Infrastruktur-Analysen
Ein zentrales Ziel für Netzwerkadministratoren ist die Überwachung von NetScaler-Instanzen. NetScaler-Instanzen bieten interessante Einblicke in die Nutzung und Leistung von Anwendungen und Desktops, auf die über sie zugegriffen wird. Administratoren müssen die NetScaler-Instanz überwachen und die Anwendungsflüsse analysieren, die von jeder NetScaler-Instanz verarbeitet werden. Sie können mögliche Probleme in Konfiguration, Einrichtung, Konnektivität, Zertifikaten und anderen Bereichen beheben, die die Anwendungsnutzung oder -leistung beeinträchtigen könnten. Eine plötzliche Änderung des Anwendungsverkehrsmusters kann beispielsweise auf eine Änderung der SSL-Konfiguration, wie die Deaktivierung eines SSL-Protokolls, zurückzuführen sein. Administratoren müssen in der Lage sein, die Korrelation zwischen diesen Datenpunkten schnell zu erkennen, um Folgendes sicherzustellen:
-
Die Anwendungsverfügbarkeit befindet sich in einem optimalen Zustand
-
Es gibt keine Probleme mit Ressourcenverbrauch, Hardware, Kapazität oder Konfigurationsänderungen
-
Es gibt keine ungenutzten Bestände
-
Es gibt keine abgelaufenen Zertifikate
Die Funktion “Infrastruktur-Analysen” vereinfacht den Prozess der Datenanalyse, indem sie mehrere Datenquellen korreliert und zu einem messbaren Score quantifiziert, der den Zustand einer Instanz definiert. Mit dieser Funktion erhalten Administratoren einen zentralen Anlaufpunkt, um zu verstehen, ob ein Problem vorliegt, woher das Problem stammt und welche möglichen Abhilfemaßnahmen sie ergreifen können.
Infrastruktur-Analysen
Die NetScaler Console-Funktion “Infrastruktur-Analysen” sammelt alle von den NetScaler-Instanzen erfassten Daten und quantifiziert sie in einem Instanz-Score, der den Zustand der Instanzen definiert. Der Instanz-Score wird in einer Tabellenansicht oder als Circle-Pack-Visualisierung zusammengefasst. Die Funktion “Infrastruktur-Analysen” hilft Ihnen, die Faktoren zu visualisieren, die zu einem Problem auf den Instanzen geführt haben oder führen könnten. Diese Visualisierung hilft Ihnen auch, die Maßnahmen zu bestimmen, die ergriffen werden müssen, um das Problem und sein Wiederauftreten zu verhindern.
Instanz-Score
Der Instanz-Score gibt den Zustand einer NetScaler-Instanz an. Ein Score von 100 bedeutet eine perfekt funktionierende Instanz ohne Probleme. Der Instanz-Score erfasst verschiedene Ebenen potenzieller Probleme auf der Instanz. Er ist eine quantifizierbare Messung des Instanzzustands, und mehrere “Gesundheitsindikatoren” tragen zu diesem Score bei.
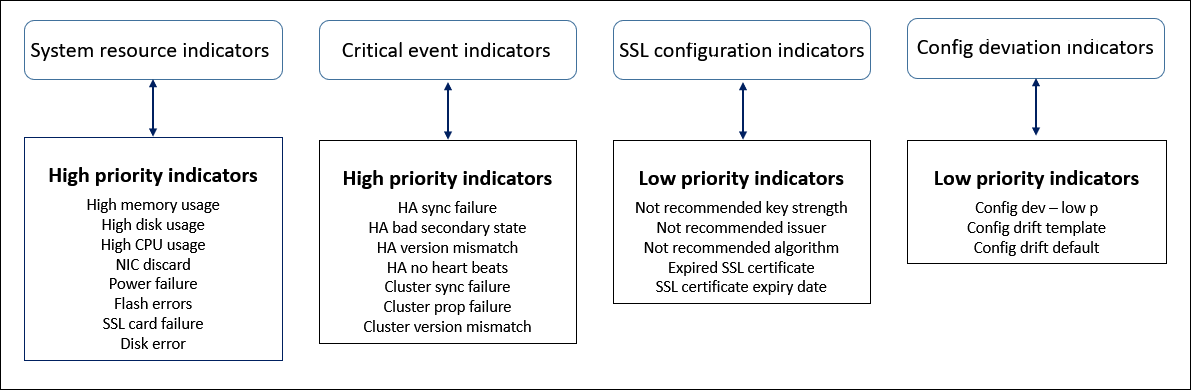
Gesundheitsindikatoren sind die Bausteine des Instanz-Scores, wobei der Score periodisch für einen vordefinierten “Überwachungszeitraum” berechnet wird, basierend auf allen in diesem Zeitfenster erkannten Indikatoren. Derzeit berechnet die Infrastruktur-Analyse den Instanz-Score einmal pro Stunde basierend auf den von den Instanzen gesammelten Daten. Ein Indikator kann als jede Aktivität (ein Ereignis oder ein Problem) definiert werden, die zu einer der folgenden Kategorien auf den Instanzen gehört.
-
Systemressourcen-Indikatoren
-
Indikatoren für kritische Ereignisse
-
SSL-Konfigurations-Indikatoren
-
Konfigurationsabweichungs-Indikatoren
Gesundheitsindikatoren
-
Systemressourcen-Indikatoren
Die folgenden kritischen Systemressourcenprobleme können auf NetScaler-Instanzen auftreten und werden von NetScaler Console überwacht.
-
Hohe CPU-Auslastung. Die CPU-Auslastung hat den oberen Schwellenwert in der NetScaler-Instanz überschritten.
-
Hohe Speicherauslastung. Die Speicherauslastung hat den oberen Schwellenwert in der NetScaler-Instanz überschritten.
-
Hohe Festplattenauslastung. Die Festplattenauslastung hat den oberen Schwellenwert in der NetScaler-Instanz überschritten.
-
Festplattenfehler. Es gibt Fehler auf Festplatte 0 oder Festplatte 1 auf dem Hypervisor, auf dem die NetScaler-Instanz installiert ist.
-
Stromausfall. Die Stromversorgung ist ausgefallen oder von der NetScaler-Instanz getrennt.
-
SSL-Kartenfehler. