCopy-->- 对于 ESX 6.0 之后的版本:
esxcli system settings advanced set -o /Net/NetVMTxType –i 1 <!--NeedCopy-->
在 VMware ESX 主机上,执行以下配置:
- 在 VMware ESX 主机上,从一台 pNIC 虚拟交换机创建两个虚拟网卡。多个虚拟网卡在 ESX 主机中创建多个 Tx 和 Rx 线程。这会增加 pNIC 接口的 Tx 和 Rx 吞吐量。
- 在 vSwitch 端口组级别为已创建的每个虚拟网卡启用 VLAN。
-
要增加 vNIC 的 Tx 吞吐量,请使用单独的 Tx 完成线程和每个设备的接收线程 (NIC) 队列。使用以下命令:
esxcli system settings advanced set -o /Net/NetNetqRxQueueFeatPairEnable -i 0 <!--NeedCopy--> -
通过将以下设置添加到虚拟机的配置中,将虚拟机配置为每个 vNIC 使用一个传输线程:
ethernetX.ctxPerDev = "1" <!--NeedCopy--> -
通过在虚拟机的配置中添加以下设置,将虚拟机配置为每个 vNIC 最多使用 8 个传输线程:
ethernetX.ctxPerDev = "3" <!--NeedCopy-->注意:
增加每个 vNIC 的传输线程需要在 ESX 主机上使用更多 CPU 资源(最多 8 个)。在进行上述设置之前,请确保有足够的 CPU 资源可用。
有关更多信息,请参阅 vSphere 中 Telco 和 NFV 工作负载性能调整的最佳做法
注意:
确保重新启动 VMware ESX 主机以应用更新后的设置。
您可以将 VMXNET3 配置为 每个 pNIC 部署两个虚拟 网卡。有关详细信息,请参阅 每个 pNIC 部署两个 vNIC。
在 VMware ESX 上为 VMXNET3 设备配置多队列和 RSS 支持
默认情况下,VMXNET3 设备仅支持 8 个 Rx 和 Tx 队列。当 VPX 上的 vCPU 数量超过 8 时,默认情况下,为 VMXNET3 接口配置的 Rx 和 Tx 队列数量会切换为 1。通过更改 ESX 上的某些配置,您可以为 VMXNET3 设备配置多达 19 个 Rx 和 Tx 队列。此选项可提高数据包在 VPX 实例的 vCPU 间的性能和均匀分布。
注意:
从 NetScaler 版本 13.1 build 48.x 开始,NetScaler VPX 在 ESX 上支持多达 19 个 VMXNET3 设备的 Rx 和 Tx 队列。
必备条件:
要在 ESX 上为 VMXNET3 设备配置多达 19 个 Rx 和 Tx 队列,请确保满足以下先决条件:
- NetScaler VPX 版本是 13.1 版本 48.X 及更高版本。
- NetScaler VPX 配置了硬件版本 17 及更高版本的虚拟机,VMware ESX 7.0 及更高版本支持该虚拟机。
将 VMXNET3 接口配置为支持 8 个以上的 Rx 和 Tx 队列:
- 打开虚拟机配置文件 (.vmx) 文件。
-
通过配置和
ethernetX.maxRxQueues值来指定 Rx 和 TX 队列的ethernetX.maxTxQueues数量(其中 X 是要配置的虚拟 NIC 的数量)。配置的最大队列数不得大于虚拟机中的 vCPU 数量。注意:
增加队列数量还会增加 ESX 主机的处理器开销。因此,在增加队列之前,请确保 ESX 主机中有足够的 CPU 资源可用。在队列数量被确定为性能瓶颈的情况下,您可以增加支持的最大队列数。在这些情况下,我们建议逐渐增加队列数量。例如,从 8 到 12,然后是 16,然后是 20,依此类推。评估每种设置下的性能,而不是直接提高到最大限制。
具有 SR-IOV 和 PCI 直通网络接口的 NetScaler VPX
