-
Native Cloud-Lösung von NetScaler
-
Verwenden Sie NetScaler ADM, um Probleme mit NetScaler cloudnativen Netzwerken zu beheben
-
Bereitstellen einer NetScaler VPX- Instanz
-
Optimieren der Leistung von NetScaler VPX auf VMware ESX, Linux KVM und Citrix Hypervisors
-
Unterstützung für die Erhöhung des NetScaler VPX-Speicherplatzes
-
NetScaler VPX-Konfigurationen beim ersten Start der NetScaler-Appliance in der Cloud anwenden
-
Verbessern der SSL-TPS-Leistung auf Public-Cloud-Plattformen
-
Gleichzeitiges Multithreading für NetScaler VPX in öffentlichen Clouds konfigurieren
-
Installieren einer NetScaler VPX Instanz auf einem Bare-Metal-Server
-
Installieren einer NetScaler VPX-Instanz auf Citrix Hypervisor
-
Installieren einer NetScaler VPX-Instanz auf VMware ESX
-
NetScaler VPX für die Verwendung der VMXNET3-Netzwerkschnittstelle konfigurieren
-
NetScaler VPX für die Verwendung der SR-IOV-Netzwerkschnittstelle konfigurieren
-
Migration des NetScaler VPX von E1000 zu SR-IOV- oder VMXNET3-Netzwerkschnittstellen
-
NetScaler VPX für die Verwendung der PCI-Passthrough-Netzwerkschnittstelle konfigurieren
-
-
Installieren einer NetScaler VPX-Instanz in der VMware Cloud auf AWS
-
Installieren einer NetScaler VPX-Instanz auf Microsoft Hyper-V-Servern
-
Installieren einer NetScaler VPX-Instanz auf der Linux-KVM-Plattform
-
Voraussetzungen für die Installation virtueller NetScaler VPX-Appliances auf der Linux-KVM-Plattform
-
Provisioning der virtuellen NetScaler-Appliance mit OpenStack
-
Provisioning der virtuellen NetScaler-Appliance mit Virtual Machine Manager
-
Konfigurieren virtueller NetScaler-Appliances für die Verwendung der SR-IOV-Netzwerkschnittstelle
-
Provisioning der virtuellen NetScaler-Appliance mit dem virsh-Programm
-
Provisioning der virtuellen NetScaler-Appliance mit SR-IOV auf OpenStack
-
-
Bereitstellen einer NetScaler VPX-Instanz auf AWS
-
Bereitstellen einer eigenständigen NetScaler VPX-Instanz auf AWS
-
Bereitstellen eines VPX-HA-Paar in derselben AWS-Verfügbarkeitszone
-
Bereitstellen eines VPX Hochverfügbarkeitspaars mit privaten IP-Adressen in verschiedenen AWS-Zonen
-
Schützen von AWS API Gateway mit NetScaler Web Application Firewall
-
Konfigurieren einer NetScaler VPX-Instanz für die Verwendung der SR-IOV-Netzwerkschnittstelle
-
Konfigurieren einer NetScaler VPX-Instanz für die Verwendung von Enhanced Networking mit AWS ENA
-
Bereitstellen einer NetScaler VPX Instanz unter Microsoft Azure
-
Netzwerkarchitektur für NetScaler VPX-Instanzen auf Microsoft Azure
-
Mehrere IP-Adressen für eine eigenständige NetScaler VPX-Instanz konfigurieren
-
Hochverfügbarkeitssetup mit mehreren IP-Adressen und NICs konfigurieren
-
Hochverfügbarkeitssetup mit mehreren IP-Adressen und NICs über PowerShell-Befehle konfigurieren
-
NetScaler-Hochverfügbarkeitspaar auf Azure mit ALB im Floating IP-Deaktiviert-Modus bereitstellen
-
Konfigurieren Sie eine NetScaler VPX-Instanz für die Verwendung von Azure Accelerated Networking
-
Konfigurieren Sie HA-INC-Knoten mithilfe der NetScaler-Hochverfügbarkeitsvorlage mit Azure ILB
-
NetScaler VPX-Instanz auf der Azure VMware-Lösung installieren
-
Eigenständige NetScaler VPX-Instanz auf der Azure VMware-Lösung konfigurieren
-
NetScaler VPX-Hochverfügbarkeitssetups auf Azure VMware-Lösung konfigurieren
-
Konfigurieren von GSLB in einem Active-Standby-Hochverfügbarkeitssetup
-
Konfigurieren von Adresspools (IIP) für eine NetScaler Gateway Appliance
-
Erstellen Sie ein Support-Ticket für die VPX-Instanz in Azure
-
NetScaler VPX-Instanz auf der Google Cloud Platform bereitstellen
-
Bereitstellen eines VPX-Hochverfügbarkeitspaars auf der Google Cloud Platform
-
VPX-Hochverfügbarkeitspaars mit privaten IP-Adressen auf der Google Cloud Platform bereitstellen
-
NetScaler VPX-Instanz auf Google Cloud VMware Engine bereitstellen
-
Unterstützung für VIP-Skalierung für NetScaler VPX-Instanz auf GCP
-
-
Bereitstellung und Konfigurationen von NetScaler automatisieren
-
Lösungen für Telekommunikationsdienstleister
-
Authentifizierung, Autorisierung und Überwachung des Anwendungsverkehrs
-
Wie Authentifizierung, Autorisierung und Auditing funktionieren
-
Grundkomponenten der Authentifizierung, Autorisierung und Audit-Konfiguration
-
Web Application Firewall-Schutz für virtuelle VPN-Server und virtuelle Authentifizierungsserver
-
Lokales NetScaler Gateway als Identitätsanbieter für Citrix Cloud
-
Authentifizierungs-, Autorisierungs- und Überwachungskonfiguration für häufig verwendete Protokolle
-
-
-
-
Erweiterte Richtlinienausdrücke konfigurieren: Erste Schritte
-
Erweiterte Richtlinienausdrücke: Arbeiten mit Datum, Uhrzeit und Zahlen
-
Erweiterte Richtlinienausdrücke: Analysieren von HTTP-, TCP- und UDP-Daten
-
Erweiterte Richtlinienausdrücke: Analysieren von SSL-Zertifikaten
-
Erweiterte Richtlinienausdrücke: IP- und MAC-Adressen, Durchsatz, VLAN-IDs
-
Erweiterte Richtlinienausdrücke: Stream-Analytics-Funktionen
-
Zusammenfassende Beispiele für fortgeschrittene politische Ausdrücke
-
Tutorial-Beispiele für erweiterte Richtlinien für das Umschreiben
-
-
-
Anwendungsfall — Binden der Web App Firewall-Richtlinie an einen virtuellen VPN-Server
-
-
-
-
Verwalten eines virtuellen Cache-Umleitungsservers
-
Statistiken für virtuelle Server zur Cache-Umleitung anzeigen
-
Aktivieren oder Deaktivieren eines virtuellen Cache-Umleitungsservers
-
Direkte Richtlinieneinschläge auf den Cache anstelle des Ursprungs
-
Verwalten von Clientverbindungen für einen virtuellen Server
-
Externe TCP-Integritätsprüfung für virtuelle UDP-Server aktivieren
-
-
Übersetzen die Ziel-IP-Adresse einer Anfrage in die Ursprungs-IP-Adresse
-
-
Verwalten des NetScaler Clusters
-
Knotengruppen für gepunktete und teilweise gestreifte Konfigurationen
-
Entfernen eines Knotens aus einem Cluster, der mit Cluster-Link-Aggregation bereitgestellt wird
-
Überwachen von Fehlern bei der Befehlsausbreitung in einer Clusterbereitstellung
-
VRRP-Interface-Bindung in einem aktiven Cluster mit einem einzigen Knoten
-
-
Konfigurieren von NetScaler als nicht-validierenden sicherheitsbewussten Stub-Resolver
-
Jumbo-Frames Unterstützung für DNS zur Handhabung von Reaktionen großer Größen
-
Zwischenspeichern von EDNS0-Client-Subnetzdaten bei einer NetScaler-Appliance im Proxymodus
-
Anwendungsfall — Konfiguration der automatischen DNSSEC-Schlüsselverwaltungsfunktion
-
Anwendungsfall — wie man einen kompromittierten aktiven Schlüssel widerruft
-
-
GSLB-Entitäten einzeln konfigurieren
-
Anwendungsfall: Bereitstellung einer Domänennamen-basierten Autoscale-Dienstgruppe
-
Anwendungsfall: Bereitstellung einer IP-Adressbasierten Autoscale-Dienstgruppe
-
-
-
IP-Adresse und Port eines virtuellen Servers in den Request-Header einfügen
-
Angegebene Quell-IP für die Back-End-Kommunikation verwenden
-
Quellport aus einem bestimmten Portbereich für die Back-End-Kommunikation verwenden
-
Quell-IP-Persistenz für Back-End-Kommunikation konfigurieren
-
Lokale IPv6-Linkadressen auf der Serverseite eines Load Balancing-Setups
-
Erweiterte Load Balancing-Einstellungen
-
Allmählich die Belastung eines neuen Dienstes mit virtuellem Server-Level erhöhen
-
Anwendungen vor Verkehrsspitzen auf geschützten Servern schützen
-
Bereinigung von virtuellen Server- und Dienstverbindungen ermöglichen
-
Persistenzsitzung auf TROFS-Diensten aktivieren oder deaktivieren
-
Externe TCP-Integritätsprüfung für virtuelle UDP-Server aktivieren
-
Standortdetails von der Benutzer-IP-Adresse mit der Geolocation-Datenbank abrufen
-
Quell-IP-Adresse des Clients beim Verbinden mit dem Server verwenden
-
Limit für die Anzahl der Anfragen pro Verbindung zum Server festlegen
-
Festlegen eines Schwellenwerts für die an einen Dienst gebundenen Monitore
-
Grenzwert für die Bandbreitenauslastung durch Clients festlegen
-
-
-
Lastausgleichs für häufig verwendete Protokolle konfigurieren
-
Anwendungsfall 5: DSR-Modus beim Verwenden von TOS konfigurieren
-
Anwendungsfall 6: Lastausgleich im DSR-Modus für IPv6-Netzwerke mit dem TOS-Feld konfigurieren
-
Anwendungsfall 7: Konfiguration des Lastenausgleichs im DSR-Modus mithilfe von IP Over IP
-
Anwendungsfall 8: Lastausgleich im Einarmmodus konfigurieren
-
Anwendungsfall 9: Lastausgleich im Inlinemodus konfigurieren
-
Anwendungsfall 10: Lastausgleich von Intrusion-Detection-System-Servern
-
Anwendungsfall 11: Netzwerkverkehr mit Listenrichtlinien isolieren
-
Anwendungsfall 12: Citrix Virtual Desktops für den Lastausgleich konfigurieren
-
Anwendungsfall 13: Konfiguration von Citrix Virtual Apps and Desktops für den Lastausgleich
-
Anwendungsfall 14: ShareFile-Assistent zum Lastausgleich Citrix ShareFile
-
Anwendungsfall 15: Konfiguration des Layer-4-Lastenausgleichs auf der NetScaler Appliance
-
-
SSL-Offload und Beschleunigung
-
Unterstützungsmatrix für Serverzertifikate auf der ADC-Appliance
-
Unterstützung für Intel Coleto SSL-Chip-basierte Plattformen
-
Unterstützung für Thales Luna Network Hardwaresicherheitsmodul
-
-
-
CloudBridge Connector-Tunnels zwischen zwei Rechenzentren konfigurieren
-
CloudBridge Connector zwischen Datacenter und AWS Cloud konfigurieren
-
CloudBridge Connector Tunnels zwischen einem Rechenzentrum und Azure Cloud konfigurieren
-
CloudBridge Connector Tunnels zwischen Datacenter und SoftLayer Enterprise Cloud konfigurieren
-
-
Konfigurationsdateien in einem Hochverfügbarkeitssetup synchronisieren
-
Hochverfügbarkeitsknoten in verschiedenen Subnetzen konfigurieren
-
Beschränken von Failovers, die durch Routenmonitore im Nicht-INC-Modus verursacht werden
-
HA-Heartbeat-Meldungen auf einer NetScaler-Appliance verwalten
-
NetScaler in einem Hochverfügbarkeitssetup entfernen und ersetzen
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Verwenden Sie NetScaler Console, um Probleme mit NetScaler Cloud Native Networking zu beheben
Übersicht
Dieses Dokument enthält Informationen darüber, wie Sie NetScaler Console verwenden können, um Kubernetes-Microservice-Anwendungen bereitzustellen und zu überwachen. Sie beschäftigen sich auch mit der Verwendung der CLI, der Dienstdiagramme und der Ablaufverfolgung, damit die Plattform- und SRE-Teams Probleme beheben können.
