-
-
-
VMware ESX、Linux KVM、およびCitrix HypervisorでNetScaler ADC VPXのパフォーマンスを最適化する
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
VMware ESX、Linux KVM、およびCitrix HypervisorでNetScaler ADC VPXのパフォーマンスを最適化する
NetScaler VPXのパフォーマンスは、ハイパーバイザー、割り当てられたシステムリソース、およびホスト構成によって大きく異なります。望ましいパフォーマンスを達成するには、まずVPXデータシートの推奨事項に従ってから、このドキュメントに記載されているベストプラクティスを使用してさらに最適化します。
VMware ESXハイパーバイザー上のNetScaler ADC VPXインスタンス
このセクションでは、構成可能なオプションと設定、およびVMware ESXハイパーバイザー上のNetScaler ADC VPXインスタンスの最適なパフォーマンスを実現するのに役立つその他の推奨事項について説明します。
- ESX ホストでの推奨構成
- E1000ネットワークインターフェイスを備えたNetScaler ADC VPX
- VMXNET3ネットワークインターフェイスを備えたNetScaler ADC VPX
- SR-IOVおよびPCIパススルーネットワークインターフェイスを備えたNetScaler ADC VPX
ESX ホストでの推奨構成
E1000、VMXNET3、SR-IOV、およびPCIパススルーネットワークインターフェイスを備えたVPXで高いパフォーマンスを実現するには、次の推奨事項に従ってください。
- ESX ホストでプロビジョニングされる仮想 CPU (vCPU) の総数は、ESX ホストの物理 CPU (pCPU) の総数以下である必要があります。
-
ESX ホストで良好な結果を得るには、非均一メモリアクセス (NUMA) アフィニティと CPU アフィニティを設定する必要があります。
— Vmnic の NUMA アフィニティを見つけるには、ローカルまたはリモートでホストにログインし、次のように入力します。
#vsish -e get /net/pNics/vmnic7/properties | grep NUMA Device NUMA Node: 0 <!--NeedCopy-->- 仮想マシンの NUMA および vCPU アフィニティを設定するには、 VMware のドキュメントを参照してください。
E1000ネットワークインターフェイスを備えたNetScaler ADC VPX
VMware ESX ホストで次の設定を実行します。
- VMware ESX ホストで、1 つの物理 vSwitch から 2 つの vNIC を作成します。複数の vNIC は、ESX ホストに複数の受信 (Rx) スレッドを作成します。これにより、物理 NIC インターフェイスの Rx スループットが向上します。
- 作成した各 vNIC の vSwitch ポートグループレベルで VLAN を有効にします。
- vNIC 送信(Tx)スループットを向上させるには、vNIC ごとに ESX ホストで別の Tx スレッドを使用します。次の ESX コマンドを使用します。
-
ESX バージョン 5.5 の場合:
esxcli system settings advanced set –o /Net/NetTxWorldlet –i <!--NeedCopy--> -
ESX バージョン 6.0 以降の場合:
esxcli system settings advanced set -o /Net/NetVMTxType –i 1 <!--NeedCopy-->
-
-
vNIC Tx スループットをさらに高めるには、別の Tx 完了スレッドと、デバイス(NIC)キューごとの Rx スレッドを使用します。次の ESX コマンドを使用します。
esxcli system settings advanced set -o /Net/NetNetqRxQueueFeatPairEnable -i 0 <!--NeedCopy-->
注:
VMware ESX ホストを再起動して、更新された設定を適用してください。
物理 NIC 展開ごとに 2 つの vNIC
次に、より優れたネットワークパフォーマンスを提供する展開の pNIC ごとに 2 つの vNIC モデルのトポロジおよび設定コマンドの例を示します。
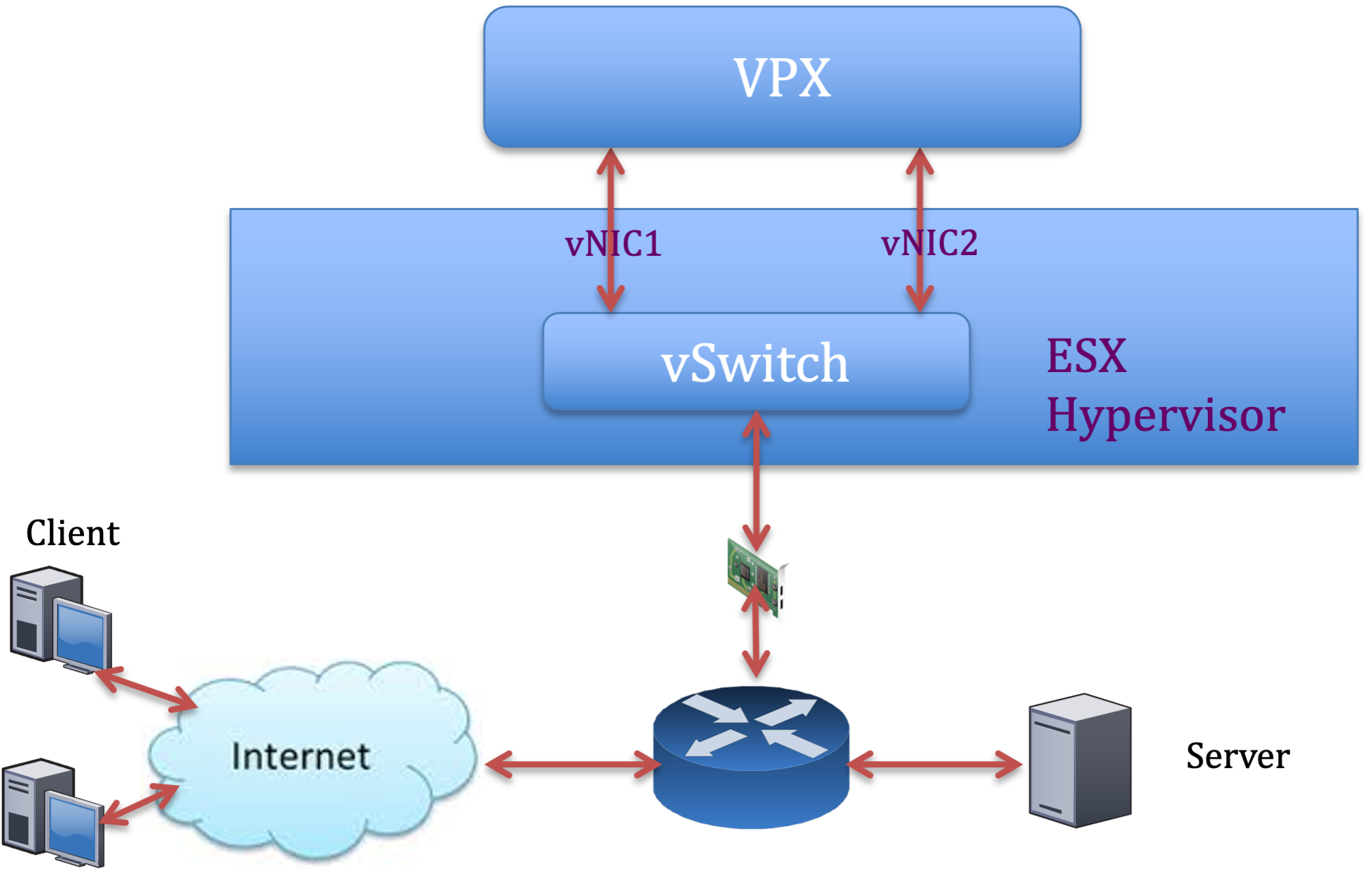
NetScaler VPX構成例:
前のサンプルトポロジに示した展開を実現するには、NetScaler VPXインスタンスで次の構成を実行します。
-
クライアント側で、SNIP(1.1.1.2)をネットワークインターフェイス 1/1 にバインドし、VLAN タグモードを有効にします。
bind vlan 2 -ifnum 1/1 –tagged bind vlan 2 -IPAddress 1.1.1.2 255.255.255.0 <!--NeedCopy--> -
サーバ側で、SNIP(2.2.2.2)をネットワークインターフェイス 1/1 にバインドし、VLAN タグモードを有効にします。
bind vlan 3 -ifnum 1/2 –tagged bind vlan 3 -IPAddress 2.2.2.2 255.255.255.0 <!--NeedCopy--> -
HTTP 仮想サーバー (1.1.1.100) を追加し、サービス (2.2.2.100) にバインドします。
add lb vserver v1 HTTP 1.1.1.100 80 -persistenceType NONE -Listenpolicy None -cltTimeout 180 add service s1 2.2.2.100 HTTP 80 -gslb NONE -maxClient 0 -maxReq 0 -cip DISABLED -usip NO -useproxyport YES -sp ON -cltTimeout 180 -svrTimeout 360 -CKA NO -TCPB NO -CMP NO bind lb vserver v1 s1 <!--NeedCopy-->
注:
ルートテーブルに次の 2 つのエントリが含まれていることを確認します。
- 1.1.1.0/24 SNIP 1.1.1.2 を指すゲートウェイを持つサブネット
- 2.2.2.0/24 SNIP 2.2.2.2 を指すゲートウェイを持つサブネット
VMXNET3ネットワークインターフェイスを備えたNetScaler ADC VPX
VMXNET3 ネットワークインターフェイスを使用した VPX で高いパフォーマンスを実現するには、VMware ESX ホストで次の設定を行います。
- 1 つの物理 vSwitch から 2 つの vNIC を作成します。複数の vNIC により、ESX ホストに複数の Rx スレッドが作成されます。これにより、物理 NIC インターフェイスの Rx スループットが向上します。
- 作成した各 vNIC の vSwitch ポートグループレベルで VLAN を有効にします。
- vNIC 送信(Tx)スループットを向上させるには、vNIC ごとに ESX ホストで別の Tx スレッドを使用します。次の ESX コマンドを使用します。
- ESX バージョン 5.5 の場合:
esxcli system settings advanced set –o /Net/NetTxWorldlet –i <!--NeedCopy-->- ESX バージョン 6.0 以降の場合:
esxcli system settings advanced set -o /Net/NetVMTxType –i 1 <!--NeedCopy-->
VMware ESX ホストで、次の構成を実行します。
- VMware ESX ホストで、1 つの物理 vSwitch から 2 つの vNIC を作成します。複数の vNIC により、ESX ホストに複数の Tx スレッドと Rx スレッドが作成されます。これにより、物理 NIC インターフェイスの Tx スループットと Rx スループットが向上します。
- 作成した各 vNIC の vSwitch ポートグループレベルで VLAN を有効にします。
-
vNIC の Tx スループットを向上させるには、デバイス(NIC)キューごとの Tx 完了スレッドと受信スレッドを別々に使用します。次のコマンドを使用します:
esxcli system settings advanced set -o /Net/NetNetqRxQueueFeatPairEnable -i 0 <!--NeedCopy--> -
仮想マシンの構成に次の設定を追加して、vNIC ごとに 1 つの送信スレッドを使用するように仮想マシンを設定します。
ethernetX.ctxPerDev = "1" <!--NeedCopy--> -
