-
-
-
NetScaler ADMを使用してNetScalerクラウドネイティブネットワークのトラブルシューティングを行う
-
-
VMware ESX、Linux KVM、およびCitrix HypervisorでNetScaler ADC VPXのパフォーマンスを最適化する
-
-
NetScalerアプライアンスのアップグレードとダウングレード
-
-
-
-
-
-
-
-
-
-
-
-
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
NetScaler コンソールを使用してNetScalerクラウドネイティブネットワークのトラブルシューティングを行います
概要
このドキュメントでは、NetScaler Consoleを使用してKubernetesマイクロサービスアプリケーションを配信および監視する方法について説明します。また、CLI、サービスグラフ、トレースを使用して、プラットフォームと SRE チームがトラブルシューティングを行えるようにする方法についても説明します。
アプリケーションパフォーマンスとレイテンシーの概要
TLS 暗号化
TLS は、インターネット通信を保護するために設計された暗号化プロトコルです。TLS ハンドシェイクは、TLS 暗号化を使用する通信セッションを開始するプロセスです。TLS ハンドシェイク中、2 つの通信側はメッセージを交換して、相互の確認、相互の検証、使用する暗号化アルゴリズムの確立、セッションキーの合意を行います。TLS ハンドシェイクは、HTTPS の仕組みの基本的な部分です。
TLS と SSL ハンドシェイク
SSL (セキュア・ソケット・レイヤー) は、HTTP 用に開発されたオリジナルの暗号化プロトコルでした。TLS(トランスポート層セキュリティ)はしばらく前にSSLに取って代わりました。SSL ハンドシェイクは TLS ハンドシェイクと呼ばれるようになりましたが、「SSL」名は今でも広く使われています。
TLS ハンドシェイクはいつ発生しますか。
TLS ハンドシェイクは、ユーザーが HTTPS 経由で Web サイトに移動し、ブラウザーが最初に Web サイトのオリジンサーバーへのクエリを開始したときに実行されます。TLS ハンドシェイクは、API 呼び出しや DNS over HTTPS クエリなど、他の通信が HTTPS を使用する場合にも発生します。
TLS ハンドシェイクは、TCP ハンドシェイクを介して TCP 接続が開かれた後に発生します。
TLS ハンドシェイク中には何が起こりますか?
- TLS ハンドシェイク中、クライアントとサーバは共に次の処理を行います。
- 使用する TLS のバージョン (TLS 1.0、1.2、1.3 など) を指定します。
- 使用する暗号スイート (次のセクションを参照) を決定します。
- サーバーの公開鍵と SSL 認証局のデジタル署名を使用して、サーバーの ID を認証します。
- ハンドシェイクが完了したら、対称暗号化を使用するセッションキーを生成します。
TLS ハンドシェイクの手順を教えてください。
- TLS ハンドシェイクは、クライアントとサーバーによって交換される一連のデータグラム、つまりメッセージです。TLS ハンドシェイクには複数の手順が伴います。これは、クライアントとサーバーがハンドシェイクを完了し、さらに会話を可能にするために必要な情報を交換するためです。
TLS ハンドシェイク内の正確な手順は、使用する鍵交換アルゴリズムの種類と、両者がサポートする暗号スイートによって異なります。RSA 鍵交換アルゴリズムが最もよく使用されます。それは次のようになります。
- 「client hello」メッセージ:クライアントは「hello」メッセージをサーバーに送信してハンドシェイクを開始します。このメッセージには、クライアントがサポートしている TLS バージョン、サポートされている暗号スイート、「クライアントランダム」と呼ばれるランダムなバイト文字列が含まれます。
- 「server hello」メッセージ:クライアントの hello メッセージに応答して、サーバーは、サーバーの SSL 証明書、サーバーが選択した暗号スイート、および「server random」(サーバーによって生成されたもう 1 つのランダムなバイト文字列) を含むメッセージを送信します。
- 認証:クライアントは、サーバーの SSL 証明書を、その証明書を発行した認証局と照合します。これにより、サーバーが本人であり、クライアントがドメインの実際の所有者とやり取りしていることが確認されます。
- premaster secret: クライアントは、ランダムなバイト文字列「premaster secret」をもう 1 つ送信します。premaster シークレットは公開鍵で暗号化され、サーバーは秘密鍵でのみ復号できます。クライアントはサーバーの SSL 証明書から公開鍵を取得します。)
- 使用した秘密鍵:サーバーはプレマスターシークレットを復号化します。
- 作成されたセッションキー:クライアントとサーバーの両方が、クライアントランダム、サーバーランダム、およびプレマスターシークレットからセッションキーを生成します。彼らは同じ結果になるはずです。
- Client is ready: クライアントは、セッションキーで暗号化された「完了」メッセージを送信します。
- サーバー準備完了:サーバーは、セッションキーで暗号化された「完了」メッセージを送信します。
- 安全な対称暗号化を実現:ハンドシェイクが完了し、セッションキーを使用して通信が継続されます。
すべての TLS ハンドシェイクは非対称暗号化 (公開鍵と秘密鍵) を使用しますが、セッション鍵を生成する過程で秘密鍵を使用するわけではありません。たとえば、エフェメラルな Diffie-Hellman ハンドシェイクは次のように処理されます。
- Client hello: クライアントは、プロトコルバージョン、クライアントランダム、および暗号スイートのリストを含むクライアント hello メッセージを送信します。
- Server hello: サーバーは、SSL 証明書、選択した暗号スイート、およびサーバーランダムで応答します。前のセクションで説明した RSA ハンドシェイクとは対照的に、このメッセージにはサーバに次の内容も含まれています(ステップ 3)。
- サーバーのデジタル署名:サーバーは秘密鍵を使用して、クライアントランダム、サーバーランダム、および DH パラメーター* を暗号化します。この暗号化されたデータはサーバーのデジタル署名として機能し、SSL 証明書の公開キーと一致する秘密キーがサーバーにあることを証明します。
- デジタル署名の確認:クライアントは、公開鍵を使用してサーバーのデジタル署名を復号化し、サーバーが秘密鍵を制御していること、および本人であることを確認します。Client DH パラメータ:クライアントは DH パラメータをサーバに送信します。
- クライアントとサーバがプレマスターシークレットを計算する:RSA ハンドシェイクのように、クライアントがプレマスターシークレットを生成してサーバに送信する代わりに、クライアントとサーバは交換した DH パラメータを使用して、一致するプレマスターシークレットを個別に計算します。
- 作成されたセッションキー:クライアントとサーバーは、RSA ハンドシェイクと同様に、プレマスターシークレット、クライアントランダム、およびサーバーランダムからセッションキーを計算するようになりました。
- クライアントの準備完了:RSA ハンドシェイクと同じ
- サーバは準備完了です
- セキュアな対称暗号化を実現
*DH パラメーター:DH は Diffie-Hellman の略です。Diffie-Hellman アルゴリズムは、指数計算を使用して同じ premaster シークレットに到達します。サーバーとクライアントはそれぞれ計算用のパラメーターを提供し、これらを組み合わせると、両側で異なる計算が行われ、結果は等しくなります。
エフェメラルな Diffie-Hellman ハンドシェイクと他の種類のハンドシェイクの対比、およびこれらがどのように前方秘匿性を実現するかについての詳細は、この TLS プロトコルのドキュメントを参照してください。
暗号スイートって何ですか?