要通过 SR-IOV 和 PCI 直通网络接口实现 VPX 的高性能,请参阅 ESX 主机上的推荐配置。
VMware ESXi 虚拟机管理程序的使用指南
-
我们建议您在服务器的本地磁盘或基于 SAN 的存储卷上部署 VPX 实例。
请参阅 VMware vSphere 6.5 性能最佳实践文档中的 VMware ESXi CPU 注意事项部分。下面是一段摘录:
-
不建议在过度使用的主机或群集上部署 CPU 或内存需求高的虚拟机。
-
在大多数环境中,ESXi 允许大量 CPU 过载,而不会影响虚拟机性能。在主机上,您可以运行的 vCPU 数量超过该主机中的物理处理器核心总数。
-
如果 ESXi 主机变得 CPU 饱和,即主机上的虚拟机和其他负载需要主机拥有的所有 CPU 资源,则延迟敏感型工作负载可能无法良好运行。在这种情况下,例如,通过关闭某些虚拟机或将其迁移到其他主机(或允许 DRS 自动迁移它们)来降低 CPU 负载。
-
NetScaler 建议使用最新的硬件兼容版本来为虚拟机使用 ESXi 虚拟机管理程序的最新功能集。有关硬件和 ESXi 版本兼容性的更多信息,请参阅 VMware 文档。
-
NetScaler VPX 是一款延迟敏感的高性能虚拟设备。为了提供预期的性能,该设备需要在主机上预留 vCPU、内存预留和 vCPU 固定。此外,必须在主机上禁用超线程。如果主机不满足这些要求,则可能会出现以下问题:
- 高可用性故障转移
- VPX 实例内的 CPU 峰值
- 访问 VPX CLI 时运行缓慢
- Pit boss 守护程序崩溃
- 数据包丢失
- 低吞吐量
-
如果满足以下两个条件之一,虚拟机管理程序将被视为过度预配:
-
在主机上配置的虚拟核心 (vCPU) 总数大于物理核心 (pCPU) 总数。
-
预配的 VM 总数占用的 vCPU 数量超过 pCPU 总数。
如果实例配置过度,虚拟机管理程序可能无法保证为实例预留的资源(例如 CPU、内存和其他资源),原因是管理程序计划开销、错误或管理程序的限制。 这种行为可能导致 NetScaler 缺乏 CPU 资源,并可能导致使用指南下第一点中提到的问题。我们建议管理员减少主机的租期,使主机上配置的 vCPU 总数小于或等于 PCPU 的总数。
示例:
对于 ESX 虚拟机管理程序,如果
esxtop命令输出中 VPX vCPU 的%RDY%参数大于 0,则说 ESX 主机存在调度开销,这可能会导致 VPX 实例出现延迟相关问题。在这种情况下,请减少主机上的租赁,以便
%RDY%始终返回 0。或者,联系虚拟机管理程序供应商,对不履行资源预留的原因进行分类。
-
控制数据包引擎 CPU 使用率的命令
您可以使用两个命令(set ns vpxparam 和 show ns vpxparam)来控制虚拟机管理程序和云环境中 VPX 实例的数据包引擎(非管理)CPU 使用行为:
-
set ns vpxparam [-cpuyield (YES | NO | DEFAULT)] [-masterclockcpu1 (YES | NO)]允许每个 VM 使用分配给另一个 VM 但未被使用的 CPU 资源。
Set ns vpxparam参数:-cpuyield:释放或不释放已分配但未使用的 CPU 资源。
-
YES:允许另一个 VM 使用已分配但未使用的 CPU 资源。
-
否:为分配的虚拟机保留所有 CPU 资源。此选项显示,在虚拟机管理程序和云环境中,VPX CPU 使用率的百分比更高。
-
DEFAULT:No。
注意:
在所有 NetScaler VPX 平台上,主机系统上的 vCPU 使用率为 100%。使用
set ns vpxparam –cpuyield YES命令覆盖此用法。如果要将群集节点设置为“yield”,则必须在 CCO 上执行以下额外配置:
- 如果形成群集,则所有节点都设置为“yield=DEFAULT”。
- 如果使用已设置为“yield=YES”的节点组成群集,则使用“DEFAULT”收益率将节点添加到群集中。
注意:
如果要将群集节点设置为“yield=YES”,则只能在形成群集之后进行配置,而不能在群集形成之前进行配置。
-masterclockcpu1:可以将主时钟源从 CPU0(管理 CPU)移动到 CPU1。此参数具有以下选项:
-
是:允许虚拟机将主时钟源从 CPU0 移动到 CPU1。
-
NO:VM 使用 CPU0 作为主时钟源。默认情况下,CPU0 是主时钟源。
-
-
show ns vpxparam此命令显示当前
vpxparam设置。
Linux-KVM 平台上的 NetScaler VPX 实例
本部分包含可配置选项和设置的详细信息,以及其他有助于您在 Linux-KVM 平台上实现 NetScaler VPX 实例的最佳性能的建议。
KVM 的性能设置
在 KVM 主机上执行以下设置:
使用以下 lstopo 命令查找网卡的 NUMA 域:
确保 VPX 和 CPU 的内存固定在同一位置。 在以下输出中,10G 网卡“ens2”与 NUMA 域 #1 关联。
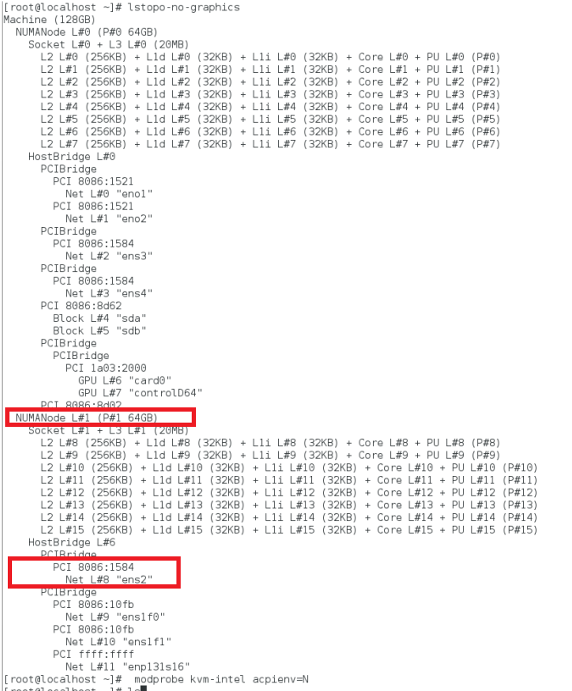
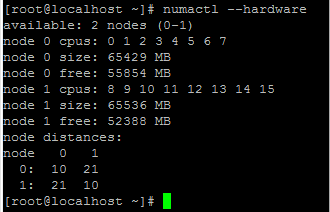
从 NUMA 域分配 VPX 内存。
该 numactl 命令指示从中分配内存的 NUMA 域。在以下输出中,从 NUMA 节点 #0 分配了大约 10 GB 的 RAM。
要更改 NUMA 节点映射,请执行以下步骤。
-
在主机上编辑 VPX 的 .xml。
/etc/libvirt/qemu/<VPX_name>.xml <!--NeedCopy--> -
添加以下标签:
<numatune> <memory mode="strict" nodeset="1"/> This is the NUMA domain name </numatune> <!--NeedCopy--> -
关闭 VPX。
-
运行以下命令:
virsh define /etc/libvirt/qemu/<VPX_name>.xml <!--NeedCopy-->此命令使用 NUMA 节点映射更新 VM 的配置信息。
-
打开 VPX 的电源。然后检查主机上的
numactl –hardware命令输出以查看 VPX 的更新内存分配。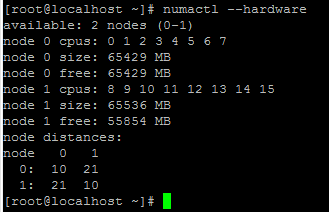
将 VPX 的 vCPU 固定到物理内核。
-
要查看 VPX 的 vCPU 到 pCPU 的映射,请键入以下命令
virsh vcpupin <VPX name> <!--NeedCopy-->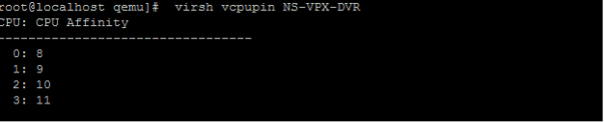
vCPU 0—4 映射到物理内核 8—11。
-
要查看当前的 pCPU 使用情况,请键入以下命令:
mpstat -P ALL 5 <!--NeedCopy-->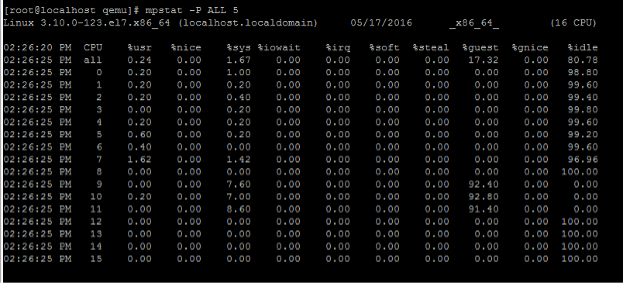
在此输出中,8 是管理 CPU,9—11 是数据包引擎。
-
要将 vCPU 更改为 PCU 固定,有两个选项。
-
使用以下命令在 VPX 启动后在运行时更改它:
virsh vcpupin <VPX name> <vCPU id> <pCPU number> virsh vcpupin NetScaler-VPX-XML 0 8 virsh vcpupin NetScaler-VPX-XML 1 9 virsh vcpupin NetScaler-VPX-XML 2 10 virsh vcpupin NetScaler-VPX-XML 3 11 <!--NeedCopy--> -