仮想マシンの構成に次の設定を追加して、vNICあたり最大8つの送信スレッドを使用するように仮想マシンを構成します。
ethernetX.ctxPerDev = "3" <!--NeedCopy-->注:
vNIC あたりの送信スレッド数を増やすと、ESX ホストでより多くの CPU リソース (最大 8 つ) が必要になります。前述の設定を行う前に、十分な CPU リソースが使用可能であることを確認してください。
詳細については、 vSphere の Telco および NFV ワークロードのパフォーマンスチューニングのベストプラクティスを参照してください。
注:
VMware ESX ホストを再起動して、更新された設定を適用してください。
VMXNET3 は、物理 NIC 展開ごとに 2 つの vNIC として設定できます。詳細については、「物理 NIC 展開ごとに 2 つの vNIC」を参照してください。
VMware ESX で VMXNET3 デバイス用のマルチキューと RSS サポートを設定します
デフォルトでは、VMXNET3 デバイスは 8 つの Rx キューと Tx キューのみをサポートします。VPXのvCPUの数が8を超えると、VMXNET3インターフェイスに設定されているRxキューとTxキューの数は、デフォルトで1に切り替わります。ESX の特定の構成を変更することで、VMXNET3 デバイス用に最大 19 個の Rx キューと Tx キューを設定できます。このオプションにより、パフォーマンスが向上し、VPXインスタンスのvCPU間でパケットが均一に分散されます。
注:
NetScalerリリース13.1ビルド48.x以降、NetScaler VPXはVMXNET3デバイスのESX上で最大19個のRxキューとTxキューをサポートします。
前提条件:
ESX で VMXNET3 デバイス用に最大 19 個の Rx キューと Tx キューを構成するには、次の前提条件が満たされていることを確認してください。
- NetScaler VPX バージョンは13.1ビルド48.X以降です。
- NetScaler VPXは、VMware ESX 7.0以降でサポートされているハードウェアバージョン17以降の仮想マシンで構成されます。
8 つ以上の Rx キューと Tx キューをサポートするようにVMXNET3 インターフェイスを設定します。
- 仮想マシンの構成ファイル (.vmx) ファイルを開きます。
-
ethernetX.maxTxQueuesおよびethernetX.maxRxQueuesの値を設定して Rx キューと TX キューの数を指定します(X は設定する仮想 NIC の数)。設定するキューの最大数は、仮想マシンの vCPU 数を超えてはいけません。注:
キューの数を増やすと、ESX ホストのプロセッサオーバーヘッドも増加します。したがって、キューを増やす前に、ESX ホストに十分な CPU リソースがあることを確認してください。キューの数がパフォーマンスのボトルネックになっている場合は、サポートされるキューの最大数を増やすことができます。このような場合は、キューの数を徐々に増やすことをお勧めします。たとえば、8から12、次に16へ、そして20へ、というようになります。最大値まで直接上げるのではなく、各設定でパフォーマンスを評価してください。
SR-IOVおよびPCIパススルーネットワークインターフェイスを備えたNetScaler ADC VPX
SR-IOVおよびPCIパススルーネットワークインターフェイスを備えたVPXで高いパフォーマンスを実現するには、「 ESXホストでの推奨構成」を参照してください。
VMware ESXi ハイパーバイザーの使用ガイドライン
-
VPXインスタンスをサーバーのローカルディスクまたはSANベースのストレージボリュームにデプロイすることをお勧めします。
『 VMware vSphere 6.5 のパフォーマンスのベストプラクティス』ドキュメントの「VMware ESXi CPU に関する考慮事項 」セクションを参照してください。ここに抽出があります:
-
CPU またはメモリのデマンドが高い仮想マシンを、オーバーコミットされたホストまたはクラスタにデプロイすることは推奨されません。
-
ほとんどの環境では、ESXiは、仮想マシンのパフォーマンスに影響を与えることなく、かなりのレベルのCPUオーバーコミットメントを許可します。ホストでは、そのホスト内の物理プロセッサコアの総数よりも多くの vCPU を実行できます。
-