Überblick über Anwendungsleistung und Latenz
TLS-Verschlüsselung
TLS ist ein Verschlüsselungsprotokoll zur Sicherung der Internetkommunikation. Ein TLS-Handshake ist der Prozess, der eine Kommunikationssitzung startet, die TLS-Verschlüsselung verwendet. Während eines TLS-Handshakes tauschen die beiden kommunizierenden Seiten Nachrichten aus, um sich gegenseitig zu bestätigen, sich gegenseitig zu verifizieren, die von ihnen verwendeten Verschlüsselungsalgorithmen festzulegen und Sitzungsschlüssel zu vereinbaren. TLS-Handshakes sind ein grundlegender Bestandteil der Funktionsweise von HTTPS.
TLS im Vergleich zu SSL-Handshakes
SSL (Secure Sockets Layer) war das ursprüngliche Verschlüsselungsprotokoll, das für HTTP entwickelt wurde. TLS (Transport Layer Security) hat SSL vor einiger Zeit ersetzt. SSL-Handshakes werden jetzt TLS-Handshakes genannt, obwohl der Name “SSL” immer noch weit verbreitet ist.
Wann findet ein TLS-Handshake statt?
Ein TLS-Handshake findet immer dann statt, wenn ein Benutzer über HTTPS zu einer Website navigiert und der Browser zuerst den Original-Server der Website abfragt. Ein TLS-Handshake findet auch dann statt, wenn andere Kommunikationen HTTPS verwenden, einschließlich API-Aufrufe und DNS-über-HTTPS-Abfragen.
TLS-Handshakes treten auf, nachdem eine TCP-Verbindung über einen TCP-Handshake geöffnet wurde.
Was passiert während eines TLS-Handshakes?
- Während eines TLS-Handshakes führen der Client und der Server zusammen Folgendes aus:
- Geben Sie an, welche Version von TLS (TLS 1.0, 1.2, 1.3 usw.) sie verwenden.
- Entscheiden Sie, welche Verschlüsselungssammlungen (siehe folgenden Abschnitt) sie verwenden.
- Authentifizieren Sie die Identität des Servers über den öffentlichen Schlüssel des Servers und die digitale Signatur der SSL-Zertifizierungsstelle.
- Generieren Sie Sitzungsschlüssel, um die symmetrische Verschlüsselung zu verwenden, nachdem der Handshake abgeschlossen ist.
Was sind die Schritte eines TLS-Handshakes?
- TLS-Handshakes sind eine Reihe von Datagrammen oder Nachrichten, die von einem Client und einem Server ausgetauscht werden. Ein TLS-Handshake umfasst mehrere Schritte, da der Client und der Server die Informationen austauschen, die für den Abschluss des Handshakes und die Ermöglichung weiterer Konversationen erforderlich sind.
Die genauen Schritte innerhalb eines TLS-Handshakes variieren je nach Art des verwendeten Schlüsselaustauschalgorithmus und den von beiden Seiten unterstützten Verschlüsselungssammlungen. Der RSA-Schlüsselaustauschalgorithmus wird am häufigsten verwendet. Es geht wie folgt:
- Die ‘Client-Hallo’-Nachricht: Der Client initiiert den Handshake, indem er eine “Hallo” -Nachricht an den Server sendet. Die Meldung enthält, welche TLS-Version der Client unterstützt, welche Verschlüsselungssammlungen unterstützt werden und eine Reihe von zufälligen Bytes, die als “client random” bezeichnet werden.
- Die “Server-Hallo” -Meldung: Als Antwort auf die Hello-Nachricht des Clients sendet der Server eine Nachricht mit dem SSL-Zertifikat des Servers, der vom Server ausgewählten Verschlüsselungssammlung und dem “zufälligen Server”, einer weiteren zufälligen Bytefolge, die vom Server generiert wird.
- Authentifizierung: Der Client überprüft das SSL-Zertifikat des Servers bei der Zertifizierungsstelle, die es ausgestellt hat. Dies bestätigt, dass der Server der ist, für den er sich ausgibt, und dass der Client mit dem tatsächlichen Eigentümer der Domäne interagiert.
- Das Premaster-Secret: Der Client sendet eine weitere zufällige Bytefolge, das “premaster secret”. Das Premaster-Secret ist mit dem öffentlichen Schlüssel verschlüsselt und kann nur mit dem privaten Schlüssel vom Server entschlüsselt werden. (Der Client erhält den öffentlichen Schlüssel aus dem SSL-Zertifikat des Servers.)
- Verwendeter privater Schlüssel: Der Server entschlüsselt das Premaster-Secret.
- Sitzungsschlüssel erstellt: Sowohl der Client als auch der Server generieren Sitzungsschlüssel aus dem zufälligen Client, dem zufälligen Server und dem Premaster-Secret. Sie sollten zu den gleichen Ergebnissen kommen.
- Der Client ist bereit: Der Client sendet eine “fertige” Nachricht, die mit einem Sitzungsschlüssel verschlüsselt ist.
- Server ist bereit: Der Server sendet eine “fertige” Nachricht, die mit einem Sitzungsschlüssel verschlüsselt ist.
- Sichere symmetrische Verschlüsselung erreicht: Der Handshake ist abgeschlossen und die Kommunikation wird unter Verwendung der Sitzungsschlüssel fortgesetzt.
Alle TLS-Handshakes verwenden eine asymmetrische Verschlüsselung (den öffentlichen und privaten Schlüssel), aber nicht alle verwenden den privaten Schlüssel beim Generieren von Sitzungsschlüsseln. Ein kurzlebiger Diffie-Hellman-Handschlag läuft beispielsweise wie folgt ab:
- Client-Hallo: Der Client sendet eine Client-Hello-Nachricht mit der Protokollversion, dem zufälligen Client und einer Liste von Verschlüsselungssammlungen.
- Server-Hallo: Der Server antwortet mit seinem SSL-Zertifikat, seiner ausgewählten Verschlüsselungssammlung und dem Server zufällig. Im Gegensatz zu dem im vorherigen Abschnitt beschriebenen RSA-Handshake enthält der Server in dieser Nachricht auch Folgendes (Schritt 3).
- Digitale Signatur des Servers: Der Server verwendet seinen privaten Schlüssel, um den Client zufällig, den Server zufällig und seinen DH-Parameter* zu verschlüsseln. Diese verschlüsselten Daten fungieren als digitale Signatur des Servers und stellen fest, dass der Server über den privaten Schlüssel verfügt, der mit dem öffentlichen Schlüssel aus dem SSL-Zertifikat übereinstimmt.
- Digitale Signatur bestätigt: Der Client entschlüsselt die digitale Signatur des Servers mit dem öffentlichen Schlüssel und überprüft, ob der Server den privaten Schlüssel kontrolliert und wer er vorgibt zu sein. Client-DH-Parameter: Der Client sendet seinen DH-Parameter an den Server.
- Client und Server berechnen das Premaster-Secret: Anstatt dass der Client das Premaster-Secret generiert und an den Server sendet, wie bei einem RSA-Handshake, verwenden der Client und der Server die ausgetauschten DH-Parameter, um ein passendes Premaster-Secret separat zu berechnen.
- Sitzungsschlüssel erstellt: Jetzt berechnen der Client und der Server Sitzungsschlüssel aus dem Premaster-Secret, dem Client zufällig und dem Server zufällig, genau wie bei einem RSA-Handshake.
-
- Der Kunde ist bereit
- Wie ein RSA-Handshake
- Server ist bereit
- Sichere symmetrische Verschlüsselung erreicht
*DH-Parameter: DH steht für Diffie-Hellman. Der Diffie-Hellman-Algorithmus verwendet Exponentialberechnungen, um zum selben Premaster-Secret zu gelangen. Der Server und der Client stellen jeweils einen Parameter für die Berechnung bereit, und wenn sie kombiniert werden, führen sie zu einer anderen Berechnung auf jeder Seite, wobei die Ergebnisse gleich sind.
-
Weitere Informationen zum Kontrast zwischen kurzlebigen Diffie-Hellman-Handshakes und anderen Arten von Handshakes und wie sie eine Vorwärtsgeheimnis erreichen, finden Sie in dieser TLS-Protokolldokumentation.
Was ist eine Verschlüsselungssammlung?
- Eine Verschlüsselungssuite ist eine Reihe von Verschlüsselungsalgorithmen, die beim Aufbau einer sicheren Kommunikationsverbindung verwendet werden. (Ein Verschlüsselungsalgorithmus ist eine Reihe mathematischer Operationen, die an Daten ausgeführt werden, um die Daten zufällig erscheinen zu lassen.) Es gibt verschiedene Verschlüsselungssammlungen, die weit verbreitet sind, und ein wesentlicher Bestandteil des TLS-Handshakes ist die Vereinbarung, welche Verschlüsselungssammlung für diesen Handshake verwendet wird.
Für die ersten Schritte siehe Referenz: TLS-Protokolldokumentation.
NetScaler Application Delivery Management SSL-Dashboard
NetScaler Application Delivery Management (ADM) optimiert jetzt jeden Aspekt der Zertifikatsverwaltung für Sie. Über eine einzige Konsole können Sie automatisierte Richtlinien einrichten, um den richtigen Aussteller, die richtige Schlüsselstärke und korrekte Algorithmen sicherzustellen, während Sie nicht verwendete oder bald ablaufende Zertifikate im Auge behalten. Um mit der Verwendung des NetScaler Console SSL-Dashboards und seiner Funktionen zu beginnen, müssen Sie verstehen, was ein SSL-Zertifikat ist und wie Sie NetScaler Console verwenden können, um Ihre SSL-Zertifikate zu verfolgen.
Ein SSL-Zertifikat (Secure Socket Layer), das Teil einer SSL-Transaktion ist, ist ein digitales Eingabeformular (X509), das ein Unternehmen (Domain) oder eine Person identifiziert. Das Zertifikat verfügt über eine Public-Key-Komponente, die für jeden Client sichtbar ist, der eine sichere Transaktion mit dem Server initiieren möchte. Der entsprechende private Schlüssel, der sich sicher auf der Citrix Application Delivery Controller (ADC) -Appliance befindet, wird verwendet, um die Verschlüsselung und Entschlüsselung des asymmetrischen Schlüssels (oder des öffentlichen Schlüssels) abzuschließen.
Sie können ein SSL-Zertifikat und einen Schlüssel auf eine der folgenden Arten beziehen:
- Von einer autorisierten Zertifizierungsstelle (CA)
- Durch Generieren eines neuen SSL-Zertifikats und eines neuen Schlüssels auf der NetScaler-Appliance
Die NetScaler Console bietet eine zentrale Ansicht der SSL-Zertifikate, die auf allen verwalteten NetScaler-Instanzen installiert sind. Im SSL-Dashboard können Sie Diagramme anzeigen, mit denen Sie Zertifikatsaussteller, wichtige Stärken, Signaturalgorithmen, abgelaufene oder nicht verwendete Zertifikate usw. nachverfolgen können. Sie können auch die Verteilung der SSL-Protokolle sehen, die auf Ihren virtuellen Servern ausgeführt werden, und die Schlüssel, die auf ihnen aktiviert sind.