要对 VPX 进行静态更改,请使用以下标签像以前一样编辑
.xml文件:-
在主机上编辑 VPX 的 .xml 文件
/etc/libvirt/qemu/<VPX_name>.xml <!--NeedCopy--> -
添加以下标签:
<vcpu placement='static' cpuset='8-11'>4</vcpu> <cputune> <vcpupin vcpu='0' cpuset='8'/> <vcpupin vcpu='1' cpuset='9'/> <vcpupin vcpu='2' cpuset='10'/> <vcpupin vcpu='3' cpuset='11'/> </cputune> <!--NeedCopy--> -
关闭 VPX。
-
使用以下命令使用 NUMA 节点映射更新 VM 的配置信息:
virsh define /etc/libvirt/qemu/ <VPX_name>.xml <!--NeedCopy--> -
打开 VPX 的电源。然后检查主机上的
virsh vcpupin <VPX name>命令输出以查看更新的 CPU 固定。
-
-
消除主机中断开销。
-
使用
kvm_stat命令检测 VM_EXITS。在虚拟机管理程序级别,主机中断映射到固定 VPX vCPU 的相同 PCU。这可能会导致 VPX 上的 vCPU 定期被踢出。
要查找运行主机的虚拟机完成的 VM 退出,请使用
kvm_stat命令。[root@localhost ~]# kvm_stat -1 | grep EXTERNAL kvm_exit(EXTERNAL_INTERRUPT) 1728349 27738 [root@localhost ~]# <!--NeedCopy-->大小为 1+M 的较高值表示存在问题。
如果存在单个虚拟机,则预期值为 30—100 K。超过该值的值表示存在一个或多个主机中断向量映射到同一个 pCPU。
-
检测主机中断并迁移主机中断。
当您运行“/proc/interrupts”文件的
concatenate命令时,它会显示所有主机中断映射。如果一个或多个活动 IRQ 映射到同一个 PCU,则其对应的计数器会增加。将与 NetScaler VPX 的 PCU 重叠的所有中断移动到未使用的 PCU 中:
echo 0000000f > /proc/irq/55/smp_affinity 0000000f - - > it is a bitmap, LSBs indicates that IRQ 55 can only be scheduled on pCPUs 0 – 3 <!--NeedCopy--> -
禁用 IRQ 余额。
禁用 IRQ 余额守护进程,这样即时不会进行重新安排。
service irqbalance stop service irqbalance show - To check the status service irqbalance start - Enable if needed <!--NeedCopy-->确保运行
kvm_stat命令以确保计数器不多。
具有光伏网络接口的 NetScaler VPX
您可以将半虚拟化 (PV)、SR-IOV 和 PCIe 直通网络接口配置为 每个 PNIC 部署两个 vNIC 。有关详细信息,请参阅 每个 pNIC 部署两个 vNIC。
要获得 PV (virtio) 接口的最佳性能,请执行以下步骤:
- 确定 PCIe 插槽/网卡所属的 NUMA 域。
- VPX 的内存和 vCPU 必须固定到同一个 NUMA 域。
- 虚拟主机线程必须绑定到同一 NUMA 域中的 CPU。
将虚拟主机线程绑定到相应的 CPU:
-
流量启动后,在主机上运行
top命令。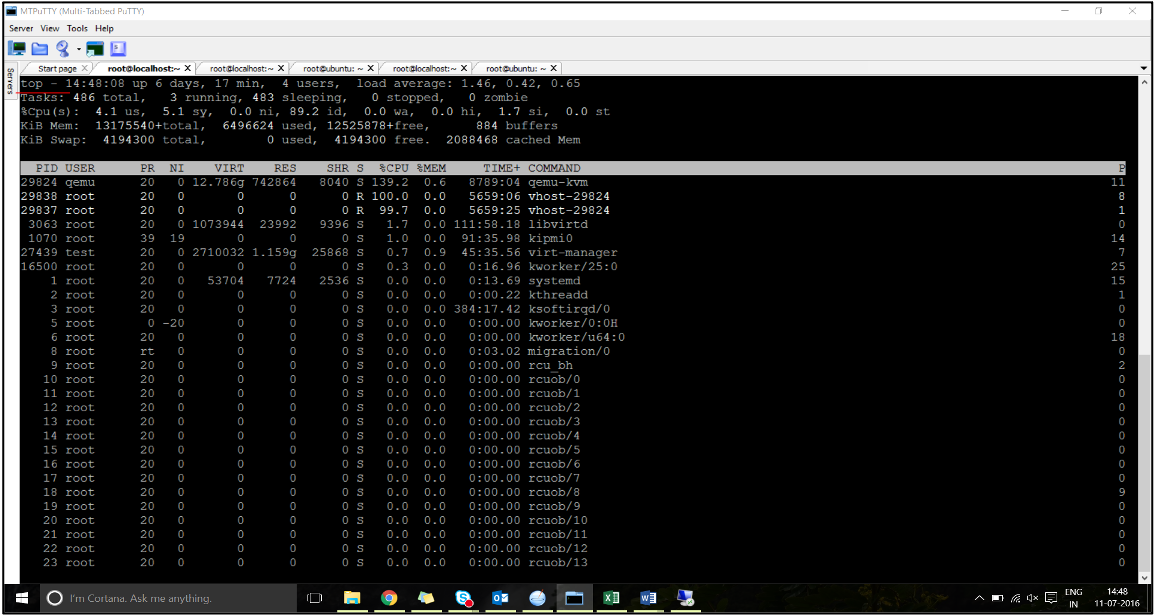
- 确定虚拟主机进程(命名为