ESXi ホストが CPU 飽和状態になった場合、つまり、仮想マシンおよびホスト上のその他の負荷がホストにあるすべての CPU リソースを要求すると、レイテンシの影響を受けやすいワークロードがうまく動作しない可能性があります。この場合、たとえば、一部の仮想マシンをパワーオフするか、別のホストに移行する(または DRS に自動的に移行させる)ことで、CPU 負荷を軽減します。
-
NetScalerでは、仮想マシンでESXiハイパーバイザーの最新の機能セットを利用するには、最新のハードウェア互換性バージョンを使用することをお勧めします。ハードウェアと ESXi のバージョンの互換性に関する詳細については、 VMwareのドキュメントを参照してください。
-
NetScaler VPXは、レイテンシーに敏感で高性能な仮想アプライアンスです。期待どおりのパフォーマンスを実現するには、アプライアンスに vCPU の予約、メモリの予約、および vCPU のホストへのピンニングが必要です。また、ホスト上でハイパースレッディングを無効にする必要があります。ホストがこれらの要件を満たしていない場合、次の問題が発生する可能性があります:
- 高可用性フェイルオーバー
- VPXインスタンス内のCPUスパイク
- VPX CLIへのアクセスが遅い
- ピットボスデーモンクラッシュ
- パケットドロップ
- 低スループット
-
Hypervisor は、次の 2 つの条件のいずれかが満たされると、過剰プロビジョニングと見なされます:
-
ホストにプロビジョニングされた仮想コア (vCPU) の総数が、物理コア (pCPU) の総数を超えています。
-
プロビジョニングされた仮想マシンの合計数は、pCPU の合計数よりも多くの vCPU を消費します。
インスタンスが過剰プロビジョニングされている場合、ハイパーバイザーのスケジューリングオーバーヘッド、バグ、またはハイパーバイザーの制限により、ハイパーバイザーがインスタンスのリザーブドリソース(CPU、メモリなど)を保証しない場合があります。この動作により、NetScalerのCPUリソースが不足し、「 使用上のガイドライン」の最初のポイントで説明した問題が発生する可能性があります。管理者は、ホストにプロビジョニングされた vCPU の総数が PCU の総数以下になるように、ホストのテナンシーを減らすことをお勧めします。
例:
ESXハイパーバイザーの場合、
esxtopコマンド出力でVPX vCPUの%RDY%パラメーターが0より大きい場合、ESXホストにはスケジューリングオーバーヘッドがあると言われ、VPXインスタンスにレイテンシー関連の問題が発生する可能性があります。このような状況では、
%RDY%が常に0に戻るように、ホストのテナンシーを減らします。または、ハイパーバイザーベンダーに連絡して、リソース予約が受け付けられない理由を優先順位付けしてください。
-
パケットエンジンの CPU 使用率を制御するコマンド
ハイパーバイザーおよびクラウド環境における VPX インスタンスのパケットエンジン(非管理)CPU 使用率の動作を制御するには、2 つのコマンド(set ns vpxparamおよびshow ns vpxparam)を使用できます:
-
set ns vpxparam [-cpuyield (YES | NO | DEFAULT)] [-masterclockcpu1 (YES | NO)]各 VM が、別の VM に割り当てられているが、使用されていない CPU リソースを使用できるようにします。
Set ns vpxparamパラメータ:-cpuyield: 割り当てられているが未使用の CPU リソースを解放または解放しません。
-
はい:割り当てられているが未使用の CPU リソースを別の VM で使用できるようにします。
-
いいえ:割り当てられた VM のすべての CPU リソースを予約します。このオプションは、ハイパーバイザーおよびクラウド環境でVPX CPU使用率が高いことを示します。
-
デフォルト:いいえ。
注:
すべてのNetScaler VPXプラットフォームで、ホストシステム上のvCPU使用率は 100% です。
set ns vpxparam –cpuyield YESコマンドを使用してこの使用方法を無効にしてください。クラスタノードを「yield」に設定する場合は、CCO で次の追加設定を実行する必要があります:
- クラスターが形成されると、すべてのノードが「yield=DEFAULT」に設定されます。
- すでに「yield=Yes」に設定されたノードを使用してクラスターが形成されている場合、ノードは「DEFAULT」のイールドを使用してクラスターに追加されます。
注:
クラスタノードを「yield=YES」に設定する場合は、クラスタの形成後にのみ構成でき、クラスタが形成される前には設定できません。
-masterclockcpu1: メインクロックソースを CPU0 (管理 CPU) から CPU1 に移動できます。このパラメータには、次のオプションがあります。
-
はい:仮想マシンがメインクロックソースを CPU0 から CPU1 に移動できるようにします。
-
いいえ:VM はメインクロックソースに CPU0 を使用します。デフォルトでは、CPU0 がメインクロックソースです。
-
-
show ns vpxparamこのコマンドは、現在の
vpxparam設定を表示します。
Linux-KVMプラットフォーム上のNetScaler ADC VPXインスタンス
このセクションでは、構成可能なオプションと設定、およびLinux-KVMプラットフォーム上のNetScaler ADC VPXインスタンスの最適なパフォーマンスを達成するのに役立つその他の推奨事項について説明します。
- KVM のパフォーマンス設定
- PVネットワークインターフェイスを備えたNetScaler ADC VPX
- SR-IOVおよびフォートビルのPCIeパススルーネットワークインターフェイスを備えたNetScaler ADC VPX
KVM のパフォーマンス設定
KVM ホストで次の設定を行います。
lstopoコマンドを使用して、NIC の NUMA ドメインを検索します。
VPX と CPU のメモリが同じ場所に固定されていることを確認します。 次の出力では、10G NIC「ens2」は NUMA ドメイン #1 に関連付けられています。
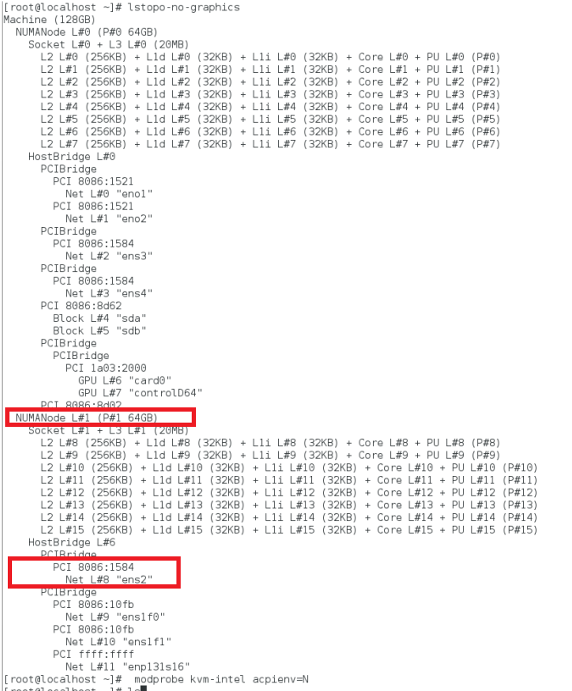
NUMA ドメインから VPX メモリを割り当てます。
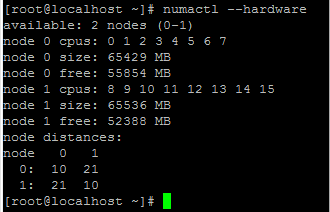
numactlコマンドは、メモリの割り当て元の NUMA ドメインを示します。次の出力では、NUMA ノード #0 から約 10 GB の RAM が割り当てられています。
NUMA ノードマッピングを変更するには、次の手順に従います。
-
ホスト上のVPXの.xmlを編集します。
/etc/libvirt/qemu/<VPX_name>.xml <!--NeedCopy--> -
次のタグを追加します。
<numatune> <memory mode="strict" nodeset="1"/> This is the NUMA domain name </numatune> <!--NeedCopy--> -
VPXをシャットダウンします。
-
次のコマンドを実行します:
virsh define /etc/libvirt/qemu/<VPX_name>.xml <!--NeedCopy-->このコマンドは、NUMA ノードマッピングを使用して VM の構成情報を更新します。
-
VPX の電源をオンにします。次に、ホスト上の
numactl –hardwareコマンド出力を確認して、VPXの更新されたメモリ割り当てを確認します。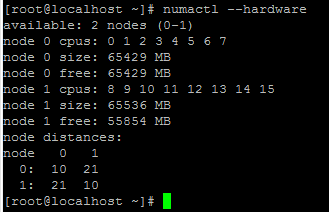
VPX の vCPU を物理コアにピン留めします。
-
VPX の vCPU から pCPU へのマッピングを表示するには、次のコマンドを入力します。
virsh vcpupin <VPX name> <!--NeedCopy-->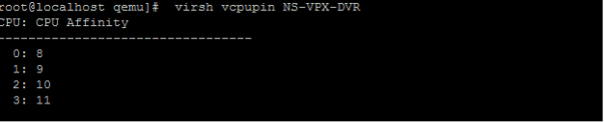
vCPU 0 ~ 4 は物理コア 8 ~ 11 にマッピングされます。
-
現在の pCPU 使用率を表示するには、次のコマンドを入力します。
mpstat -P ALL 5 <!--NeedCopy-->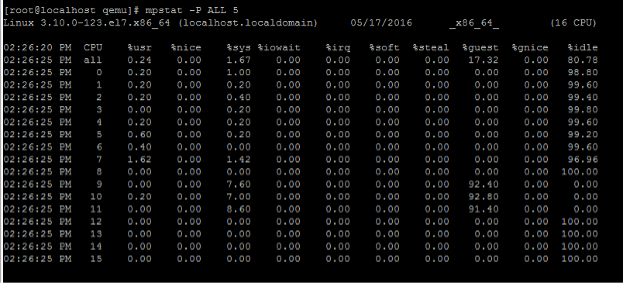
この出力では、8 は管理 CPU、9 ~ 11 はパケットエンジンです。
-
vCPU を pCPU 固定に変更するには、2 つのオプションがあります。
-
次のコマンドを使用して、VPXの起動後に実行時に変更します。
virsh vcpupin <VPX name> <vCPU id> <pCPU number> virsh vcpupin NetScaler-VPX-XML 0 8 virsh vcpupin NetScaler-VPX-XML 1 9 virsh vcpupin NetScaler-VPX-XML 2 10 virsh vcpupin NetScaler-VPX-XML 3 11 <!--NeedCopy--> -