Sie können auch Benachrichtigungen einrichten, um Sie darüber zu informieren, wann Zertifikate ablaufen werden, und Informationen darüber enthalten, welche NetScaler-Instanzen diese Zertifikate verwenden.
Sie können die Zertifikate einer NetScaler Instanz mit einem Zertifizierungsstellenzertifikat verknüpfen. Stellen Sie jedoch sicher, dass die Zertifikate, die Sie mit demselben CA-Zertifikat verknüpfen, dieselbe Quelle und denselben Aussteller haben. Nachdem Sie die Zertifikate mit einem CA-Zertifikat verknüpft haben, können Sie die Verknüpfung aufheben.
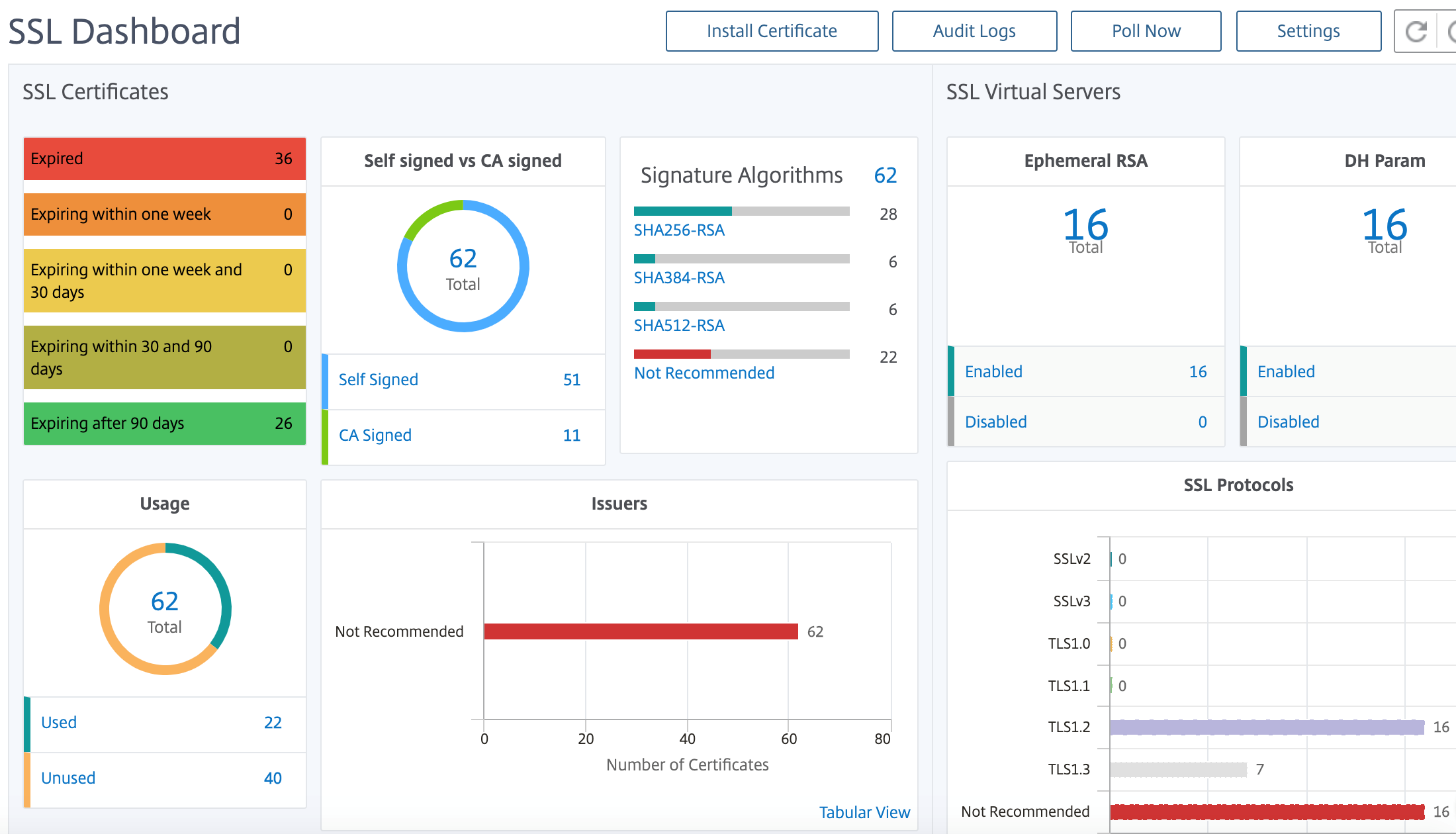
Um loszulegen, lesen Sie die SSL-Dashboard-Dokumentation.
Integrationen von Drittanbietern
Die Anwendungslatenz wird in Millisekunden gemessen und kann je nach verwendeter Metrik eines von zwei Dingen anzeigen. Die gebräuchlichere Methode zur Messung der Latenz wird als “Round-Trip-Zeit” (oder RTT) bezeichnet. RTT berechnet die Zeit, die ein Datenpaket benötigt, um im Netzwerk von einem Punkt zum anderen zu gelangen und eine Antwort an die Quelle zurückzusenden. Die andere Messung wird als “Time to First Byte” (oder TTFB) bezeichnet und zeichnet die Zeit auf, die vom Zeitpunkt, an dem ein Paket einen Punkt im Netzwerk verlässt, bis zu dem Moment, zu dem es an seinem Ziel ankommt, benötigt wird. RTT wird häufiger zur Messung der Latenz verwendet, da es von einem einzigen Punkt im Netzwerk aus ausgeführt werden kann und keine Datenerfassungssoftware auf dem Zielpunkt installiert werden muss (wie dies bei TTFB der Fall ist).
Durch die Überwachung der Bandbreitennutzung und -leistung Ihrer Anwendung in Echtzeit erleichtert der ADM-Dienst die Identifizierung von Problemen und die vorbeugende Behandlung potenzieller Probleme, bevor sie sich manifestieren und Benutzer in Ihrem Netzwerk betreffen. Diese Flow-basierte Lösung verfolgt die Nutzung nach Schnittstelle, Anwendung und Konversation und liefert Ihnen detaillierte Informationen zu Aktivitäten in Ihrem Netzwerk.
Verwenden von Splunk-Tools
Infrastruktur und Anwendungsleistung sind voneinander abhängig. Um das vollständige Bild zu sehen, bietet SignalFX eine nahtlose Korrelation zwischen der Cloud-Infrastruktur und den darauf laufenden Microservices. Wenn Ihre Anwendung aufgrund von Speicherverlust, einem verrauschten Nachbarcontainer oder einem anderen infrastrukturbezogenen Problem auftritt, informiert SignalFX Sie darüber. Um das Bild zu vervollständigen, ermöglicht der kontextbezogene Zugriff auf Splunk-Protokolle und -Ereignisse eine tiefere Fehlerbehebung und Ursachenanalyse.
Weitere Informationen zu SignalFX Microservices APM und zur Fehlerbehebung mit Splunk finden Sie unter Splunk für DevOps-Informationen.
MongoDB-Unterstützung
MongoDB speichert Daten in flexiblen, JSON-ähnlichen Dokumenten. Bedeutungsfelder können von Dokument zu Dokument variieren und die Datenstruktur kann im Laufe der Zeit geändert werden.
Das Dokumentmodell wird den Objekten in Ihrem Anwendungscode zugeordnet, sodass Sie problemlos mit Daten arbeiten können.
On-Demand-Abfragen, Indizierung und Echtzeitaggregation bieten leistungsstarke Möglichkeiten, auf Ihre Daten zuzugreifen und sie zu analysieren.
MongoDB ist im Kern eine verteilte Datenbank, sodass Hochverfügbarkeit, horizontale Skalierung und geografische Verteilung integriert und einfach zu bedienen sind.
MongoDB wurde entwickelt, um die Anforderungen moder ner Apps mit einer technologischen Grundlage zu erfüllen, die Ihnen Folgendes ermöglicht:
- Das Dokumentdatenmodell — das Ihnen die beste Art bietet, mit Daten zu arbeiten.
- Ein Design verteilter Systeme, mit dem Sie Daten intelligent dort ablegen können, wo Sie sie haben möchten.
- Ein einheitliches Erlebnis, das Ihnen die Freiheit gibt, überall zu arbeiten, sodass Sie Ihre Arbeit zukunftssicher machen und die Anbieterbindung vermeiden können.
Mit diesen Funktionen können Sie eine Intelligent Operational Data Platform aufbauen, die von MongoDB unterstützt wird. Weitere Informationen finden Sie in der MongoDB-Dokumentation.
Lastenausgleich für eingehenden Datenverkehr zu TCP- oder UDP-basierten Anwendungen
In einer Kubernetes-Umgebung ist ein Ingress ein Objekt, das den Zugriff auf die Kubernetes-Dienste von außerhalb des Kubernetes-Clusters ermöglicht. Bei Standard-Kubernetes Ingress-Ressourcen wird davon ausgegangen, dass der gesamte Datenverkehr HTTP-basiert ist und keine nicht-HTTP-basierten Protokolle wie TCP, TCP-SSL und UDP unterstützt. Daher können kritische Anwendungen, die auf L7-Protokollen wie DNS, FTP, LDAP basieren, nicht mit Standard-Kubernetes Ingress verfügbar gemacht werden.
Die Kubernetes-Standardlösung besteht darin, einen Dienst vom Typ LoadBalancer zu erstellen. Weitere Informationen finden Sie unter Service Type LoadBalancer in NetScaler.
Die zweite Option besteht darin, das Eingangsobjekt mit Anmerkungen zu versehen. Mit dem NetScaler Ingress Controller können Sie den Lastausgleich von TCP- oder UDP-basiertem Ingress-Verkehr durchführen. Es enthält die folgenden Anmerkungen, die Sie in Ihrer Kubernetes Ingress-Ressourcendefinition verwenden können, um den TCP- oder UDP-basierten Ingress-Datenverkehr zu belasten:
- ingress.citrix.com/insecure-service-type: Die Annotation ermöglicht den L4-Lastausgleich mit TCP, UDP oder ANY als Protokoll für NetScaler.
- ingress.citrix.com/insecure-port: Die Annotation konfiguriert den TCP-Port. Die Anmerkung ist hilfreich, wenn Micro-Service-Zugriff an einem nicht standardmäßigen Port erforderlich ist. Standardmäßig ist Port 80 konfiguriert.
Überwachen und verbessern Sie die Leistung Ihrer TCP- oder UDP-basierten Anwendungen
Anwendungsentwickler können den Zustand von TCP- oder UDP-basierten Anwendungen über umfangreiche Monitore (wie TCP-ECV, UDP-ECV) in NetScaler genau überwachen. Die ECV-Monitore (Extended Content Validation) helfen bei der Überprüfung, ob die Anwendung erwarteten Inhalt zurückgibt oder nicht.