- 暗号スイートは、セキュアな通信接続を確立するために使用する暗号化アルゴリズムのセットです。暗号化アルゴリズムとは、データをランダムに見せるためにデータに対して実行される一連の数学的演算です。さまざまな暗号スイートが広く使用されており、TLS ハンドシェイクの重要な部分は、そのハンドシェイクにどの暗号スイートを使用するかを合意することです。
開始するには、「リファレンス: TLS プロトコルのドキュメント」を参照してください。
NetScaler Application Delivery Management SSL ダッシュボード
NetScaler Application Delivery Management(ADM)により、証明書管理のあらゆる側面が合理化されるようになりました。1つのコンソールから、使われていない、または期限切れが近い証明書のタブは閉じたまま、正しい発行者、キーの強度、および正しいアルゴリズムを確保する自動化されたポリシーを作成することができます。NetScaler Console SSLダッシュボードとその機能を使い始めるには、SSL証明書とは何か、NetScaler Consoleを使用してSSL証明書を追跡する方法を理解する必要があります。
SSL トランザクションの一部であるセキュアソケットレイヤー (SSL) 証明書は、企業 (ドメイン) または個人を識別するデジタルデータフォーム (X509) です。この証明書には、サーバーとの安全なトランザクションを開始しようとするすべてのクライアントが確認できる公開キーコンポーネントが含まれます。対応する秘密キーは、Citrix Application Delivery Controller(ADC)アプライアンスに安全に配置され、非対称キー(または公開キー)の暗号化と復号化を完了するために使用されます。
SSL証明書およびキーは、次のいずれかの方法で入手できます。
- 認可された認証局 (CA) から
- NetScalerアプライアンス上で新しいSSL証明書とキーを生成する
NetScaler コンソールでは、管理対象のすべてのNetScalerインスタンスにインストールされているSSL証明書を一元的に表示できます。SSL Dashboard では、証明書の発行者、キーの強度、署名アルゴリズム、期限切れまたは未使用の証明書などを追跡するのに役立つグラフを表示できます。また、仮想サーバーで実行されているSSLプロトコルの分布および各サーバーで有効化されているキーも確認できます。
さらに、証明書の有効期限が近づいたときに、証明書が間もなく期限切れになるという情報と、その証明書を使用しているNetScalerインスタンスに関する情報が届くように通知を設定できます。
NetScalerインスタンスの証明書をCA証明書にリンクできます。ただし、同じ CA 証明書にリンクする証明書のソースと発行元が同じであることを確認してください。証明書を CA 証明書にリンクしたら、それらのリンクを解除できます。
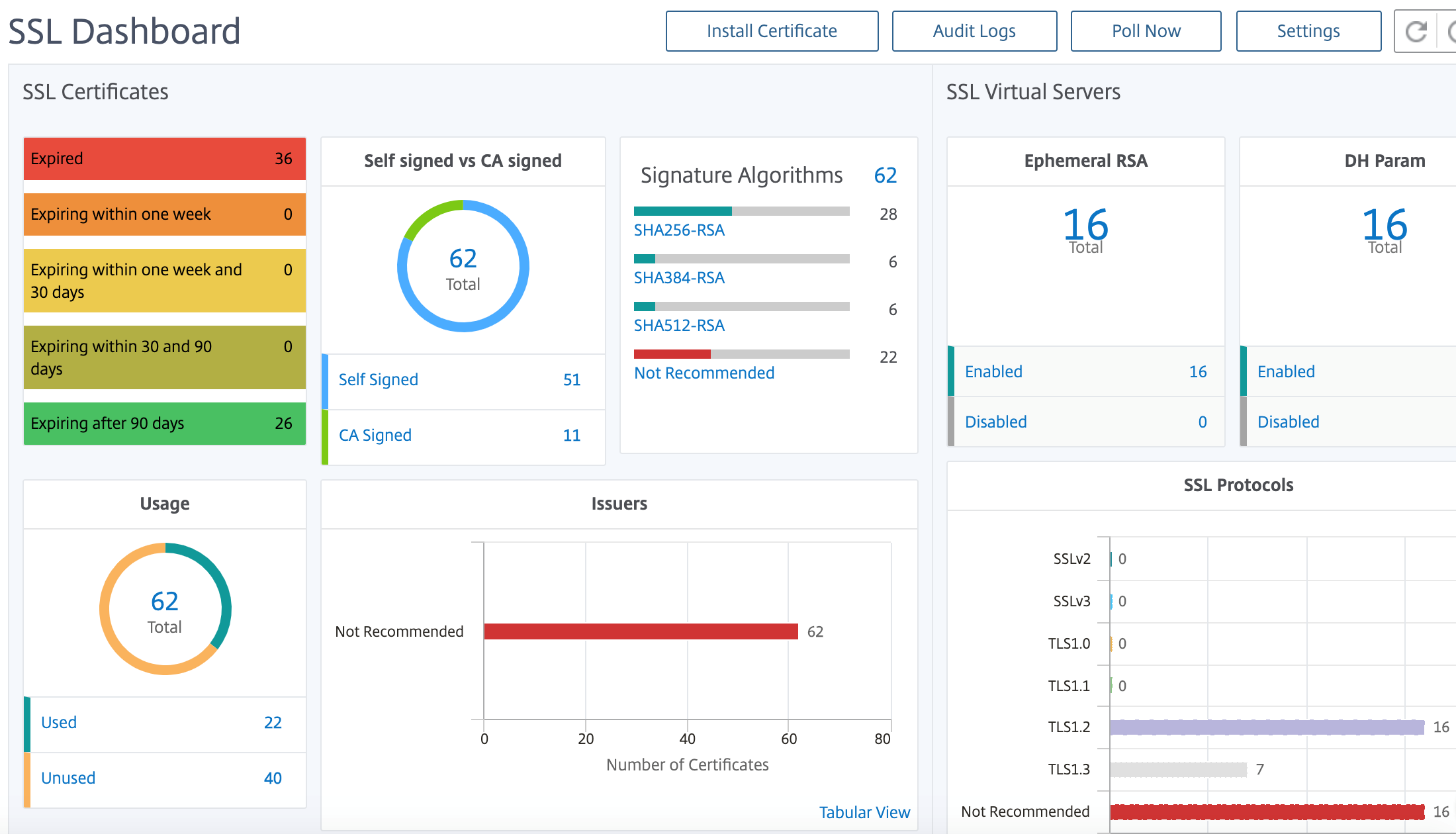
開始するには、 SSL ダッシュボードのドキュメントを参照してください。
サード・パーティとの連携
アプリケーションのレイテンシーはミリ秒単位で測定され、使用するメトリクスに応じて 2 つのうちの 1 つを示すことができます。レイテンシを測定する一般的な方法は「ラウンドトリップ時間」(RTT) と呼ばれます。RTT は、データパケットがネットワーク上のある地点から別の地点に移動して、応答が送信元に返されるまでにかかる時間を計算します。もう 1 つは「最初のバイトまでの時間」(Time to first byte) (または TTFB) と呼ばれ、パケットがネットワーク上のある地点を出発してから宛先に到着するまでにかかる時間を記録します。RTT は、ネットワーク上の 1 つのポイントから実行でき、(TTFB のように) データ収集ソフトウェアを宛先ポイントにインストールする必要がないため、レイテンシの測定によく使用されます。
ADM サービスでは、アプリケーションの帯域幅の使用量とパフォーマンスをリアルタイムで監視することで、問題を簡単に特定し、潜在的な問題が顕在化してネットワーク上のユーザーに影響を及ぼす前に先制的に対処できます。このフローベースのソリューションは、インターフェイス、アプリケーション、カンバセーションごとに使用状況を追跡し、ネットワーク全体のアクティビティに関する詳細情報を提供します。
Splunk ツールを使う
インフラストラクチャとアプリケーションのパフォーマンスは相互に依存しています。全体像を把握するために、SignalFX はクラウドインフラストラクチャとその上で実行されるマイクロサービスとのシームレスな相関関係を提供します。メモリリーク、ノイズの多いネイバーコンテナー、その他のインフラストラクチャ関連の問題が原因でアプリケーションが動作した場合、SignalFX から通知されます。全体像を把握するために、コンテキスト内で Splunk のログとイベントにアクセスすることで、より詳細なトラブルシューティングと根本原因の分析が可能になります。
SignalFX マイクロサービス APM と Splunk によるトラブルシューティングの詳細については、 DevOps 向け Splunk の情報をご覧ください 。
MongoDB サポート
MongoDB は、柔軟な JSON に似たドキュメントにデータを格納します。つまり、フィールドはドキュメントごとに異なり、データ構造は時間の経過とともに変化する可能性があります。
ドキュメントモデルはアプリケーションコード内のオブジェクトにマップされるため、データの操作が容易になります。
オンデマンドクエリ、インデックス作成、リアルタイム集約により、データにアクセスして分析するための強力な方法が提供されます。
MongoDB は中核をなす分散データベースであるため、高可用性、水平スケーリング、地理的分散が組み込まれており、使いやすくなっています。
MongoDB は、以下を実現するテクノロジー基盤により、最新のアプリケーションの要求を満たすように設計されています。
- ドキュメントデータモデル — データを操作する最適な方法を提供します。
- 分散システム設計 — データを必要な場所にインテリジェントに配置できます。
- どこにいても自由に実行できる統合エクスペリエンスにより、将来を見据えた作業が可能になり、ベンダーロックインを排除できます。
これらの機能により、MongoDB に支えられたインテリジェントな運用データプラットフォームを構築できます。詳細については、 MongoDB のドキュメントを参照してください。
Ingress トラフィックを TCP または UDP ベースのアプリケーションに負荷分散する方法
Kubernetes 環境では、Ingress は Kubernetes クラスターの外部から Kubernetes サービスへのアクセスを許可するオブジェクトです。標準の Kubernetes Ingress リソースは、すべてのトラフィックが HTTP ベースであり、TCP、TCP-SSL、UDP などの HTTP ベース以外のプロトコルには対応していないと想定しています。したがって、DNS、FTP、LDAP などの L7 プロトコルに基づく重要なアプリケーションは、標準の Kubernetes Ingress を使用して公開することはできません。
Kubernetes の標準ソリューションは、LoadBalancer タイプのサービスを作成することです。詳細については、「 NetScalerのサービスタイプロードバランサー」 を参照してください。
2 番目のオプションは、Ingress オブジェクトに注釈を付けることです。NetScaler Ingress Controllerを使用すると、TCPまたはUDPベースの入力トラフィックの負荷分散が可能になります。Kubernetes Ingress リソース定義で以下のアノテーションを使用して 、TCP または UDP ベースの Ingress トラフィックの負荷を分散できます。
- ingress.citrix.com/insecure-service-type: このアノテーションにより、NetScalerのプロトコルとしてTCP、UDP、またはANYによるL4負荷分散が可能になります。
- ingress.citrix.com/insecure-port: アノテーションはTCPポートを構成します。このアノテーションは、非標準ポートでマイクロサービスアクセスが必要な場合に役立ちます。デフォルトでは、ポート 80 が設定されています。
詳細については、「 Ingress トラフィックを TCP または UDP ベースのアプリケーションに負荷分散する方法」を参照してください。
TCP または UDP ベースのアプリケーションのパフォーマンスを監視し、改善する