VPXに静的な変更を加えるには、前と同じように次のタグを付けて
.xmlファイルを編集します。-
ホスト上のVPXの.xmlファイルを編集します。
/etc/libvirt/qemu/<VPX_name>.xml <!--NeedCopy--> -
次のタグを追加します。
<vcpu placement='static' cpuset='8-11'>4</vcpu> <cputune> <vcpupin vcpu='0' cpuset='8'/> <vcpupin vcpu='1' cpuset='9'/> <vcpupin vcpu='2' cpuset='10'/> <vcpupin vcpu='3' cpuset='11'/> </cputune> <!--NeedCopy--> -
VPXをシャットダウンします。
-
次のコマンドを使用して、NUMA ノードマッピングを使用して VM の設定情報を更新します。
virsh define /etc/libvirt/qemu/ <VPX_name>.xml <!--NeedCopy--> -
VPX の電源をオンにします。次に、ホスト上の
virsh vcpupin <VPX name>コマンド出力をチェックして、更新された CPU ピン接続を確認します。
-
-
ホスト割り込みオーバーヘッドを排除します。
-
kvm_statコマンドを使用して VM_EXITS を検出します。ハイパーバイザーレベルでは、ホスト割り込みは、VPX の仮想 CPU が固定されているのと同じ pCPU にマッピングされます。これにより、VPX 上の vCPU が定期的に追い出される可能性があります。
ホストを実行している仮想マシンによって実行された VM の終了を確認するには、
kvm_statコマンドを使用します。[root@localhost ~]# kvm_stat -1 | grep EXTERNAL kvm_exit(EXTERNAL_INTERRUPT) 1728349 27738 [root@localhost ~]# <!--NeedCopy-->1+M の順の値が大きいほど、問題があることを示します。
単一の VM が存在する場合、期待値は 30 ~ 100 K です。これ以上の値は、同じ pCPU にマッピングされた 1 つ以上のホスト割り込みベクトルがあることを示している可能性があります。
-
ホスト割り込みを検出し、ホスト割り込みを移行します。
「/proc/interrupts」 ファイルの
concatenateコマンドを実行すると、すべてのホスト割り込みマッピングが表示されます。1 つ以上のアクティブな IRQ が同じ pCPU にマップされている場合、対応するカウンタが増分します。NetScaler VPXのpCPUと重複する割り込みを未使用のpCPUに移動します。
echo 0000000f > /proc/irq/55/smp_affinity 0000000f - - > it is a bitmap, LSBs indicates that IRQ 55 can only be scheduled on pCPUs 0 – 3 <!--NeedCopy--> -
IRQ バランスを無効にします。
IRQ バランスデーモンを無効にして、その場で再スケジュールが実行されないようにします。
service irqbalance stop service irqbalance show - To check the status service irqbalance start - Enable if needed <!--NeedCopy-->必ず
kvm_statコマンドを実行して、カウンタの数が多くないことを確認します。
PVネットワークインターフェイスを備えたNetScaler ADC VPX
準仮想化(PV)、SR-IOV、および PCIe パススルーネットワークインターフェイスは、物理 NIC ごとに 2 つの vNIC 展開として設定できます。詳細については、「物理 NIC 展開ごとに 2 つの vNIC」を参照してください。
PV (virtio) インターフェイスの最適なパフォーマンスを得るには、次の手順に従います。
- PCIe スロット/NIC が属する NUMA ドメインを特定します。
- VPXのメモリとvCPUは、同じNUMAドメインにピン接続する必要があります。
- 仮想ホストスレッドは、同じ NUMA ドメイン内の CPU にバインドする必要があります。
仮想ホストスレッドを対応する CPU にバインドします。