vhost-<pid-of-qemu>)关联性。 -
使用以下命令将 vHost 进程绑定到之前确定的 NUMA 域中的物理核心:
taskset –pc <core-id> <process-id> <!--NeedCopy-->示例:
taskset –pc 12 29838 <!--NeedCopy--> -
可以使用以下命令识别与 NUMA 域对应的处理器内核:
[root@localhost ~]# virsh capabilities | grep cpu <cpu> </cpu> <cpus num='8'> <cpu id='0' socket_id='0' core_id='0' siblings='0'/> <cpu id='1' socket_id='0' core_id='1' siblings='1'/> <cpu id='2' socket_id='0' core_id='2' siblings='2'/> <cpu id='3' socket_id='0' core_id='3' siblings='3'/> <cpu id='4' socket_id='0' core_id='4' siblings='4'/> <cpu id='5' socket_id='0' core_id='5' siblings='5'/> <cpu id='6' socket_id='0' core_id='6' siblings='6'/> <cpu id='7' socket_id='0' core_id='7' siblings='7'/> </cpus> <cpus num='8'> <cpu id='8' socket_id='1' core_id='0' siblings='8'/> <cpu id='9' socket_id='1' core_id='1' siblings='9'/> <cpu id='10' socket_id='1' core_id='2' siblings='10'/> <cpu id='11' socket_id='1' core_id='3' siblings='11'/> <cpu id='12' socket_id='1' core_id='4' siblings='12'/> <cpu id='13' socket_id='1' core_id='5' siblings='13'/> <cpu id='14' socket_id='1' core_id='6' siblings='14'/> <cpu id='15' socket_id='1' core_id='7' siblings='15'/> </cpus> <cpuselection/> <cpuselection/> <!--NeedCopy-->
将 QEMU 进程绑定到相应的物理核心:
- 确定运行 QEMU 进程的物理核心。有关更多信息,请参阅前面的输出。
-
使用以下命令将 QEMU 进程绑定到与 vCPU 绑定到的相同物理核心:
taskset –pc 8-11 29824 <!--NeedCopy-->
配备 SR-IOV 和福特维尔 PCIe 直通网络接口的 NetScaler VPX
为了使 SR-IOV 和 Fortville PCIe 直通网络接口达到最佳性能,请执行以下步骤:
- 确定 PCIe 插槽/网卡所属的 NUMA 域。
- VPX 的内存和 vCPU 必须固定到同一个 NUMA 域。
适用于 vCPU 和 Linux KVM 的内存固定的示例 VPX XML 文件:
<domain type='kvm'>
<name>NetScaler-VPX</name>
<uuid>138f7782-1cd3-484b-8b6d-7604f35b14f4</uuid>
<memory unit='KiB'>8097152</memory>