アプリケーション開発者は、NetScaler のリッチモニター(TCP-ECV、UDP-ECV など)を使用して、TCPまたはUDPベースのアプリケーションの状態を綿密に監視できます。ECV (拡張コンテンツ検証) モニターは、アプリケーションが予期したコンテンツを返しているかどうかを確認するのに役立ちます。
また、ソース IP などの永続化方法を使用することで、アプリケーションのパフォーマンスを向上させることができます。これらのNetScaler機能は、 Kubernetesのスマートアノテーションを通じて使用できます 。その一例を以下に挙げます。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mongodb
annotations:
ingress.citrix.com/insecure-port: “80”
ingress.citrix.com/frontend-ip: “192.168.1.1”
ingress.citrix.com/csvserver: ‘{“l2conn”:”on”}’
ingress.citrix.com/lbvserver: ‘{“mongodb-svc”:{“lbmethod”:”SRCIPDESTIPHASH”}}’
ingress.citrix.com/monitor: ‘{“mongodbsvc”:{“type”:”tcp-ecv”}}’
Spec:
rules:
- host: mongodb.beverages.com
http:
paths:
- path: /
backend:
serviceName: mongodb-svc
servicePort: 80
<!--NeedCopy-->
NetScaler Application Delivery Management (ADM) サービス
NetScalerコンソールサービスには次の利点があります:
- 機敏性 — 運用、更新、使用が容易。NetScaler Console Serviceのサービスモデルはクラウド上で利用できるため、提供されている機能の運用、更新、使用が簡単です。更新の頻度と自動更新機能の組み合わせにより、NetScaler 展開が迅速に強化されます。
- タイム・ツ・バリューの短縮 — ビジネス目標の達成を迅速化。従来のオンプレミス展開とは異なり、NetScalerコンソールサービスは数回クリックするだけで使用できます。インストールと設定の時間を節約できるだけでなく、潜在的なエラーに時間とリソースを浪費することもありません。
- マルチサイト管理 — 複数のサイトデータセンターにまたがるインスタンスを 1 つのガラスで管理できます。NetScalerコンソールサービスを使用すると、さまざまなタイプの展開環境にあるNetScalerを管理および監視できます。オンプレミスとクラウドに導入されたNetScalersをワンストップで管理できます。
- 運用効率 — 運用生産性を向上させる最適化および自動化された方法。NetScaler Console Serviceを使用すると、従来のハードウェア展開の保守とアップグレードにかかる時間、費用、リソースを節約できるため、運用コストが削減されます。
Kubernetes アプリケーションのサービスグラフ
NetScaler Consoleのクラウドネイティブアプリケーション機能のサービスグラフを使用すると、次のことが可能になります:
- エンド・ツー・エンドのアプリケーション全体のパフォーマンスを確保
- アプリケーションのさまざまなコンポーネントの相互依存性によって生じるボトルネックを特定
- アプリケーションのさまざまなコンポーネントの依存関係に関する洞察を集める
- Kubernetes クラスター内のサービスを監視する
- 問題のあるサービスを監視する
- パフォーマンスの問題に寄与する要因を確認する
- サービス HTTP トランザクションの詳細な可視性を表示
- HTTP、TCP、SSL メトリックの分析
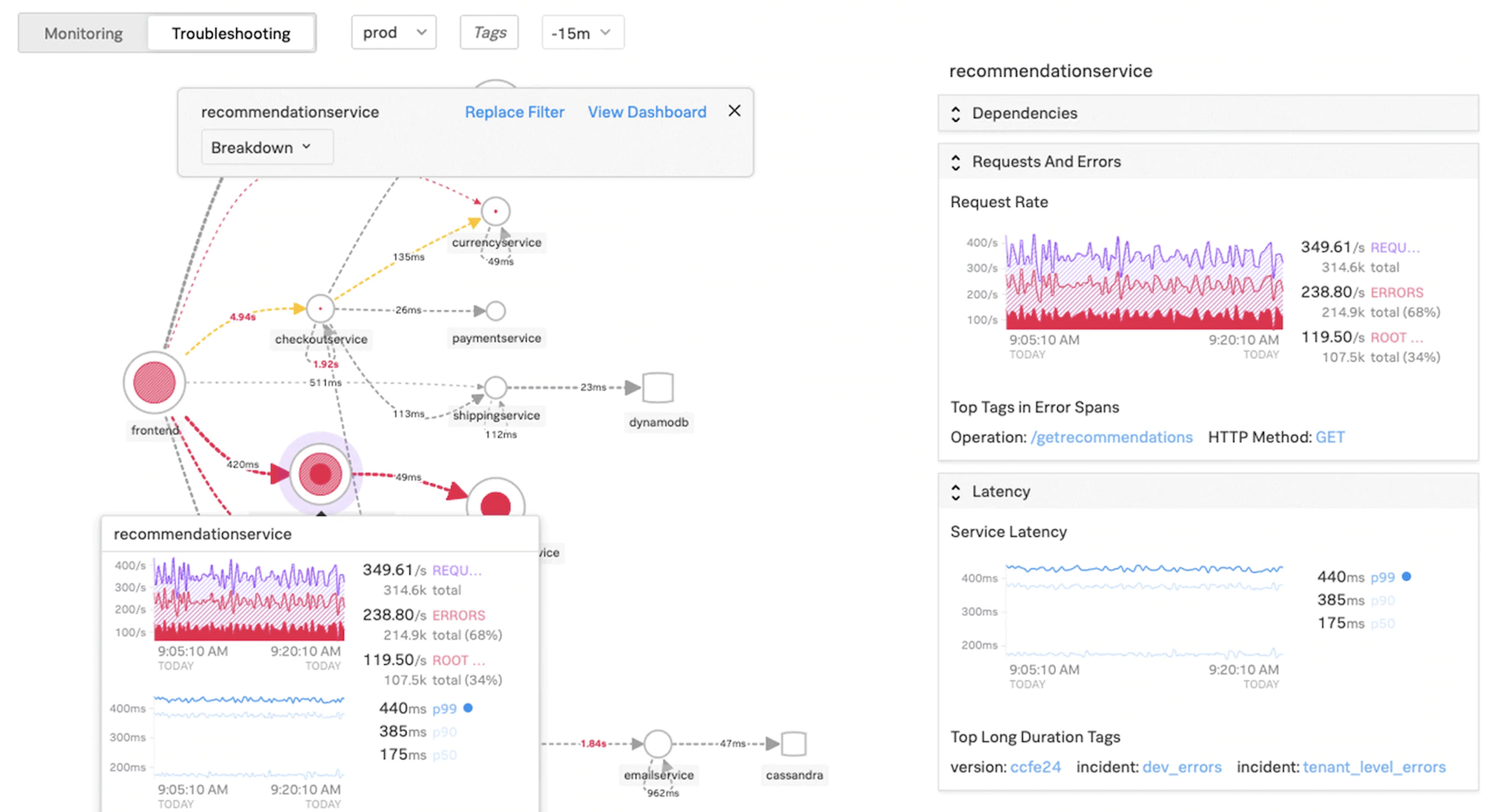
NetScaler Consoleでこれらの指標を視覚化することで、問題の根本原因を分析し、必要なトラブルシューティングアクションをより迅速に実行できます。サービスグラフには、さまざまなコンポーネントサービス内のアプリケーションが表示されます。Kubernetes クラスター内で実行されるこれらのサービスは、アプリケーション内外のさまざまなコンポーネントと通信できます。
はじめに、「 サービスグラフの設定」をご参照ください。
3層Webアプリケーションのサービスグラフ
アプリケーションダッシュボードのサービスグラフ機能を使用すると、次の項目を表示できます。
- アプリケーションの構成方法の詳細(コンテンツスイッチング仮想サーバーと負荷分散仮想サーバーを使用)
- GSLB アプリケーションの場合、データセンター、ADC インスタンス、CS、および LB 仮想サーバーを表示できます。
- クライアントからサービスへのエンド・ツー・エンドのトランザクション
- クライアントがアプリケーションにアクセスしている場所
- クライアント要求が処理されるデータセンターの名前と、関連するデータセンターNetScalerメトリック(GSLBアプリケーションのみ)
- クライアント、サービス、仮想サーバーのメトリックの詳細
- エラーがクライアントまたはサービスからのものである場合
- 「 緊急」、「 レビュー」、「 良好」などのサービスステータス。NetScaler Consoleは、サービスの応答時間とエラー数に基づいてサービスの状態を表示します。
- 重大 (赤) -平均サービス応答時間が 200 ミリ秒を超え、エラーカウントが 0 より大きいことを示します。
- Review (オレンジ) -平均サービス応答時間が 200 ミリ秒を超えるか、エラーカウントが 0 より大きいことを示します。
- 良好 (緑) -エラーがなく、平均サービス応答時間が 200 ミリ秒未満であることを示します
-
Critical、 Review、 Goodなどのクライアントのステータス。NetScaler Consoleは、クライアントのネットワーク遅延とエラー数に基づいてクライアントステータスを表示します。
- Critical (赤)-平均クライアントネットワーク遅延が 200 ミリ秒を超え、エラーカウントが 0 より大きいことを示します
- Review (オレンジ) -平均クライアントネットワーク遅延が 200 ミリ秒を超えるか、エラーカウントが 0 より大きいことを示します。
- 良好 (緑) -エラーがなく、平均クライアントネットワーク遅延が 200 ミリ秒未満であることを示します。
-
クリティカル、 レビュー、良好( Good)などの仮想サーバのステータス。NetScaler Consoleには、アプリスコアに基づいて仮想サーバーの状態が表示されます。
- クリティカル (赤) -アプリのスコアが40未満になったことを示します
- Review (オレンジ) -アプリのスコアが40~75の間であることを示します
- Good(緑) -アプリのスコアが 75 を超えることを示します。
注意事項:
- サービスグラフには、負荷分散、コンテンツスイッチング、GSLB 仮想サーバーのみが表示されます。
- 仮想サーバがカスタムアプリケーションにバインドされていない場合、その詳細はそのアプリケーションのサービスグラフに表示されません。
- 仮想サーバと Web アプリケーションの間でアクティブなトランザクションが発生した場合にのみ、クライアントとサービスのメトリックをサービスグラフに表示できます。
- 仮想サーバーと Web アプリケーション間でアクティブなトランザクションを利用できない場合は、負荷分散、コンテンツスイッチング、GSLB 仮想サーバー、サービスなどの構成データに基づくサービスグラフにのみ詳細を表示できます。
- アプリケーション設定の更新がサービスグラフに反映されるまで 10 分かかる場合があります。
詳細については、「 アプリケーション用サービスグラフ」を参照してください。
開始するには、 Service Graph のドキュメントを参照してください。
NetScalerチーム向けのトラブルシューティング
それでは、NetScalerプラットフォームのトラブルシューティングで最もよく使われる属性と、これらのトラブルシューティング手法がマイクロサービストポロジーのTier-1展開にどのように適用されるかについて説明します。
NetScalerには、コマンドをリアルタイムで表示するコマンドラインインターフェイス(CLI)があり、ランタイム構成、静的、およびポリシー構成を決定するのに役立ちます。これは 「SHOW」 コマンドで簡単に行えます。
SHOW-ADC CLI オペレーションを実行します。
>Show running config (-summary -fullValues)
Ability to search (grep command)
>“sh running config | -i grep vserver”
Check the version.