-
トラフィックが開始されたら、ホストで
topコマンドを実行します。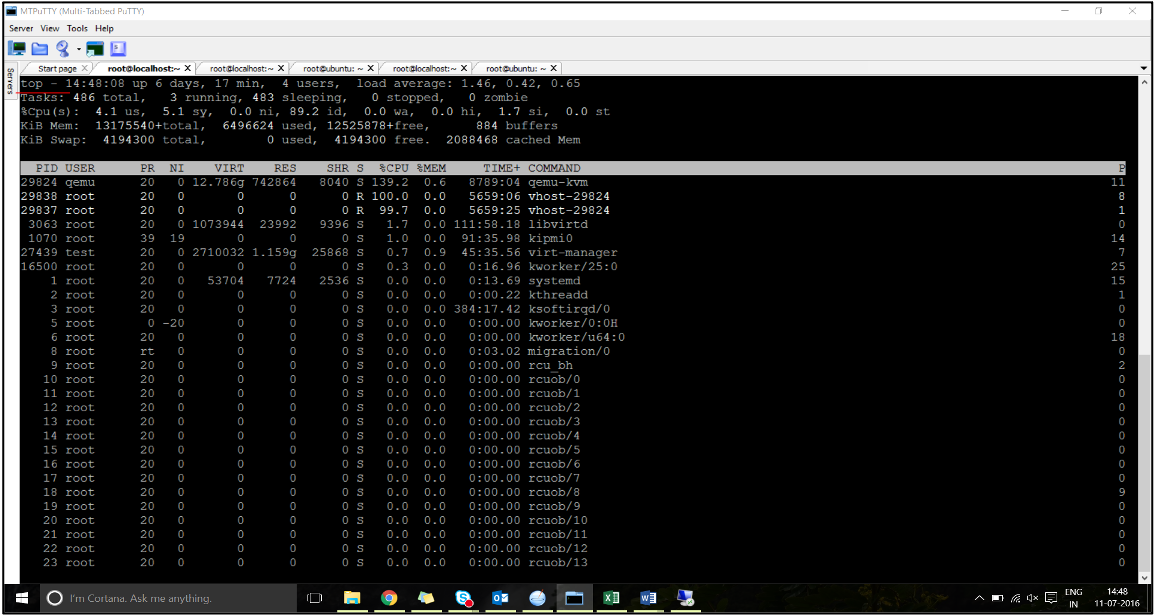
- 仮想ホストプロセス (
vhost-<pid-of-qemu>という名前 ) アフィニティを識別します。 -
次のコマンドを使用して、前に特定した NUMA ドメインの物理コアに vHost プロセスをバインドします。
taskset –pc <core-id> <process-id> <!--NeedCopy-->例:
taskset –pc 12 29838 <!--NeedCopy--> -
NUMA ドメインに対応するプロセッサコアは、次のコマンドで識別できます。
[root@localhost ~]# virsh capabilities | grep cpu <cpu> </cpu> <cpus num='8'> <cpu id='0' socket_id='0' core_id='0' siblings='0'/> <cpu id='1' socket_id='0' core_id='1' siblings='1'/> <cpu id='2' socket_id='0' core_id='2' siblings='2'/> <cpu id='3' socket_id='0' core_id='3' siblings='3'/> <cpu id='4' socket_id='0' core_id='4' siblings='4'/> <cpu id='5' socket_id='0' core_id='5' siblings='5'/> <cpu id='6' socket_id='0' core_id='6' siblings='6'/> <cpu id='7' socket_id='0' core_id='7' siblings='7'/> </cpus> <cpus num='8'> <cpu id='8' socket_id='1' core_id='0' siblings='8'/> <cpu id='9' socket_id='1' core_id='1' siblings='9'/> <cpu id='10' socket_id='1' core_id='2' siblings='10'/> <cpu id='11' socket_id='1' core_id='3' siblings='11'/> <cpu id='12' socket_id='1' core_id='4' siblings='12'/> <cpu id='13' socket_id='1' core_id='5' siblings='13'/> <cpu id='14' socket_id='1' core_id='6' siblings='14'/> <cpu id='15' socket_id='1' core_id='7' siblings='15'/> </cpus> <cpuselection/> <cpuselection/> <!--NeedCopy-->
QEMU プロセスを対応する物理コアにバインドします。
- QEMU プロセスが実行されている物理コアを特定します。詳細については、前述の出力を参照してください。
-
次のコマンドを使用して、vCPU をバインドするのと同じ物理コアに QEMU プロセスをバインドします。
taskset –pc 8-11 29824 <!--NeedCopy-->
SR-IOVおよびフォートビルのPCIeパススルーネットワークインターフェイスを備えたNetScaler ADC VPX
SR-IOV および Fortville PCIe パススルーネットワークインターフェイスのパフォーマンスを最適化するには、次の手順を実行します。
- PCIe スロット/NIC が属する NUMA ドメインを特定します。
- VPX のメモリと vCPU は、同じ NUMA ドメインに固定する必要があります。
Linux KVM の vCPU およびメモリピンニング用のサンプル VPX XML ファイル:
<domain type='kvm'>
<name>NetScaler-VPX</name>
<uuid>138f7782-1cd3-484b-8b6d-7604f35b14f4</uuid>
<memory unit='KiB'>8097152</memory>
<currentMemory unit='KiB'>8097152</currentMemory>
<vcpu placement='static'>4</vcpu>
<cputune>