<currentMemory unit='KiB'>8097152</currentMemory>
<vcpu placement='static'>4</vcpu>
<cputune>
<vcpupin vcpu='0' cpuset='8'/>
<vcpupin vcpu='1' cpuset='9'/>
<vcpupin vcpu='2' cpuset='10'/>
<vcpupin vcpu='3' cpuset='11'/>
</cputune>
<numatune>
<memory mode='strict' nodeset='1'/>
</numatune>
</domain>
<!--NeedCopy-->
Citrix Hypervisor 上的 NetScaler VPX 实例
本部分包含可配置选项和设置的详细信息,以及可帮助您在 Citrix Hypervisor 上实现 NetScaler VPX 实例的最佳性能的其他建议。
Citrix Hypervisor 的性能设置
使用“xl”命令查找网卡的 NUMA 域:
xl info -n
<!--NeedCopy-->
将 VPX 的 vCPU 固定到物理内核。
xl vcpu-pin <Netsclaer VM Name> <vCPU id> <physical CPU id>
<!--NeedCopy-->
检查 vCPU 的绑定情况。
xl vcpu-list
<!--NeedCopy-->
向 NetScaler 虚拟机分配 8 个以上的 vCPU。
要配置 8 个以上的 vCPU,请从 Citrix Hypervisor 控制台运行以下命令:
xe vm-param-set uuid=your_vms_uuid VCPUs-max=16
xe vm-param-set uuid=your_vms_uuid VCPUs-at-startup=16
<!--NeedCopy-->
具有 SR-IOV 网络接口的 NetScaler VPX
为了使 SR-IOV 网络接口获得最佳性能,请执行以下步骤:
- 确定 PCIe 插槽或网卡所绑定的 NUMA 域。
- 将 VPX 的内存和 vCPU 固定到同一个 NUMA 域。
- 将域 0 vCPU 绑定到剩余的 CPU。
具有半虚拟化接口的 NetScaler VPX
为获得最佳性能,建议与其他半虚拟环境一样,每个 pNIC 配置两个 vNIC 和每个 pNIC 配置一个 vNIC。
要实现半虚拟化(netfront)接口的最佳性能,请执行以下步骤:
- 确定 PCIe 插槽或 NIC 所属的 NUMA 域。
- 将 VPX 的内存和 vCPU 固定到同一个 NUMA 域。
- 将域 0 vCPU 绑定到同一 NUMA 域的剩余 CPU。
- 将 vNIC 的主机 Rx/Tx 线程固定到域 0 vCPU。
将主机线程固定到 Domain-0 vCPU:
- 使用 Citrix Hypervisor 主机 shell 上的
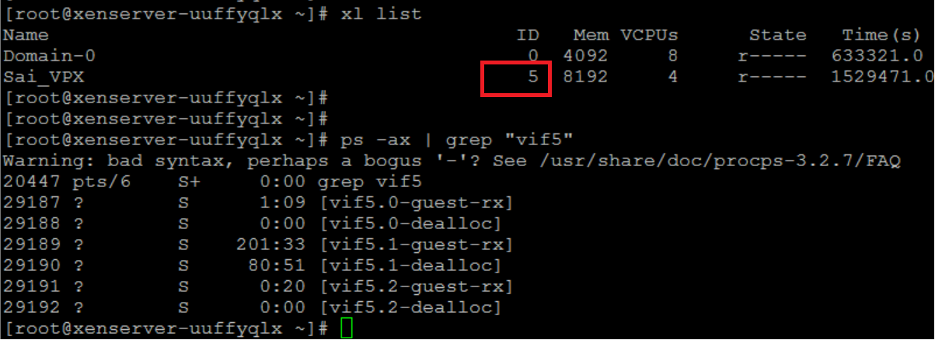
xl list命令查找 VPX 的 Xen-ID。 -
使用以下命令识别主机线程:
ps -ax | grep vif <Xen-ID> <!--NeedCopy-->在以下示例中,这些值表示:
- vif5.0 -在 XenCenter 中分配给 VPX 的第一个接口的线程(管理接口)。
- vif5.1 -分配给 VPX 的第二个接口的线程等等。
-
使用以下命令将线程固定到 Domain-0 vCPU:
taskset –pc <core-id> <process-id> <!--NeedCopy-->示例:
taskset -pc 1 29189 <!--NeedCopy-->
共享
共享
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.