>Show license
“sh license"
<!--NeedCopy-->
SSL 統計情報の表示
>Sh ssl
System
Frontend
Backend
Encryption
<!--NeedCopy-->
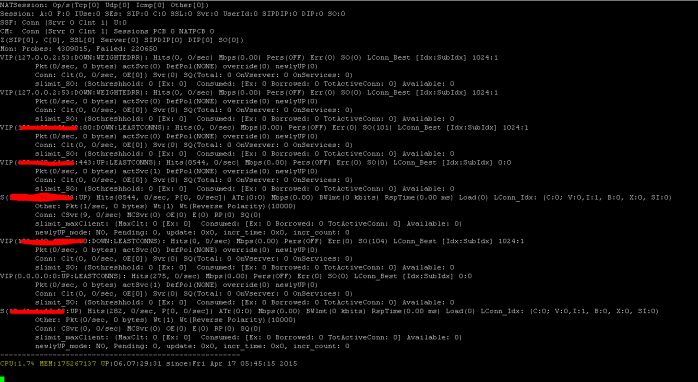
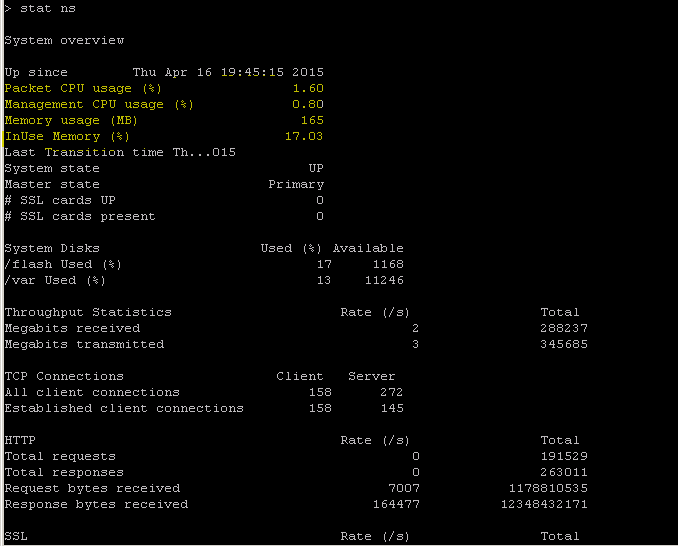
NetScalerには、7秒のカウンター間隔に基づいてすべてのオブジェクトの統計を列挙するコマンドがあります。これは 「STAT」 コマンドによって容易になります。
NetScalerによるきめ細かなL3-L7テレメトリー
- システムレベル:ADC の CPU およびメモリ使用率。
- HTTP プロトコル:#Requests /レスポンス、GET/POST スプリット、N-S および E-W の HTTP エラー (サービスメッシュライトのみ、サイドカーはまもなく)。
- SSL: #Sessions および #Handshakes は、サービスメッシュ Lite 専用の N-S および E-W トラフィック用です。
- IP プロトコル:#Packets 受信/送信、#Bytes 受信/送信、#Truncated パケット、#IP アドレスルックアップ
- NetScaler AAA: #Active セッション
- インターフェイス:#Total マルチキャストパケット、#Total 転送バイト、および送受信された #Jumbo パケット
- 負荷分散仮想サーバーとコンテンツスイッチング仮想サーバー:#Packets、#Hits、#Bytes が受信/送信されました。
STAT-ADC CLI オペレーションを実行します。
>Statistics
“stat ssl”
<!--NeedCopy-->
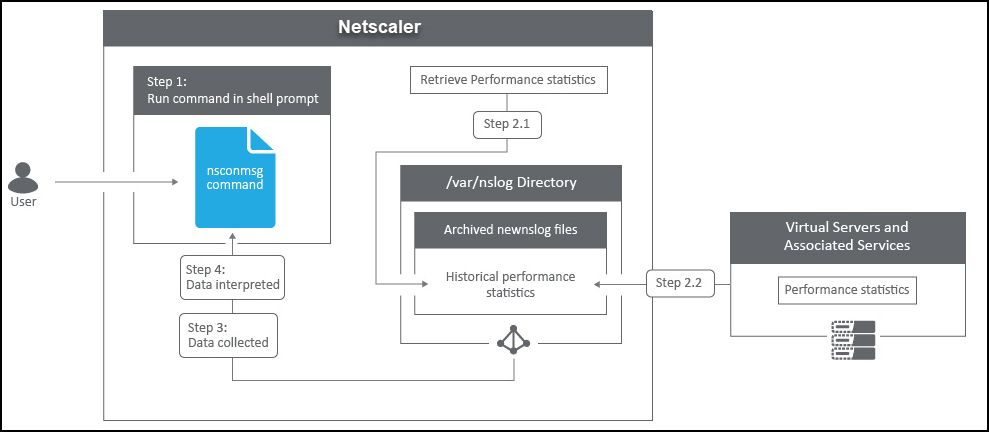
NetScalerにはログアーカイブ構造があり、 「NSCONMSG 」コマンドを使用して特定のエラーをトラブルシューティングする際に統計やカウンタを検索できます。
NSCONMSG -メインログファイル (ns データ形式)
Cd/var/nslog
“Mac Moves”
nsconmsg -d current -g nic_err
<!--NeedCopy-->
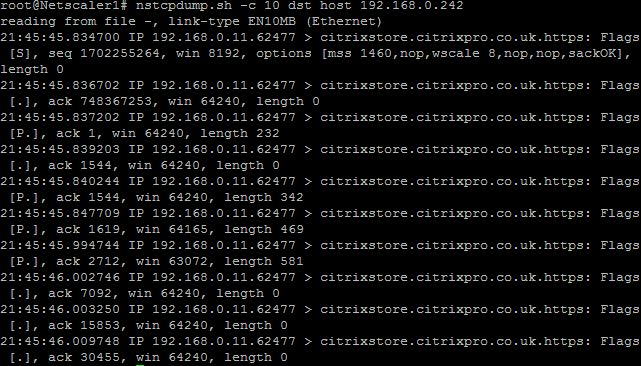
Nstcpdump
nstcpdumpは、 低レベルのトラブルシューティングに使用できます。nstcpdumpは、 nstraceより詳細な情報を収集しません。ADC CLI を開き、shellと入力します。フィルタはnstcpdumpと使用できますが、 ADCリソース固有のフィルタとともには使用できません。ダンプ出力は CLI 画面内で直接表示できます。
CTRL+C — これらのキーを同時に押すと、 nstcpdumpが停止します。
nstcpdump.sh dst host x.x.x.x — 宛先ホストに送信されたトラフィックを表示します。
nstcpdump.sh -n src host x.x.x.x — 指定されたホストからのトラフィックを表示し、IP アドレスを名前に変換しない (-n)。
nstcpdump.sh host x.x.x.x — 指定したホスト IP との間で送受信されるトラフィックを表示します。
NSTRACE -パケットトレースファイル
NSTRACE は、ネットワークをトラブルシューティングするための低レベルのパケットデバッグツールです。これにより、アナライザツールを使用してさらに分析できるキャプチャファイルを保存できます。一般的なツールは、ネットワークアナライザと Wireshark の 2 つです。
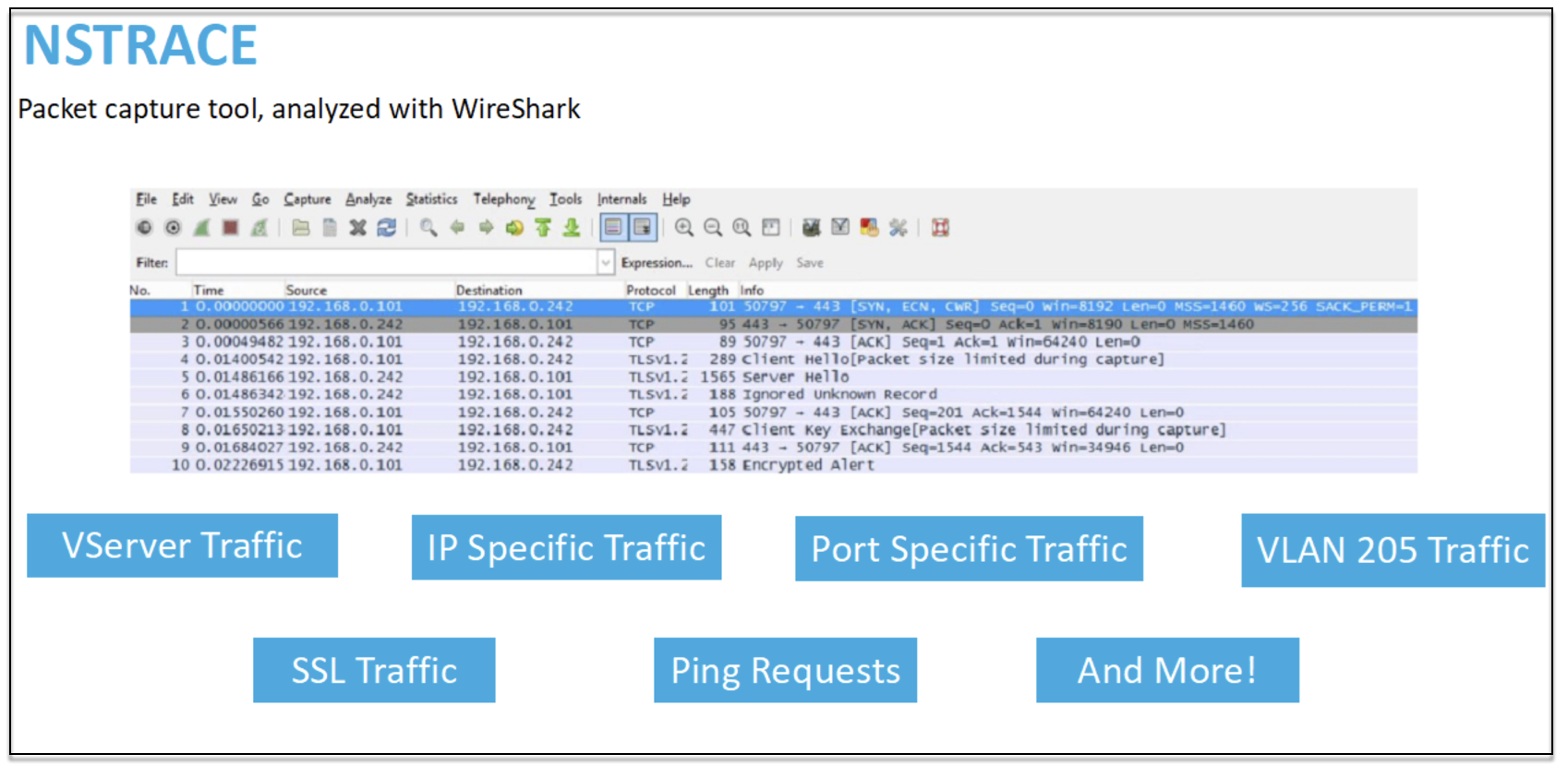
NSTRACE キャプチャファイルが ADC の /var/nstrace に作成されると、キャプチャファイルを Wireshark にインポートして、パケットキャプチャとネットワーク分析を行うことができます。
SYSCTL-詳細な ADC 情報:説明、モデル、プラットフォーム、CPU など
sysctl -a grep hw.physmem
hw.physmem: 862306304
netscaler.hw_physmem_mb: 822
<!--NeedCopy-->
aaad.debug-認証デバッグ情報のためにパイプをオープンする

aaad.debug モジュールを使用した ADC または ADC ゲートウェイ経由での認証問題のトラブルシューティング方法の詳細については、 aaad.debug のサポート記事を参照してください。
また、ADCのパフォーマンス統計やイベント・ログを直接取得することもできます。詳細については、 ADC サポートドキュメントを参照してください。
SRE チームとプラットフォームチームのトラブルシューティング
Kubernetes トラフィックフロー
North/South:
- North/South トラフィックは、イングレス経由でユーザからクラスタに流れるトラフィックです。
East/West:
- East/West トラフィックは、Kubernetes クラスタの周りを流れるトラフィック (サービス間またはサービス間データストア) です。
NetScaler CPXがKubernetes環境でeast-westトラフィックフローを負荷分散する方法
Kubernetes クラスターをデプロイしたら、ADM で Kubernetes 環境の詳細を指定して、クラスターを ADM と統合する必要があります。ADM は、サービス、エンドポイント、Ingress ルールなどの Kubernetes リソースの変更を監視します。
NetScaler CPXインスタンスをKubernetesクラスターにデプロイすると、自動的にADMに登録されます。登録プロセスの一環として、ADM は CPX インスタンスの IP アドレスと、NITRO REST API を使用してインスタンスに到達して構成できるポートについて学習します。
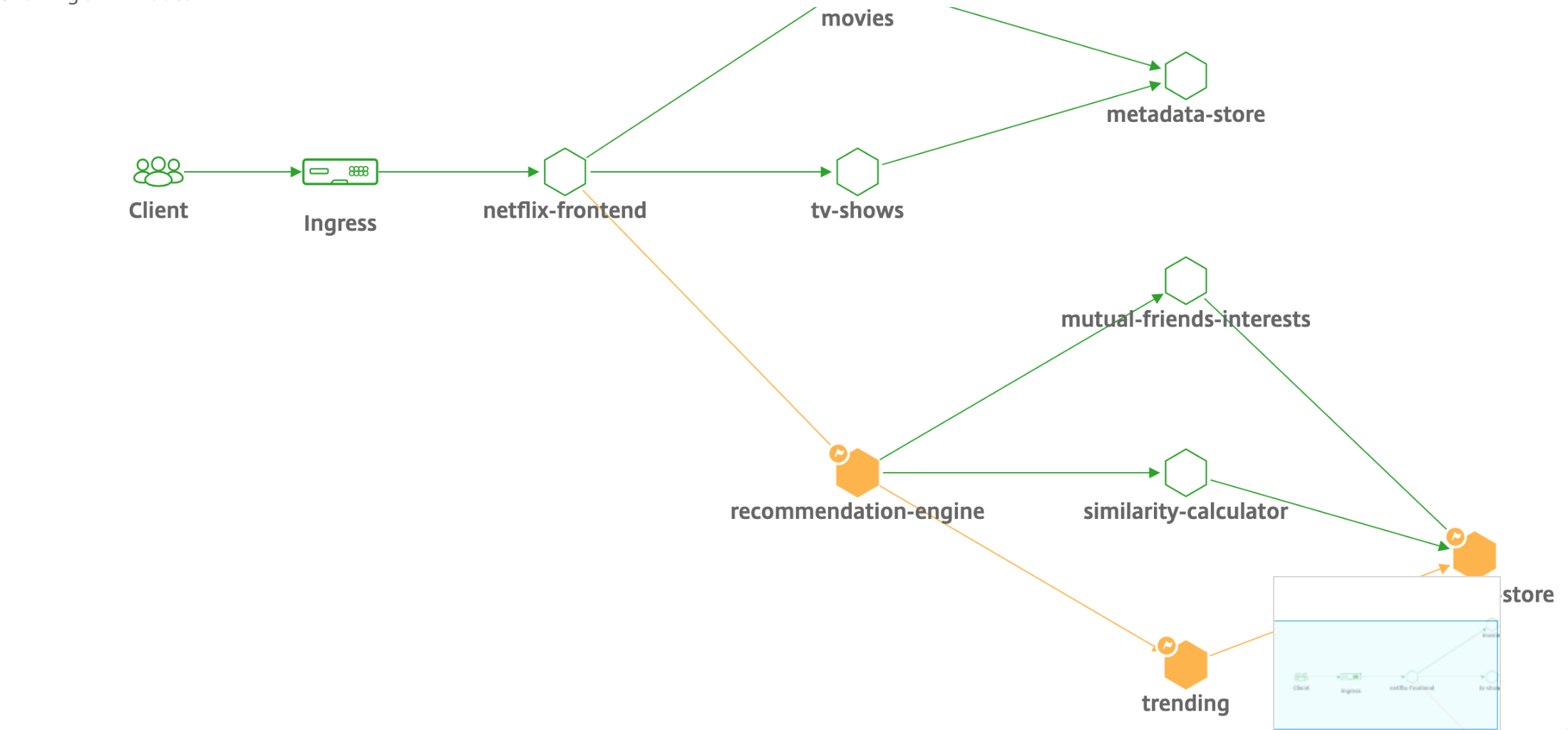
次の図は、Kubernetesクラスター内でNetScaler CPXがEast-Westトラフィックフローをどのように負荷分散するかを示しています。
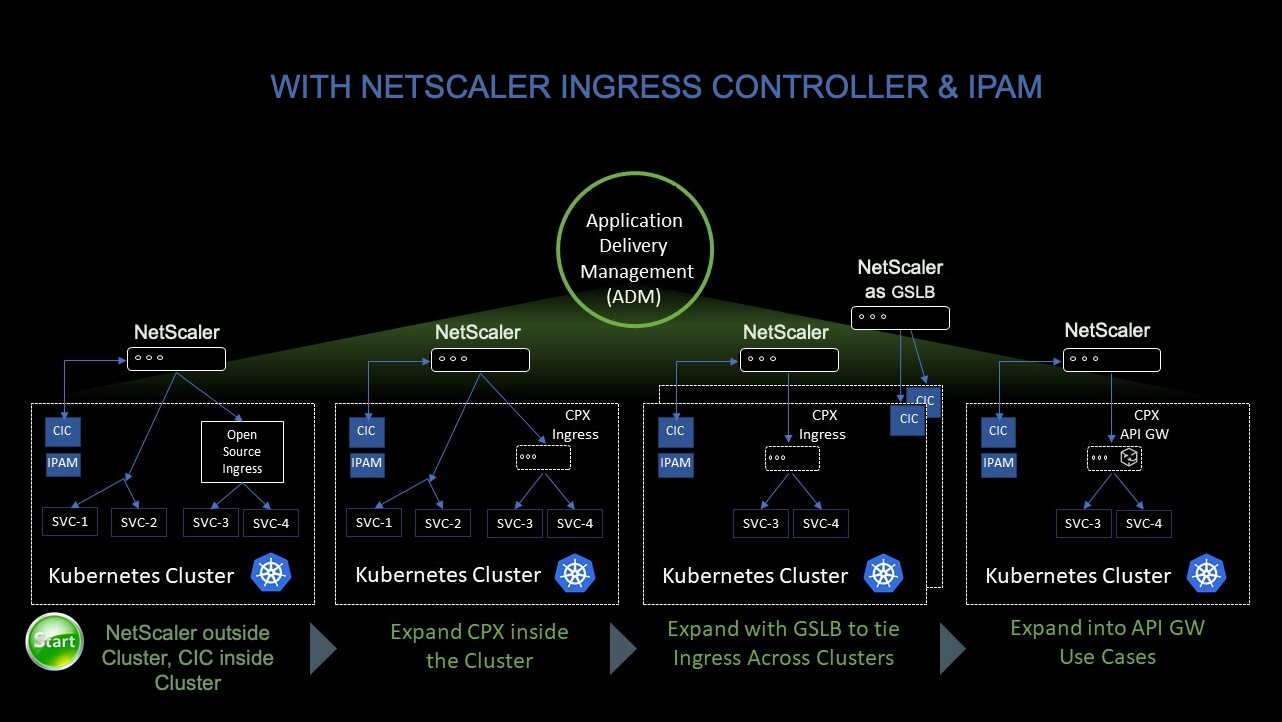
この例の説明を次に示します。
Kubernetes クラスターのノード 1 とノード 2 には、フロントエンドサービスとバックエンドサービスのインスタンスが含まれています。NetScaler CPXインスタンスをノード1とノード2に展開すると、NetScaler CPXインスタンスは自動的にADMに登録されます。ADM で Kubernetes クラスターの詳細を設定して、Kubernetes クラスターを ADM に手動で統合する必要があります。
クライアントがフロントエンドサービスを要求すると、Ingressリソースは、2つのノード上にあるフロントエンドサービスのインスタンスの間で要求を負荷分散します。フロントエンドサービスのインスタンスがクラスター内のバックエンドサービスからの情報を必要とする場合、そのノードのNetScaler CPXインスタンスに要求が送信されます。そのNetScaler CPXインスタンスは、クラスター内のバックエンドサービス間でリクエストの負荷分散を行い、East-Westのトラフィックフローを実現します。
アプリケーション用の ADM サービスグラフ
NetScaler Consoleのサービスグラフ機能を使用すると、すべてのサービスをグラフィカルに監視できます。この機能は、詳細な分析と有用なメトリックも提供します。次のサービスグラフを表示できます。
開始するには、 サービスグラフの詳細を参照してください。
マイクロサービスアプリケーションカウンターの表示
サービスグラフには、Kubernetes クラスターに属するすべてのマイクロサービスアプリケーションも表示されます。ただし、サービスにマウスポインタを置くと、メトリクスの詳細が表示されます。
以下を表示できます:
- サービス名
- SSL、HTTP、TCP、SSL over HTTP、SSL などのサービスで使用されるプロトコル
- Hits — サービスによって受信されたヒットの総数
- サービス応答時間 — サービスから取得した平均応答時間。 (応答時間 = クライアント RTT + 要求の最後のバイト — 要求の最初のバイト)
- エラー — 4xx、5xx などのエラーの総数
- Data Volume — サービスによって処理されるデータの総量
- 名前空間 — サービスの名前空間
- クラスター名 — サービスがホストされているクラスター名
- SSL サーバーエラー — サービスからの SSL エラーの合計
これらの特定のカウンターとトランザクションログは、サポートされているさまざまなエンドポイントを使用してNetScaler Observability Exporter(COE)から抽出できます。COE の詳細については、次のセクションを参照してください。
NetScaler統計用エクスポーター
これは、NetScaler 統計情報をスクレイピングし、HTTP経由でPrometheusにエクスポートするシンプルなサーバーです。その後、PrometheusをデータソースとしてGrafanaに追加して、NetScalerの統計をグラフィカルに表示できます。
NetScalerインスタンスの統計情報とカウンターを監視するには、 citrix-adc-metric-exporter コンテナまたはスクリプトとして実行できます。エクスポーターは、仮想サーバーへの総ヒット数、HTTP 要求レート、SSL 暗号化/復号化レートなど、NetScaler インスタンスからNetScaler 統計を収集し、Prometheus サーバーが統計情報を取得してタイムスタンプ付きで保存するまで保持します。その後、Grafana を Prometheus サーバーにポイントして、NetScaler 統計の分析に必要な統計情報の取得、プロット、アラームの設定、ヒートマップの作成、テーブルの生成などを行うことができます。
以下のセクションでは、図に示すような環境でエクスポータが動作するように設定する方法について詳しく説明します。エクスポーターがデフォルトでスクレイピングするNetScalerエンティティ/メトリックとその変更方法についても説明します。
NetScaler 用エクスポーターについて詳しくは、 メトリクスエクスポーター GitHubを参照してください。
ADM サービス分散トレーシング
サービスグラフでは、分散トレーシングビューを使用して次の操作を実行できます。
- サービス全体のパフォーマンスを分析します。
- 選択したサービスとその相互依存サービス間の通信フローを視覚化します。
- エラーを示すサービスを特定し、エラーのあるサービスをトラブルシューティングする
- 選択したサービスと相互依存する各サービス間のトランザクション詳細を表示します。
ADM 分散トレーシングの前提条件
サービスのトレース情報を表示するには、次の操作を行う必要があります。
- East-West トラフィックを送信する間、アプリケーションが次のトレースヘッダーを保持していることを確認します。

- CPX YAML ファイルを NS_DISTRIBUTED_TRACING で更新し、値を「はい」に設定します。 はじめに、「 分散トレーシング」を参照してください。
NetScalerオブザーバビリティエクスポーター(COE)の解析
NetScaler Observability Exporterは、NetScalerからメトリックとトランザクションを収集し、サポートされているエンドポイントに適した形式(JSON、AVROなど)に変換するコンテナです。NetScaler Observability Exporterによって収集されたデータを目的のエンドポイントにエクスポートできます。エンドポイントにエクスポートされたデータを分析することで、NetScalersがプロキシするアプリケーションのマイクロサービスレベルで貴重な洞察を得ることができます。