Die Anwendungsleistung kann auch verbessert werden, indem Persistenzmethoden wie Quell-IP verwendet werden. Sie können diese NetScaler-Funktionen über Smart Annotations in Kubernetes verwenden. Das Folgende ist ein Beispiel:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: mongodb
annotations:
ingress.citrix.com/insecure-port: “80”
ingress.citrix.com/frontend-ip: “192.168.1.1”
ingress.citrix.com/csvserver: ‘{“l2conn”:”on”}’
ingress.citrix.com/lbvserver: ‘{“mongodb-svc”:{“lbmethod”:”SRCIPDESTIPHASH”}}’
ingress.citrix.com/monitor: ‘{“mongodbsvc”:{“type”:”tcp-ecv”}}’
Spec:
rules:
- host: mongodb.beverages.com
http:
paths:
- path: /
backend:
serviceName: mongodb-svc
servicePort: 80
<!--NeedCopy-->
NetScaler Application Delivery Management (ADM) -Dienst
NetScaler Console Service bietet die folgenden Vorteile:
- Agilität — Einfach zu bedienen, zu aktualisieren und zu verwenden. Das Servicemodell von NetScaler Console Service ist über die Cloud verfügbar, sodass die bereitgestellten Funktionen einfach zu bedienen, zu aktualisieren und zu verwenden sind. Die Häufigkeit von Updates in Kombination mit der automatischen Update-Funktion verbessert die NetScaler Bereitstellung schnell.
- Schnellere Wertschöpfung — Schnellere Erreichung der Geschäftsziele. Im Gegensatz zur herkömmlichen on-premises Bereitstellung können Sie Ihren NetScaler Console Service mit wenigen Klicks verwenden. Sie sparen nicht nur Installations- und Konfigurationszeit, sondern verschwenden auch Zeit und Ressourcen für potenzielle Fehler.
- Verwaltung mehrerer Standorte — Single Pane of Glass für Instanzen in Rechenzentren mit mehreren Standorten. Mit dem NetScaler Console Service können Sie NetScaler verwalten und überwachen, die sich in verschiedenen Bereitstellungstypen befinden. Sie haben eine zentrale Verwaltung für NetScaler, die on-premises und in der Cloud bereitgestellt werden.
- Betriebseffizienz — Optimierte und automatisierte Methode zur Erzielung höherer Betriebsproduktivität. Mit dem NetScaler Console Service werden Ihre Betriebskosten reduziert, da Sie Zeit, Geld und Ressourcen für die Wartung und Aktualisierung der herkömmlichen Hardwarebereitstellungen sparen.
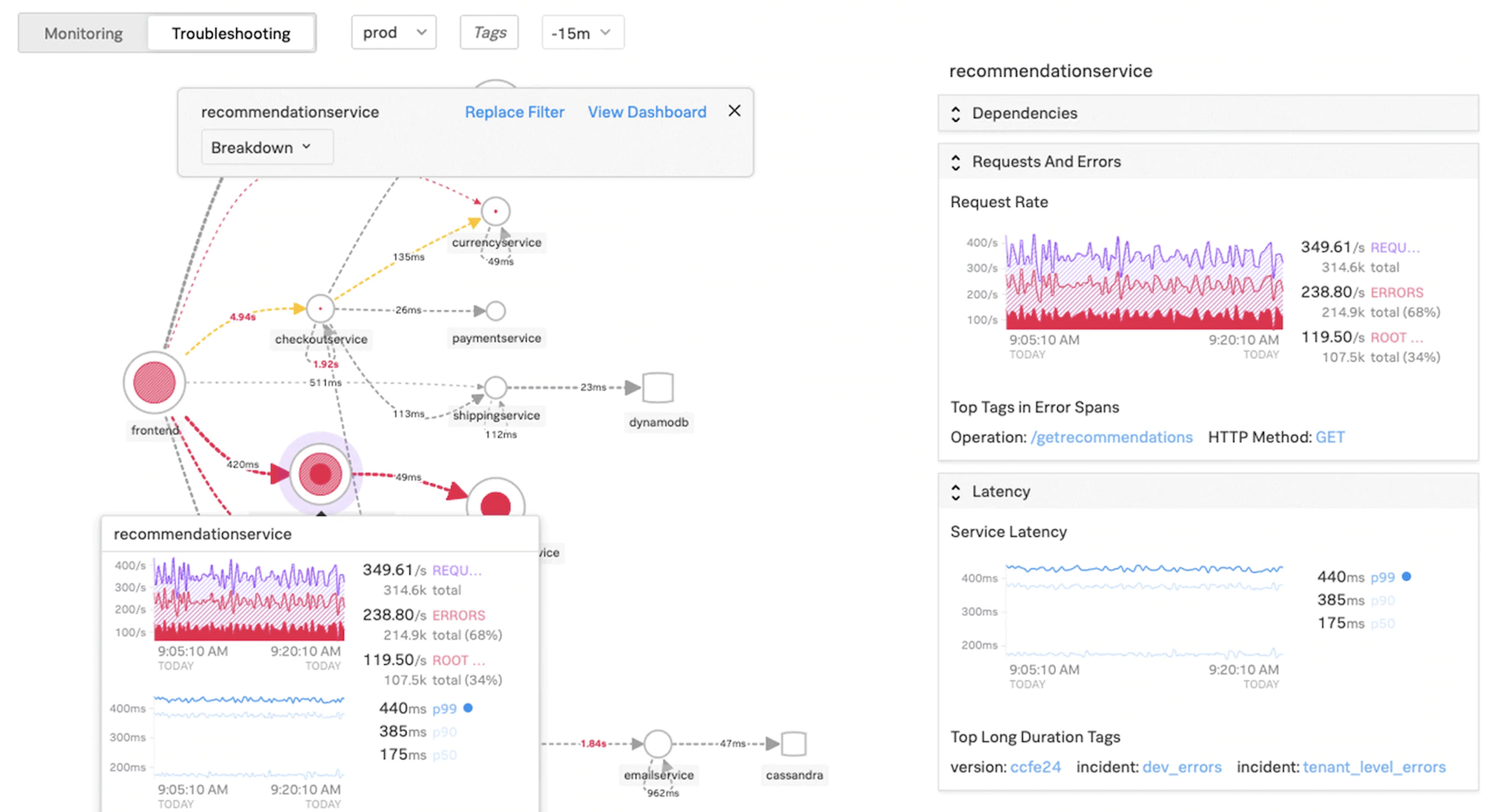
Service-Diagramm für Kubernetes-Anwendungen
Mit dem Service Graph für die cloudnative Anwendungsfunktion in NetScaler Console können Sie:
- Sicherstellung der Gesamtleistung der Anwendung durch End-to-End-Anwendung
- Identifizieren Sie Engpässe, die durch die gegenseitige Abhängigkeit verschiedener Komponenten Ihrer Anwendungen entstehen
- Sammeln Sie Einblicke in die Abhängigkeiten der verschiedenen Komponenten Ihrer Anwendungen
- Überwachen Sie Dienste innerhalb des Kubernetes-Clusters
- Überwachen Sie, welcher Dienst Probleme hat
- Prüfen Sie die Faktoren, die zu Leistungsproblemen beitragen
- Detaillierte Sichtbarkeit der HTTP-Transaktionen des Dienstes anzeigen
- Analysieren der HTTP-, TCP- und SSL-Metriken
Durch die Visualisierung dieser Metriken in NetScaler Console können Sie die Ursache von Problemen analysieren und die erforderlichen Maßnahmen zur Problembehandlung schneller ergreifen. Service Graph zeigt Ihre Anwendungen in verschiedenen Komponentendiensten an. Diese Dienste, die innerhalb des Kubernetes-Clusters ausgeführt werden, können mit verschiedenen Komponenten innerhalb und außerhalb der Anwendung kommunizieren.
Informationen zu den ersten Schritten finden Sie unter Service Graph einrichten.
Service-Diagramm für dreistufige Webanwendungen
Mit der Service Graph-Funktion aus dem Anwendungs-Dashboard können Sie Folgendes anzeigen:
- Details zur Konfiguration der Anwendung (mit dem virtueller Content Switching-Server und dem virtuellen Load Balancing-Server)
- Für GSLB-Anwendungen können Sie Rechenzentrum, ADC-Instanz, virtuelle CS- und LB-Server anzeigen
- Ende-zu-Ende-Transaktionen vom Kunden zum Service
- Der Ort, von dem aus der Client auf die Anwendung zugreift
- Der Name des Rechenzentrums, in dem die Clientanforderungen verarbeitet werden, und die zugehörigen NetScaler-Metriken des Rechenzentrums (nur für GSLB-Anwendungen)
- Metrikdetails für Client, Service und virtuelle Server
- Wenn die Fehler vom Kunden oder vom Dienst stammen
- Der Dienststatus, z. B. Kritisch, Überprüfung und Gut. NetScaler Console zeigt den Dienststatus basierend auf der Antwortzeit des Dienstes und der Fehleranzahl an.
- Kritisch (rot) — Zeigt an, wenn die durchschnittliche Reaktionszeit des Service > 200 ms UND Fehlerzahl > 0
- Überprüfung (orange) — Zeigt an, wenn die durchschnittliche Reaktionszeit des Service > 200 ms ODER Fehlerzahl > 0
- Gut (grün) — Zeigt keinen Fehler an und durchschnittliche Reaktionszeit < 200 ms
- Der Clientstatus, z. B. Kritisch, Überprüfung und Gut. NetScaler Console zeigt den Clientstatus auf der Grundlage der Client-Netzwerklatenz und der Fehleranzahl an.
- Kritisch (rot)— Zeigt an, wenn die durchschnittliche Netzwerklatenz des Clients > 200 ms UND Fehleranzahl > 0
- Überprüfung (orange) — Zeigt an, wenn die durchschnittliche Clientnetzwerklatenz > 200 ms ODER Fehlerzahl > 0
- Gut (grün) — Zeigt keinen Fehler an und durchschnittliche Latenz des Client-Netzwerks < 200 ms
- Der Status des virtuellen Servers, z. B. Kritisch, Überprüfung und Gut. NetScaler Console zeigt den Status des virtuellen Servers auf der Grundlage der App-Punktzahl an.
- Kritisch (rot) — Zeigt an, wenn der App-Wert < 40 ist
- Überprüfung (orange) — Zeigt an, wenn der App-Score zwischen 40 und 75 liegt
- Gut (grün) — Zeigt an, wenn der App-Score > 75 ist
Zu beachtende Punkte:
- Im Service-Diagramm werden nur Load Balancing, Content Switching und virtuelle GSLB-Server angezeigt.
- Wenn kein virtueller Server an eine benutzerdefinierte Anwendung gebunden ist, sind die Details im Service-Diagramm für die Anwendung nicht sichtbar.
- Sie können Metriken für Clients und Services im Service-Diagramm nur anzeigen, wenn aktive Transaktionen zwischen virtuellen Servern und Webanwendung stattfinden.
- Wenn keine aktiven Transaktionen zwischen virtuellen Servern und der Webanwendung verfügbar sind, können Sie Details im Service-Diagramm nur basierend auf den Konfigurationsdaten wie Load Balancing, Content Switching, virtuelle GSLB-Server und Dienste anzeigen.
- Es kann 10 Minuten dauern, bis Aktualisierungen in der Anwendungskonfiguration im Service-Diagramm angezeigt werden.
Weitere Informationen finden Sie unter Service-Diagramm für Anwendungen.