<vcpupin vcpu='0' cpuset='8'/>
<vcpupin vcpu='1' cpuset='9'/>
<vcpupin vcpu='2' cpuset='10'/>
<vcpupin vcpu='3' cpuset='11'/>
</cputune>
<numatune>
<memory mode='strict' nodeset='1'/>
</numatune>
</domain>
<!--NeedCopy-->
Citrix Hypervisor上のNetScaler ADC VPXインスタンス
このセクションでは、構成可能なオプションと設定、およびCitrix Hypervisors上のNetScaler ADC VPXインスタンスの最適なパフォーマンスを達成するのに役立つその他の推奨事項について説明します。
- Citrix Hypervisorのパフォーマンス設定
- SR-IOVネットワークインターフェイスを備えたNetScaler ADC VPX
- 準仮想化インターフェイスを備えたNetScaler ADC VPX
Citrix Hypervisorのパフォーマンス設定
「xl」コマンドを使用して NIC の NUMA ドメインを見つけます。
xl info -n
<!--NeedCopy-->
VPX の vCPU を物理コアにピン留めします。
xl vcpu-pin <Netsclaer VM Name> <vCPU id> <physical CPU id>
<!--NeedCopy-->
vCPU のバインドをチェックします。
xl vcpu-list
<!--NeedCopy-->
8個を超える仮想CPUをNetScaler ADC仮想マシンに割り当てます。
8個を超える仮想CPUを構成するには、Citrix Hypervisorコンソールから次のコマンドを実行します。
xe vm-param-set uuid=your_vms_uuid VCPUs-max=16
xe vm-param-set uuid=your_vms_uuid VCPUs-at-startup=16
<!--NeedCopy-->
SR-IOVネットワークインターフェイスを備えたNetScaler ADC VPX
SR-IOV ネットワークインターフェイスの最適なパフォーマンスを得るには、次の手順を実行します。
- PCIe スロットまたは NIC が接続されている NUMA ドメインを特定します。
- VPX のメモリと vCPU を同じ NUMA ドメインに固定します。
- ドメイン 0 vCPU を残りの CPU にバインドします。
準仮想化インターフェイスを備えたNetScaler ADC VPX
最適なパフォーマンスを得るには、他の PV 環境と同様に、pNIC ごとに 2 つの vNIC、および pNIC 構成ごとに 1 つの vNIC を推奨します。
準仮想化 (netfront) インターフェイスの最適なパフォーマンスを実現するには、次の手順を実行します。
- PCIe スロットまたは NIC が属する NUMA ドメインを特定します。
- VPX のメモリと vCPU を同じ NUMA ドメインに固定します。
- ドメイン 0 vCPU を同じ NUMA ドメインの残りの CPU にバインドします。
- 仮想 NIC のホスト Rx/Tx スレッドをドメイン 0 vCPU に固定します。
ホストスレッドをドメイン 0 vCPU にピン留めします。
- Citrix Hypervisorホストシェルで
xl listコマンドを使用して、VPXのXen-IDを検索します。 -
次のコマンドを使用して、ホストスレッドを識別します。
ps -ax | grep vif <Xen-ID> <!--NeedCopy-->次の例では、これらの値は次のことを示しています。
- vif5.0 -XenCenterでVPXに割り当てられた最初のインターフェイス(管理インターフェイス)のスレッド。
- vif5.1 -VPXに割り当てられた2番目のインターフェースのスレッドなど。
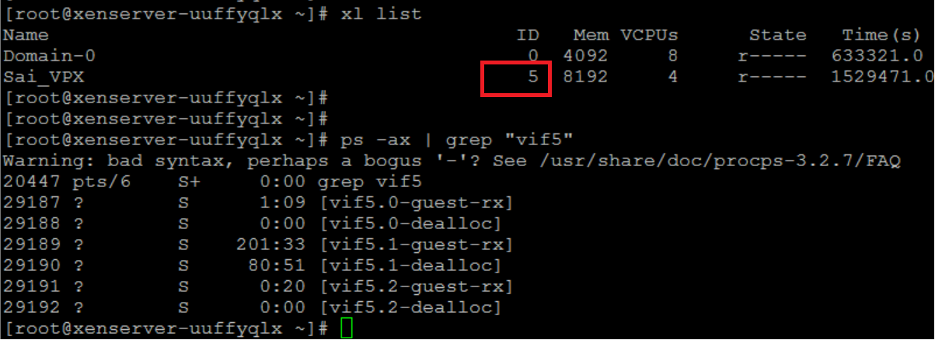
-
次のコマンドを使用して、スレッドをドメイン 0 vCPU に固定します。
taskset –pc <core-id> <process-id> <!--NeedCopy-->例:
taskset -pc 1 29189 <!--NeedCopy-->
共有
共有
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.