COE の詳細については、COE GitHubを参照してください。
ElasticsearchをトランザクションエンドポイントとするCOE

Elasticsearch がトランザクションエンドポイントとして指定されている場合、NetScaler オブザーバビリティエクスポーターはデータを JSON 形式に変換します。Elasticsearchサーバーでは、NetScaler オブザーバビリティエクスポーターが各ADCに対して1時間ごとにElasticsearchインデックスを作成します。これらのインデックスは、データ、時間、ADC の UUID、および HTTP データのタイプ (http_event または http_error) に基づいています。次に、NetScalerオブザーバビリティエクスポーターは、各ADCのElastic検索インデックスにJSON形式でデータをアップロードします。通常のトランザクションはすべて http_event インデックスに配置され、異常は http_error インデックスに配置されます。
Zipkin による分散トレースのサポート
マイクロサービスアーキテクチャでは、1 つのエンドユーザー要求が複数のマイクロサービスにまたがる場合があるため、トランザクションの追跡やエラーの原因の修正が困難になります。このような場合、従来のパフォーマンス監視方法では、障害が発生した場所やパフォーマンスの低下の原因を正確に特定することはできません。リクエストを処理する各マイクロサービスに固有のデータポイントをキャプチャし、分析して有意義なインサイトを得る方法が必要です。
分散トレーシングは、トランザクションをエンドツーエンドで追跡し、複数のマイクロサービスにわたってトランザクションがどのように処理されているかを理解する方法を提供することで、この課題に対処します。
OpenTracingは、ディストリビューティッド(分散)トレーシングを設計および実装するためのAPIの仕様および標準セットです 。分散トレーサを使用すると、マイクロサービス間のデータフローを視覚化し、マイクロサービスアーキテクチャのボトルネックを特定するのに役立ちます。
NetScaler オブザーバビリティエクスポーターは、NetScaler の分散トレースを実装しており、現在、 分散トレーサーとしてZipkinをサポートしています 。
現在、NetScaler を使用してアプリケーションレベルでパフォーマンスを監視できます。NetScaler オブザーバビリティエクスポーターをNetScalerとともに使用すると、NetScaler CPX、MPX、またはVPXによってプロキシされた各アプリケーションのマイクロサービスのトレースデータを取得できます。
はじめに、 GitHub オブザーバビリティエクスポーターを参照してください。
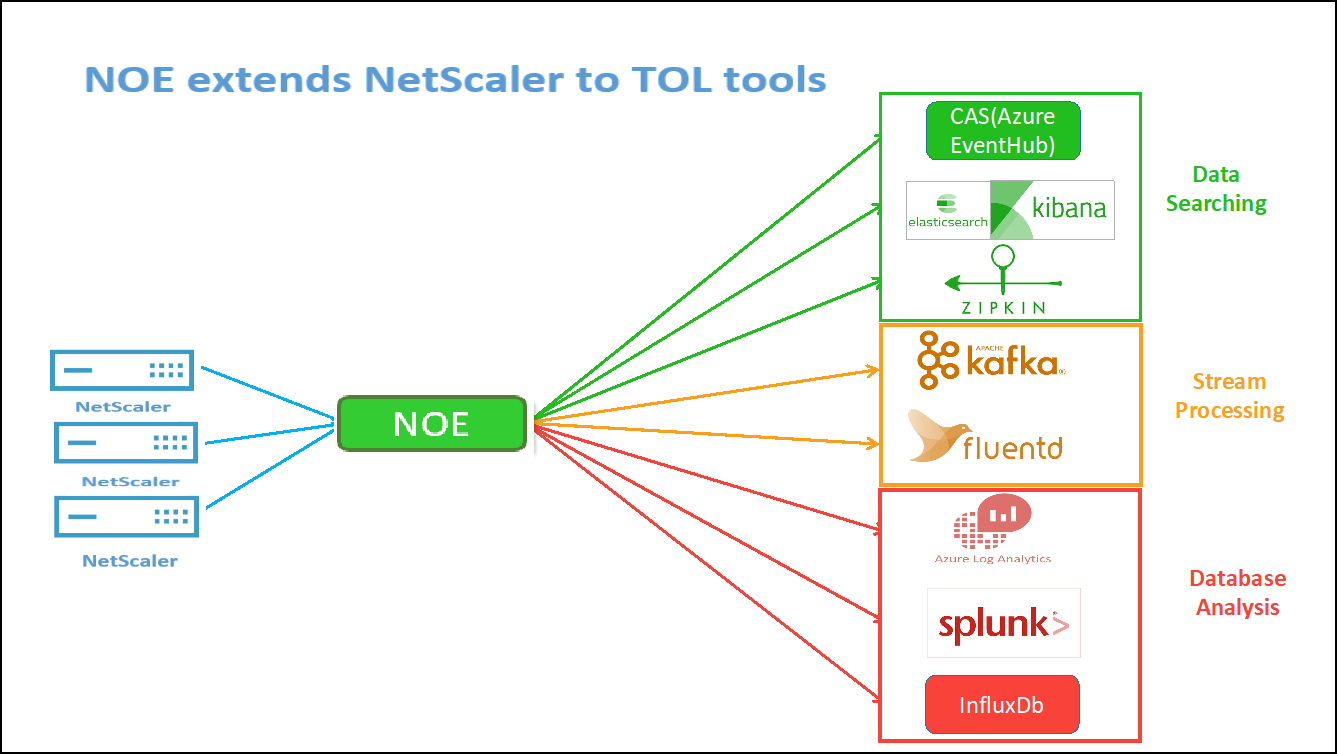
アプリケーションデバッグ用の Zipkin
Zipkin は、 [Google の Dapper の論文に基づいたオープンソースの分散トレースシステムです](https://storage.googleapis.com/pub-tools-public-publication-data/pdf/36356.pdf)。Dapperは、本番環境での分散トレースのためのGoogleのシステムです。Googleはこれを彼らの論文「Googleの開発者に複雑な分散システムの振る舞いに関するより多くの情報を提供するためにDapperを構築した」で説明している。トラブルシューティングを行う場合、特にシステムが複雑で分散している場合には、さまざまな角度からシステムを観察することが重要です。
次の Zipkin トレースデータは、Watches サンプルアプリケーションに関連する合計 5 つのスパンと 5 つのサービスを識別します。トレースデータには、5 つのマイクロサービスにまたがる特定のスパンデータが表示されます。