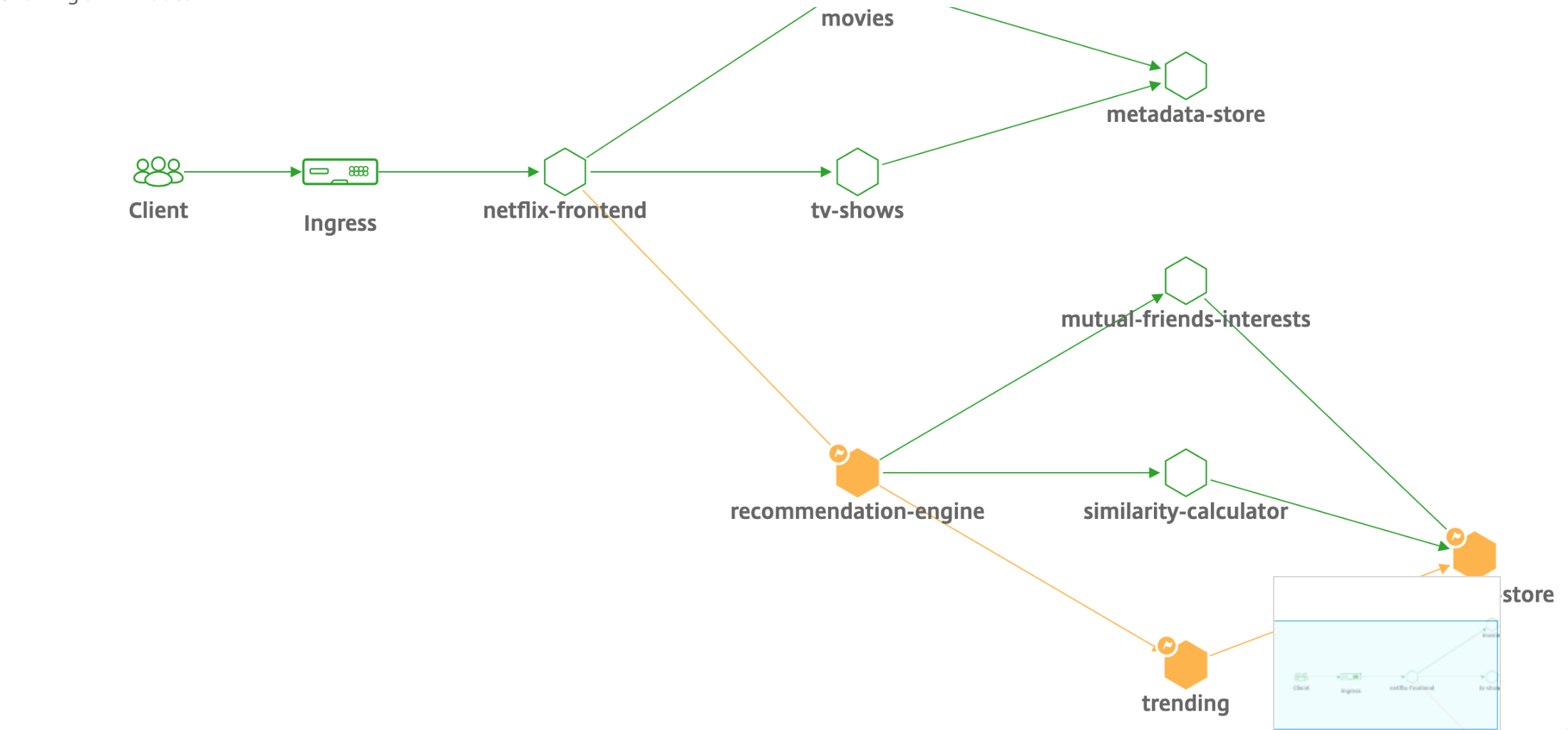
Informationen zum Einstieg finden Sie in der Service Graph-Dokumentation.
Fehlerbehebung für NetScaler-Teams
Lassen Sie uns einige der häufigsten Attribute für die Fehlerbehebung bei der NetScaler-Plattform besprechen und wie diese Techniken zur Fehlerbehebung auf die Tier-1-Bereitstellungen für Microservices-Topologien angewendet werden.
Der NetScaler verfügt über eine Befehlszeilenschnittstelle (CLI), die Befehle in Echtzeit anzeigt und zum Bestimmen von Laufzeitkonfigurationen, Statik und Richtlinienkonfiguration nützlich ist. Dies wird über den Befehl “SHOW” erleichtert.
SHOW - ADC-CLI-Operationen ausführen:
>Show running config (-summary -fullValues)
Ability to search (grep command)
>“sh running config | -i grep vserver”
Check the version.
>Show license
“sh license"
<!--NeedCopy-->
SSL Statistiken anzeigen
>Sh ssl
System
Frontend
Backend
Encryption
<!--NeedCopy-->
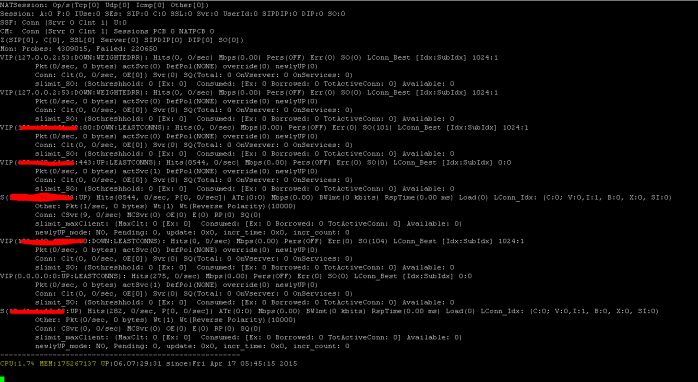
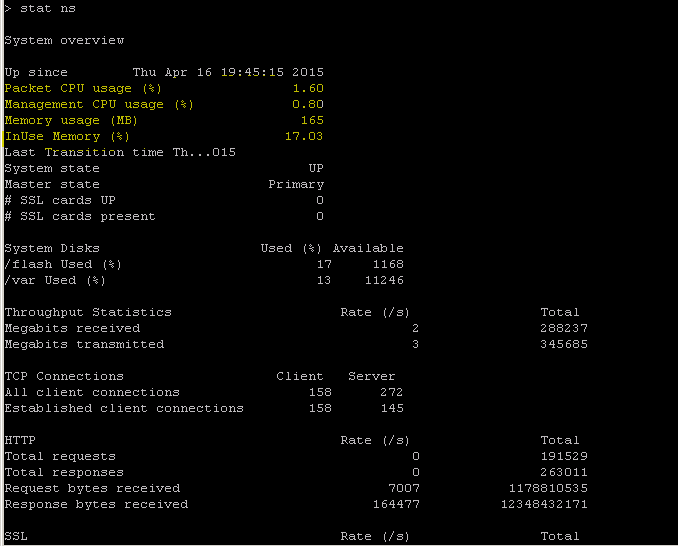
Der NetScaler verfügt über einen Befehl zum Aufzählen von Statistiken für alle Objekte basierend auf einem Zählerintervall von sieben (7) Sekunden. Dies wird über den Befehl “STAT” erleichtert.
Hochgranulare L3-L7-Telemetrie von NetScaler
- Systemebene: CPU- und Speicherauslastung von ADC.
- HTTP-Protokoll: #Requests /Responses, GET/POST Split, HTTP-Fehler für N-S und E-W (nur für Service Mesh Lite, Sidecar bald).
- SSL: #Sessions und #Handshakes nur für N-S- und E-W-Verkehr für Service Mesh Lite.
- IP-Protokoll: #Packets empfangen/gesendet, #Bytes empfangen/gesendet, #Truncated -Pakete und #IP Adresssuche.
- NetScaler AAA: #Active -Sitzungen
- Schnittstelle: #Total Multicast-Pakete, #Total übertragene Bytes und #Jumbo -Pakete empfangen/gesendet.
- Virtueller Lastenausgleichsserver und virtueller Content Switching-Server: #Packets, #Hits und #Bytes empfangen/gesendet.
STAT - ADC-CLI-Operationen ausführen:
>Statistics
“stat ssl”
<!--NeedCopy-->
Der NetScaler verfügt über eine Protokollarchivstruktur, die das Durchsuchen von Statistiken und Leistungsindikatoren bei der Behandlung bestimmter Fehler über den Befehl “NSCONMSG” ermöglicht.
NSCONMSG - Haupt-Protokolldatei (NS-Datenformat)
Cd/var/nslog
“Mac Moves”
nsconmsg -d current -g nic_err
<!--NeedCopy-->
Nstcpdump
Sie können nstcpdump für die Fehlerbehebung auf niedriger Ebene verwenden. nstcpdump sammelt weniger detaillierte Informationen als nstrace. Öffnen Sie die ADC-CLI und geben Sie ein shell. Sie können Filter mit verwenden nstcpdump, aber keine für ADC-Ressourcen spezifischen Filter verwenden. Die Dump-Ausgabe kann direkt im CLI-Bildschirm angezeigt werden.
CTRL + C — Drücken Sie diese Tasten gleichzeitig, um eine zu stoppen nstcpdump.
nstcpdump.sh dst host x.x.x.x — Zeigt den an den Zielhost gesendeten Datenverkehr an.
nstcpdump.sh -n src host x.x.x.x — Zeigt den Datenverkehr vom angegebenen Host an und wandelt keine IP-Adressen in Namen um (-n).
nstcpdump.sh host x.x.x.x — Zeigt den Datenverkehr zu und von der angegebenen Host-IP an.
NSTRACE - Paket-Trace-Datei
NSTRACE ist ein Paket-Debugging-Tool auf niedriger Ebene zur Fehlerbehebung bei Netzwerken. Es ermöglicht Ihnen, Capture-Dateien zu speichern, die Sie mit den Analysewerkzeugen weiter analysieren können. Zwei gängige Tools sind Network Analyzer und Wireshark.
Sobald die NSTRACE-Capture-Datei in /var/nstrace auf dem ADC erstellt wurde, können Sie die Capture-Datei zur Paketerfassung und Netzwerkanalyse in Wireshark importieren.
SYSCTL - Ausführliche ADC-Informationen: Beschreibung, Modell, Plattform, CPUs usw
sysctl -a grep hw.physmem
hw.physmem: 862306304
netscaler.hw_physmem_mb: 822
<!--NeedCopy-->
aaad.debug - Open Pipe für Debug-Informationen zur Authentifizierung

Weitere Informationen zur Behebung von Authentifizierungsproblemen über ADC oder ADC Gateway mit dem Modul aaad.debug finden Sie im aaad.debug-Supportartikel.
Es besteht auch die Möglichkeit, Leistungsstatistiken und Ereignisprotokolle direkt für den ADC abzurufen. Weitere Informationen dazu finden Sie im ADC-Supportdokument.
Fehlerbehebung für SRE und Plattformteams
Kubernetes-Verkehrsströme
Norden/Süden:
- Nord/Süd-Verkehr ist der Datenverkehr, der vom Benutzer über den Ingress in den Cluster fließt.
Ost/West:
- Der Ost/West-Verkehr ist der Verkehr, der um den Kubernetes-Cluster fließt: Service-to-Service oder Service-zu-Datenspeicher.
Wie NetScaler CPX-Last den Ost-West-Verkehrsfluss in einer Kubernetes-Umgebung ausgleicht
Nachdem Sie den Kubernetes-Cluster bereitgestellt haben, müssen Sie den Cluster in ADM integrieren, indem Sie die Details der Kubernetes-Umgebung in ADM angeben. ADM überwacht die Änderungen der Kubernetes-Ressourcen wie Dienste, Endpunkte und Ingress-Regeln.
Wenn Sie eine NetScaler CPX-Instanz im Kubernetes-Cluster bereitstellen, registriert sie sich automatisch bei ADM. Im Rahmen des Registrierungsprozesses erfährt ADM mehr über die IP-Adresse der CPX-Instanz und den Port, über den es die Instanz erreichen kann, um sie mithilfe von NITRO REST-APIs zu konfigurieren.
Die folgende Abbildung zeigt, wie NetScaler CPX den Ost-West-Traffic-Flow in einem Kubernetes-Cluster ausgleicht.