開始するには、 Zipkinを参照してください。
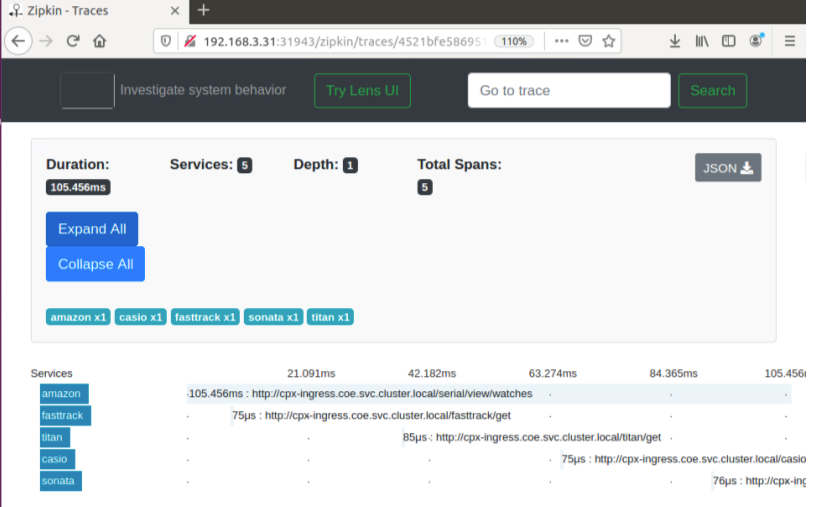
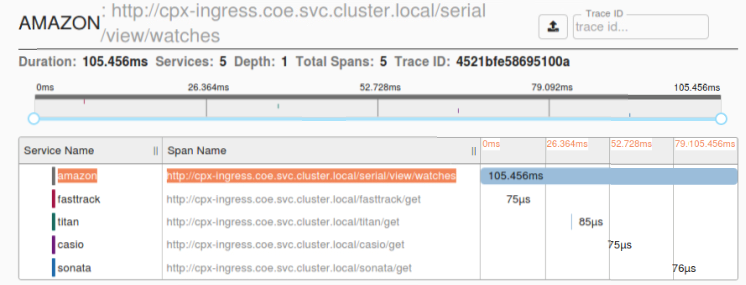
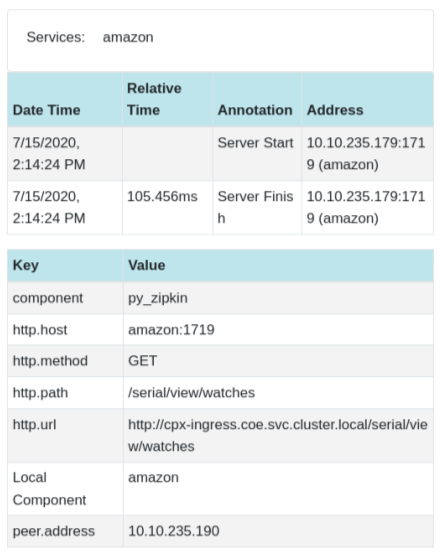
最初のページ読み込みリクエストのアプリケーションレイテンシーを示す Zipkin スパンの例:
データを見るためのKibana
Kibana は、Elasticsearch データを視覚化して Elastic Stack をナビゲートできるオープンなユーザーインターフェイスです。クエリのロードの追跡から、アプリ内でのリクエストの流れの把握まで、あらゆることを行えます。
アナリストでも管理者でも、Kibana は次の 3 つの重要な機能を提供することで、データをアクション可能にします。
- オープンソースの分析および可視化プラットフォーム。Kibana を使用して Elasticsearch データを探索し、美しいビジュアライゼーションとダッシュボードを構築できます。
- Elastic スタックを管理するための UI。セキュリティ設定の管理、ユーザーロールの割り当て、スナップショットの作成、データのロールアップなど、すべてKibana UIから実行できます。
- Elasticのソリューションの一元化されたハブ。ログ分析からドキュメント検出、SIEM に至るまで、Kibana はこれらの機能やその他の機能にアクセスするためのポータルです。
Kibana は、Elasticsearch をデータソースとして使用するように設計されています。Elasticsearch は、Kibana を一番上に置き、データを保存して処理するエンジンだと考えてください。
Kibana はホームページから、データを追加するための次のオプションを提供します。
- ファイルデータビジュアライザーを使用してデータをインポートします。
- 組み込みのチュートリアルを使用して、Elasticsearch へのデータフローをセットアップします。データに関するチュートリアルがない場合は、Beats の概要に移動して、Beats ファミリーの他のデータシッパーについて学習します。
- サンプルデータセットを追加して、自分でデータを読み込まなくても Kibana を試乗できます。
- REST APIまたはクライアントライブラリを使用して、Elasticsearch にデータのインデックスを作成します。
Kibana はインデックスパターンを使用して 、どの Elasticsearch インデックスを調べるかを指示します。ファイルをアップロードしたり、組み込みのチュートリアルを実行したり、サンプルデータを追加したりすると、無料でインデックスパターンが得られ、探索を開始するのに適しています。独自のデータをロードする場合は、 Stack Managementでインデックスパターンを作成できます。
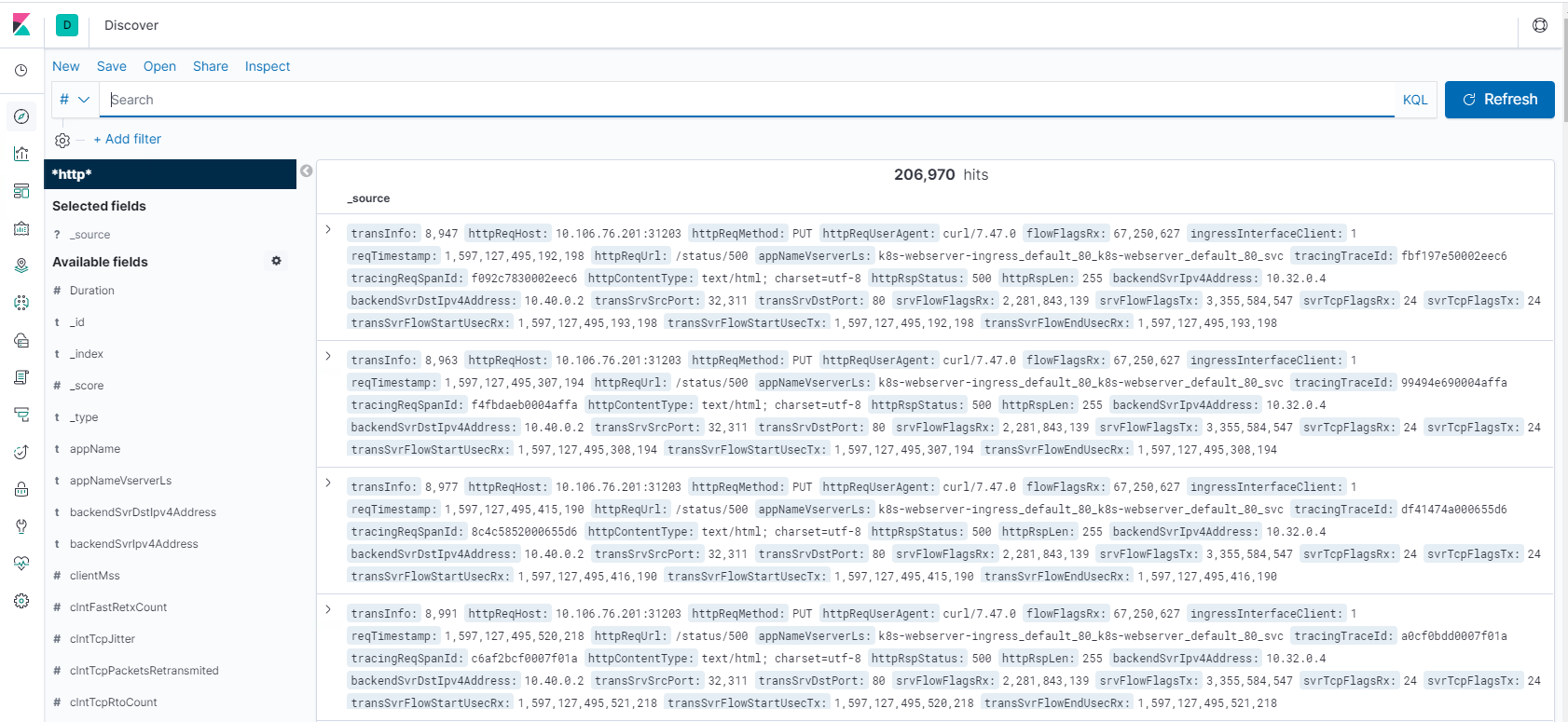
ステップ 1: Logstash のインデックスパターンを構成する
ステップ 2: インデックスを選択し、入力するトラフィックを生成します。
ステップ 3: ログフィードの非構造化データからアプリケーションを生成します。
ステップ 4: Kibana は Logstash 入力をフォーマットしてレポートとダッシュボードを作成します。
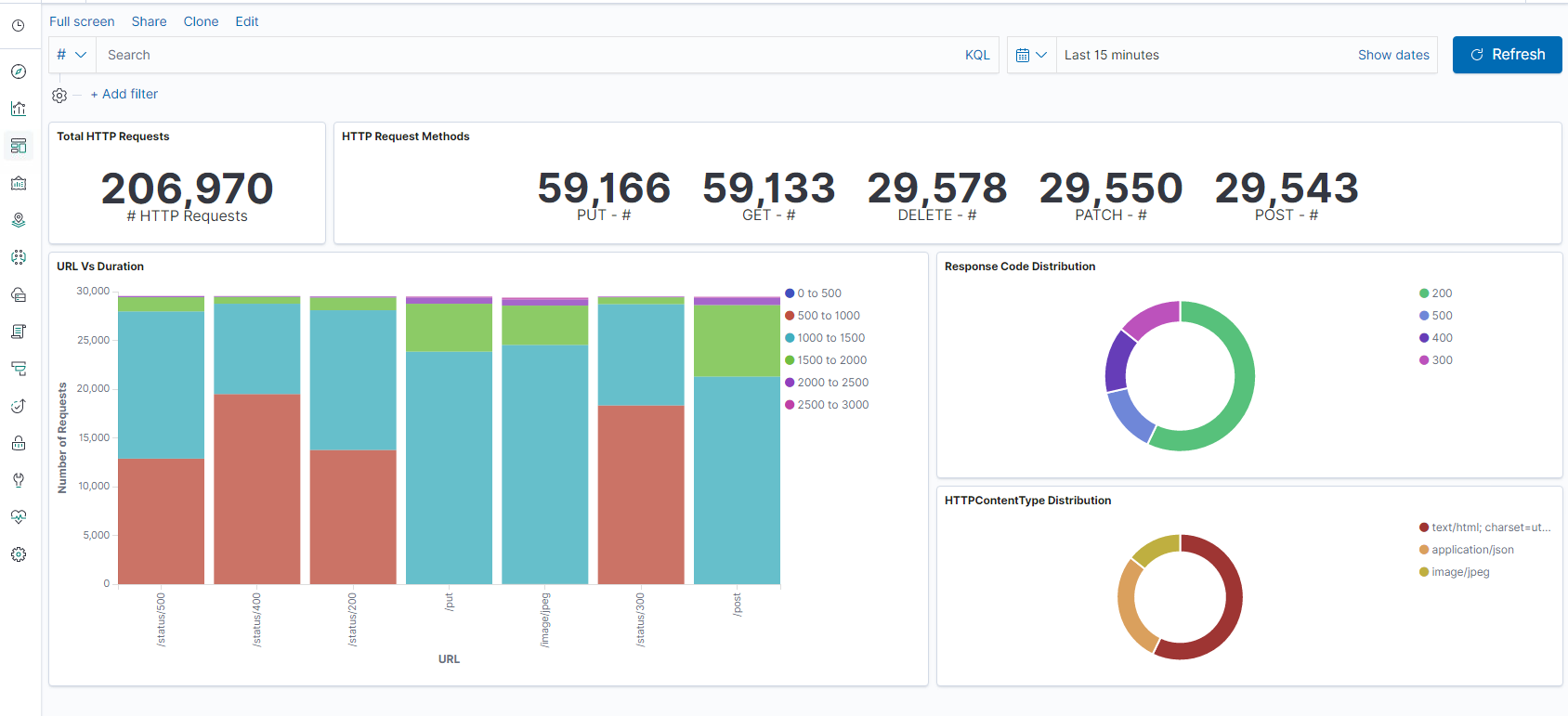
- 時間範囲
- 表形式表示
- ヒット数はアプリケーションに基づきます。
- 時刻 IP、エージェント、マシン.OS、レスポンスコード (200)、URL
- 値によるフィルタリング
ステップ 5: 集計レポートでデータを視覚化します。
- チャート・レポート (円、グラフなど) での結果集計
共有
共有
この記事の概要
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.