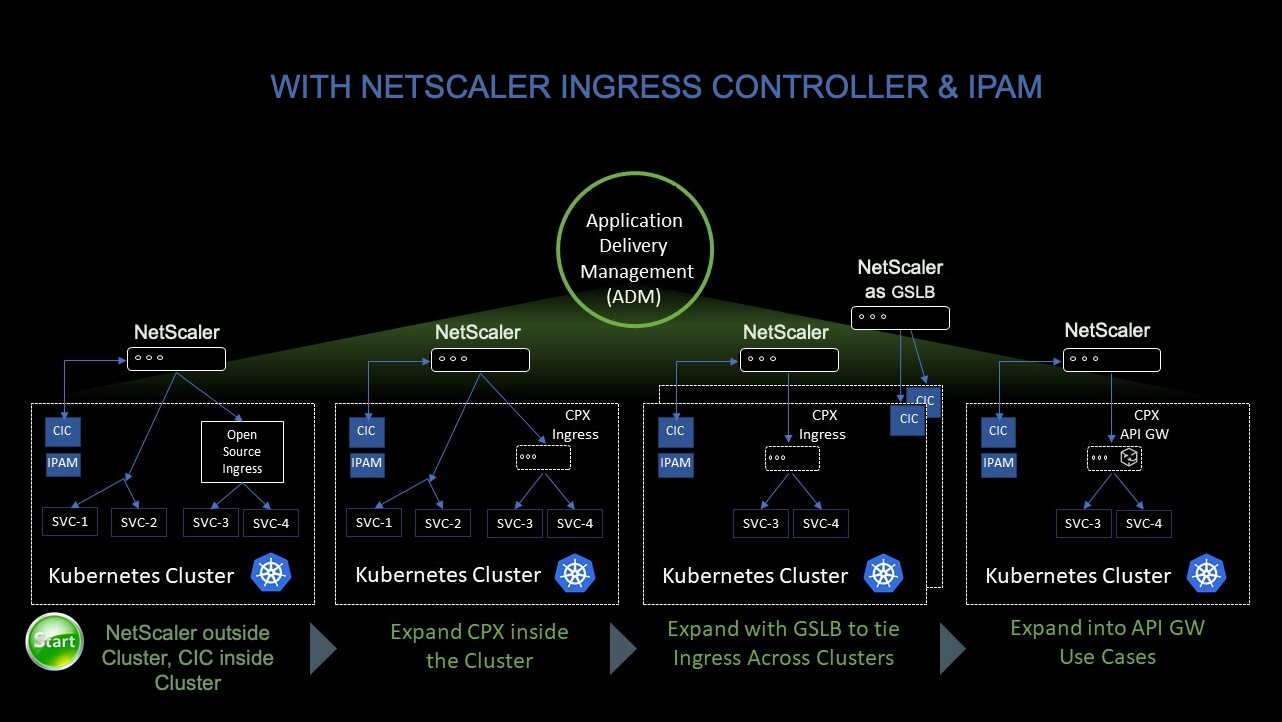
In diesem Beispiel wird
Knoten 1 und Knoten 2 der Kubernetes-Cluster enthalten Instanzen eines Front-End-Dienstes und eines Back-End-Dienstes. Wenn die NetScaler CPX-Instanzen in Knoten 1 und Knoten 2 bereitgestellt werden, werden die NetScaler CPX-Instanzen automatisch bei ADM registriert. Sie müssen den Kubernetes-Cluster manuell in ADM integrieren, indem Sie die Kubernetes-Clusterdetails in ADM konfigurieren.
Wenn ein Client den Front-End-Dienst anfordert, gleicht die eingehende Ressourcenlast die Anforderung zwischen den Instanzen des Front-End-Dienstes auf den beiden Knoten aus. Wenn eine Instanz des Front-End-Dienstes Informationen von den Back-End-Diensten im Cluster benötigt, leitet sie die Anfragen an die NetScaler CPX-Instanz in ihrem Knoten weiter. Diese NetScaler CPX-Instanz verteilt die Anforderungen zwischen den Back-End-Diensten im Cluster und sorgt so für einen Ost-West-Traffic.
ADM Service Graph für Anwendungen
Mit der Service Graph-Funktion in NetScaler Console können Sie alle Dienste in einer grafischen Darstellung überwachen. Diese Funktion bietet auch eine detaillierte Analyse und nützliche Metriken. Sie können Service-Diagramme anzeigen für:
- Für alle NetScaler-Instanzen konfigurierte Anwendungen
- Kubernetes-Anwendungen
- 3-stufige Webanwendungen
Um loszulegen, sehen Sie sich die Details im Service Graphan.
Zähler für Microservice-Anwendungen anzeigen
Das Service-Diagramm zeigt auch alle Microservice-Anwendungen an, die zu den Kubernetes-Clustern gehören. Der Mauszeiger auf einem Service, um die Metrik-Details anzuzeigen.
Sie können Folgendes anzeigen:
- Der Dienstname
- Das vom Dienst verwendete Protokoll wie SSL, HTTP, TCP, SSL über HTTP
- Treffer — Die Gesamtzahl der vom Dienst erhaltenen Treffer
- Reaktionszeit des Service — Die durchschnittliche Reaktionszeit, die vom Service in Anspruch genommen wurde. (Reaktionszeit = Client-RTT+ letztes Byte anfordern - erstes Byte anfordern)
- Errors — Die Gesamtzahl der Fehler wie 4xx, 5xx usw.
- Datenvolumen — Das Gesamtvolumen der vom Dienst verarbeiteten Daten
- Namespace — Der Namensraum des Service
- Clustername — Der Clustername, in dem der Dienst gehostet wird
- SSL-Serverfehler — Die gesamten SSL-Fehler vom Dienst
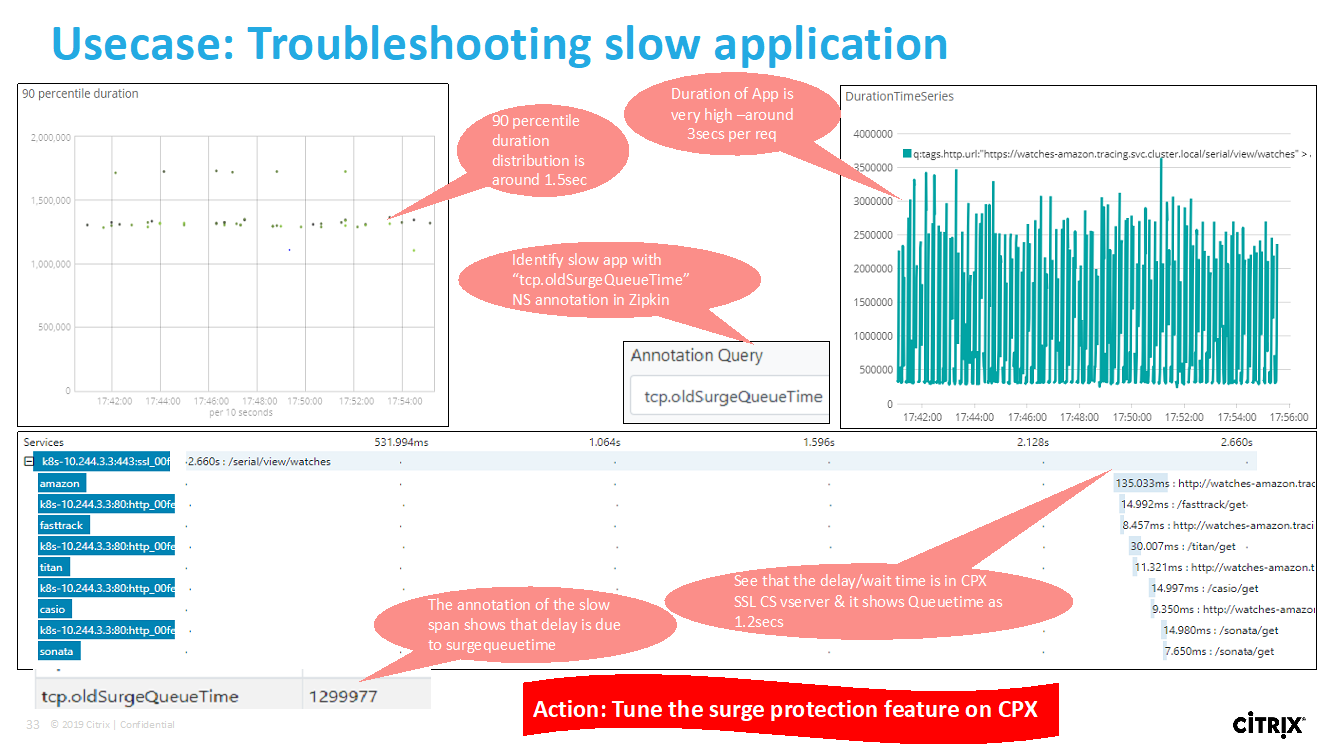
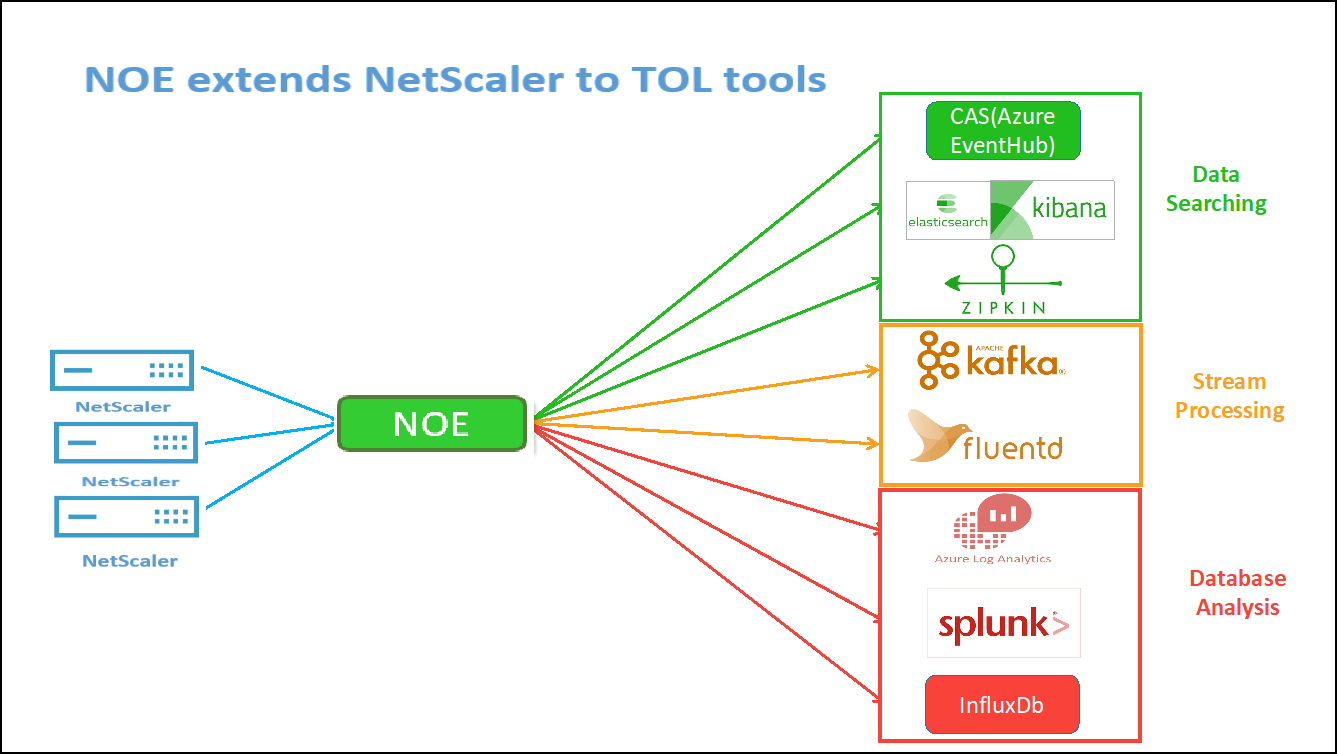
Diese spezifischen Zähler und Transaktionsprotokolle können über den NetScaler Observability Exporter (COE) mithilfe einer Reihe unterstützter Endpunkte extrahiert werden. Weitere Informationen zu COE finden Sie in den folgenden Abschnitten.
Exporteur für NetScaler-Statistiken
Dies ist ein einfacher Server, der NetScaler-Statistiken kratzt und sie über HTTP nach Prometheus exportiert. Prometheus kann dann als Datenquelle zu Grafana hinzugefügt werden, um die NetScaler-Statistiken grafisch anzuzeigen.
Um die Statistiken und Zähler von NetScaler-Instanzen zu überwachen, citrix-adc-metric-exporter kann als Container oder Skript ausgeführt werden. Das Exportprogramm sammelt NetScaler-Statistiken wie die Gesamtzahl der Treffer auf einen virtuellen Server, die HTTP-Anforderungsrate, die SSL-Verschlüsselungs-Entschlüsselungsrate usw. von den NetScaler-Instanzen und hält sie so lange, bis der Prometheus-Server die Statistiken abruft und sie mit einem Zeitstempel speichert. Grafana kann dann auf den Prometheus-Server verwiesen werden, um die Statistiken abzurufen, sie zu zeichnen, Alarme einzustellen, Heatmaps zu erstellen, Tabellen zu generieren usw. nach Bedarf, um die NetScaler-Statistiken zu analysieren.
Einzelheiten zum Einrichten des Exportprogramms für die Arbeit in einer Umgebung, wie in der Abbildung dargestellt, finden Sie in den folgenden Abschnitten. Ein Hinweis, auf welchen NetScaler-Entitäten/Metriken der Exporteur standardmäßig kratzt und wie er geändert werden kann, wird ebenfalls erläutert.
Weitere Informationen zu Exporter for NetScaler finden Sie im Metrics Exporter GitHub.
ADM-Dienst verteilte Ablaufverfolgung
Im Service-Diagramm können Sie die Ansicht für die verteilte Ablaufverfolgung verwenden, um:
- Analysieren Sie die gesamte Leistung des Dienstes.
- Visualisieren Sie den Kommunikationsfluss zwischen dem ausgewählten Dienst und seinen voneinander abhängigen Diensten.
- Identifizieren Sie, welcher Dienst auf Fehler hinweist, und beheben Sie den fehlerhaften Dienst
- Zeigen Sie Transaktionsdetails zwischen dem ausgewählten Dienst und jedem voneinander abhängigen Dienst an.
Voraussetzungen für die verteilte ADM-Ablaufverfolgung
Um die Trace-Informationen für den Dienst anzuzeigen, müssen Sie:
- Stellen Sie sicher, dass eine Anwendung die folgenden Trace-Header verwaltet, während sie Ost-West-Verkehr sendet:

- Aktualisieren Sie die CPX-YAML-Datei mit NS_DISTRIBUTED_TRACING und den Wert auf YES. Informationen zu den ersten Schritten finden Sie unter Verteilte Ablaufverfolgung.
Parsen des NetScaler Observability Exporter (COE)
NetScaler Observability Exporter ist ein Container, der Metriken und Transaktionen von NetScalern sammelt und sie in geeignete Formate (wie JSON, AVRO) für unterstützte Endgeräte umwandelt. Sie können die vom NetScaler Observability Exporter gesammelten Daten auf den gewünschten Endpunkt exportieren. Durch die Analyse der an den Endpunkt exportierten Daten können Sie wertvolle Erkenntnisse auf Microservices-Ebene für Anwendungen gewinnen, die von NetScalern als Proxy bereitgestellt werden.
Weitere Informationen zu COE finden Sie im COE GitHub.
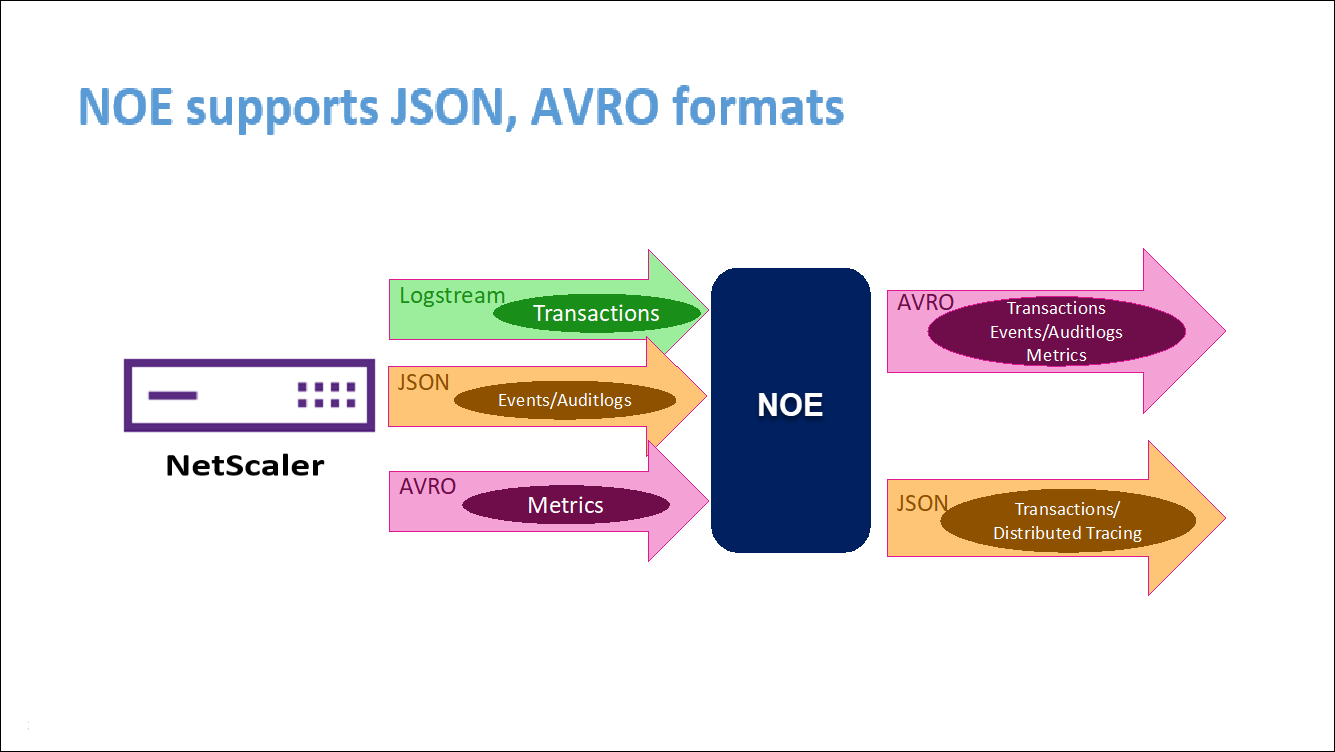
COE mit Elasticsearch als Transaktionsendpunkt

Wenn Elasticsearch als Transaktionsendpunkt angegeben ist, konvertiert NetScaler Observability Exporter die Daten in das JSON-Format. Auf dem Elasticsearch-Server erstellt NetScaler Observability Exporter stündlich Elasticsearch-Indizes für jeden ADC. Diese Indizes basieren auf Daten, Stunde, UUID des ADC und dem Typ der HTTP-Daten (http_event oder http_error). Anschließend lädt der NetScaler Observability Exporter die Daten im JSON-Format unter Elastic-Suchindizes für jeden ADC hoch. Alle regulären Transaktionen werden in den http_event-Index aufgenommen und alle Anomalien werden in den http_error-Index aufgenommen.
Unterstützung für verteilte Ablaufverfolgung mit Zipkin
In einer Microservice-Architektur kann sich eine einzelne Endbenutzeranfrage über mehrere Microservices erstrecken, was die Verfolgung einer Transaktion und das Beheben von Fehlerquellen schwierig macht. In solchen Fällen können herkömmliche Methoden der Leistungsüberwachung nicht genau bestimmen, wo Fehler auftreten und was der Grund für eine schlechte Leistung ist. Sie müssen Datenpunkte erfassen, die für jeden Microservice spezifisch sind, der eine Anfrage bearbeitet, und diese analysieren, um aussagekräftige Erkenntnisse zu erhalten.
Das verteilte Tracing begegnet dieser Herausforderung, indem es eine Möglichkeit bietet, eine Transaktion durchgängig zu verfolgen und zu verstehen, wie sie über mehrere Microservices hinweg gehandhabt wird.
OpenTracing ist eine Spezifikation und ein Standardsatz von APIs für den Entwurf und die Implementierung von verteiltem Tracing. Verteilte Tracer ermöglichen es Ihnen, den Datenfluss zwischen Ihren Microservices zu visualisieren und helfen, Engpässe in Ihrer Microservices-Architektur zu identifizieren.
NetScaler Observability Exporter implementiert die verteilte Ablaufverfolgung für NetScaler und unterstützt derzeit Zipkin als verteilten Tracer.
Derzeit können Sie die Leistung auf Anwendungsebene mit NetScaler überwachen. Mit NetScaler Observability Exporter mit NetScaler können Sie Protokollierungsdaten für Microservices jeder Anwendung abrufen, die von Ihrem NetScaler CPX, MPX oder VPX als Proxy bereitgestellt werden.
Um loszulegen, lesen Sie den GitHub Observability Exporter.
Zipkin für das Debugging von Anwendungen
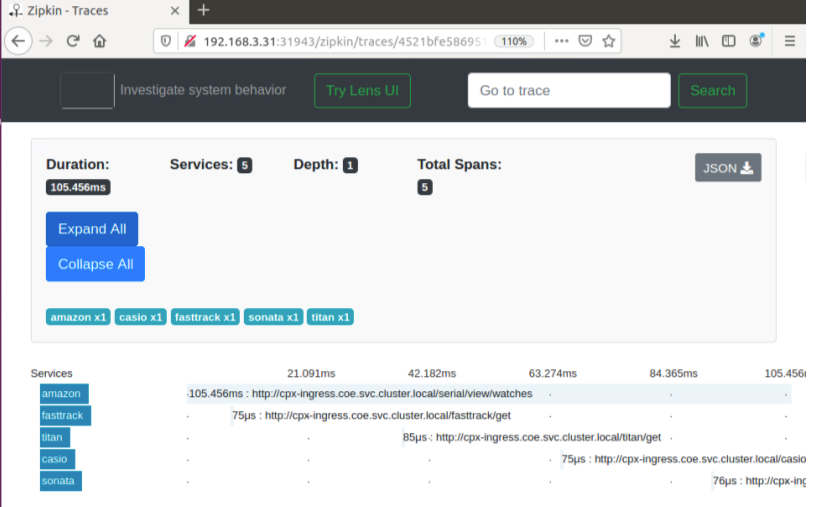
Zipkin ist ein verteiltes Open Source-Verfolgungssystem, das auf Dappers Papier von Googlebasiert. Dapper ist Googles System für die systemverteilte Rückverfolgung in der Produktion. Google erklärt dies in seinem Artikel: “Wir haben Dapper entwickelt, um den Entwicklern von Google mehr Informationen über das Verhalten komplexer verteilter Systeme zu liefern”. Die Beobachtung des Systems aus verschiedenen Blickwinkeln ist bei der Fehlersuche von entscheidender Bedeutung, insbesondere wenn ein System komplex und verteilt ist.
Die folgenden Zipkin-Verfolgungsdaten identifizieren insgesamt 5 Bereiche und 5 Dienste im Zusammenhang mit der Watches-Beispielanwendung. Die Trace-Daten zeigen die spezifischen Span-Daten über die 5 Microservices hinweg.
Um loszulegen, siehe Zipkin.
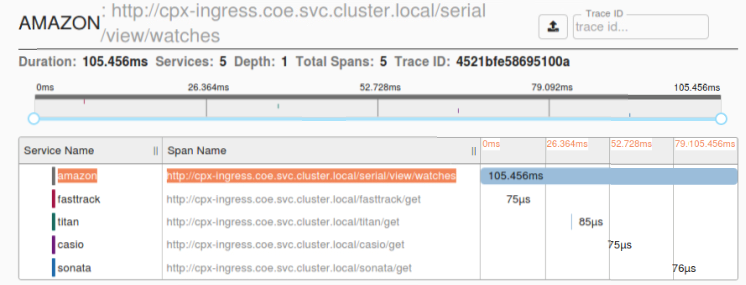
Beispiel für einen Zipkin-Zeitraum, der die Anwendungslatenz für die erste Anforderung zum Laden
Kibana zum Anzeigen von Daten
Kibana ist eine offene Benutzeroberfläche, mit der Sie Ihre Elasticsearch-Daten visualisieren und im Elastic Stack navigieren können. Erledigen Sie alles, von der Verfolgung der Abfrageladung bis hin zum Verständnis des Ablaufs von Anfragen
Egal, ob Sie Analyst oder Administrator sind, Kibana macht Ihre Daten umsetzbar, indem es die folgenden drei Schlüsselfunktionen bereitstellt:
- Eine Open Source Analyse- und Visualisierungsplattform. Erkunden Sie mit Kibana Ihre Elasticsearch-Daten und erstellen Sie anschließend wunderschöne Visualisierungen und Dashboards.
- Eine Benutzeroberfläche für die Verwaltung des Elastic Stack. Verwalten Sie Ihre Sicherheitseinstellungen, weisen Sie Benutzerrollen zu, erstellen Sie Snapshots, rollen Sie Ihre Daten zusammen und vieles mehr — alles bequem über eine Kibana-Benutzeroberfläche.
- Ein zentraler Knotenpunkt für die Lösungen von Elastic. Von der Protokollanalyse über die Dokumentenerkennung bis hin zum SIEM ist Kibana das Portal für den Zugriff auf diese und andere Funktionen.
Kibana wurde entwickelt, um Elasticsearch als Datenquelle zu verwenden. Stellen Sie sich Elasticsearch als die Engine vor, die die Daten speichert und verarbeitet, wobei Kibana an der Spitze sitzt.
Auf der Homepage bietet Kibana die folgenden Optionen zum Hinzufügen von Daten:
- Importieren Sie Daten mit dem Dateidaten-Visualizer.
- Richten Sie mithilfe unserer integrierten Tutorials einen Datenfluss zu Elasticsearch ein. Wenn es für deine Daten kein Tutorial gibt, gehe zur Beats Übersicht, um mehr über andere Datenversender in der Beats-Familie zu erfahren.
- Fügen Sie einen Beispieldatensatz hinzu und testen Sie Kibana, ohne selbst Daten zu laden.
- Indizieren Sie Ihre Daten mit REST-APIs oder Clientbibliothekenin Elasticsearch.
Kibana verwendet ein Indexmuster, um anzugeben, welche Elasticsearch-Indizes untersucht werden sollen. Wenn Sie eine Datei hochladen, ein integriertes Tutorial ausführen oder Beispieldaten hinzufügen, erhalten Sie ein kostenloses Indexmuster und können mit der Erkundung beginnen. Wenn Sie Ihre eigenen Daten laden, können Sie in Stack Managementein Indexmuster erstellen.
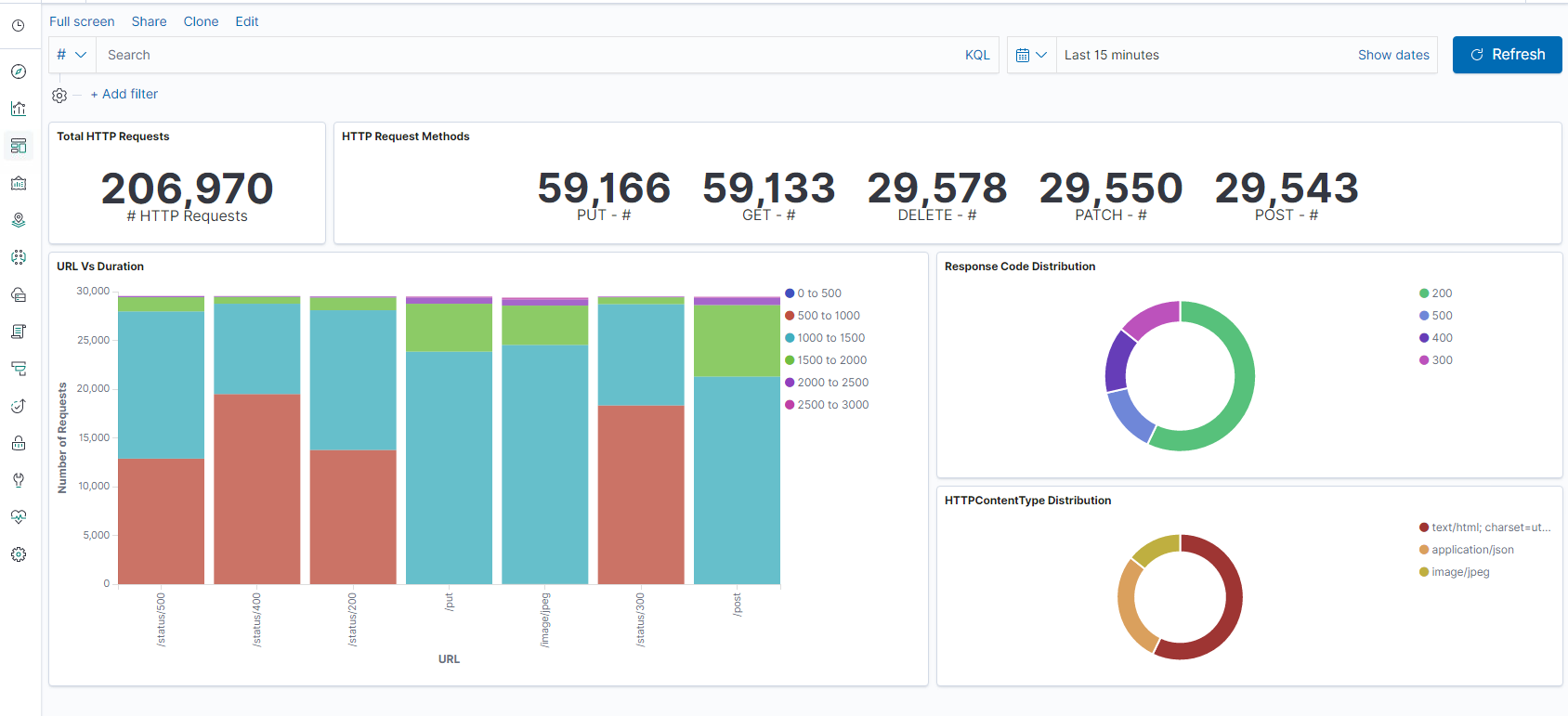
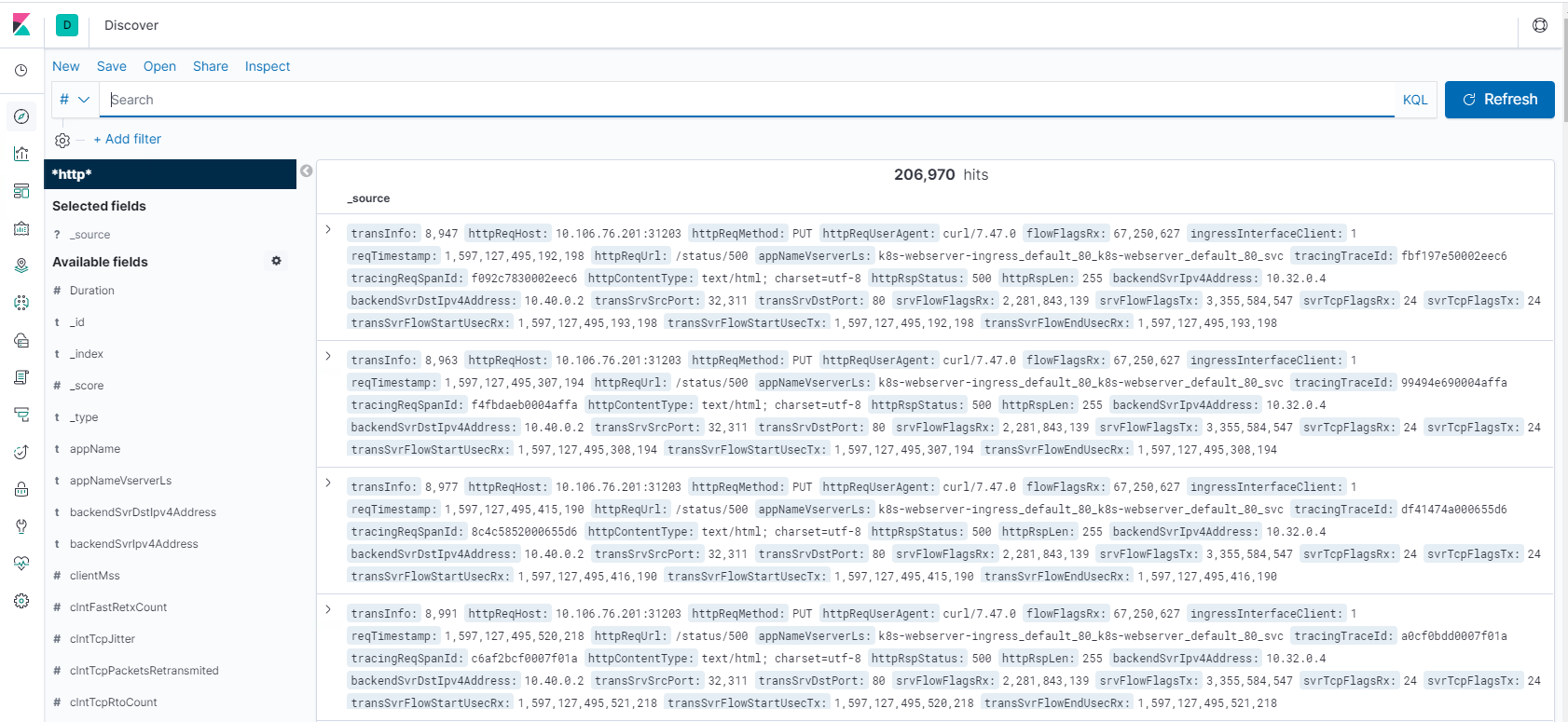
Schritt 1: Index-Pattern für Logstash konfigurieren
Schritt 2: Wählen Sie den Index aus und generieren Sie den zu füllenden Datenverkehr.
Schritt 3: Generieren Sie eine Anwendung aus den unstrukturierten Daten aus Protokoll-Feeds.
Schritt 4: Kibana formatiert die Logstash-Eingabe, um Berichte und Dashboards zu erstellen.
- Zeitbereich
- Tabellarische Ansicht
- Trefferzahlen basierend auf der Anwendung.
- Zeit-IP, Agent, Maschine.OS, Antwortcode (200), URL
- Filtern nach Werten
Schritt 5: Visualisieren Sie die Daten in einem Aggregationsbericht.
- Ergebnisaggregation in einem Diagrammbericht (Torte, Grafik usw.)
Teilen
Teilen
In diesem Artikel
- Übersicht
- Überblick über Anwendungsleistung und Latenz
- NetScaler Application Delivery Management SSL-Dashboard
- Integrationen von Drittanbietern
- Lastenausgleich für eingehenden Datenverkehr zu TCP- oder UDP-basierten Anwendungen
- Überwachen und verbessern Sie die Leistung Ihrer TCP- oder UDP-basierten Anwendungen
- NetScaler Application Delivery Management (ADM) -Dienst
- Fehlerbehebung für NetScaler-Teams
- Fehlerbehebung für SRE und Plattformteams
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.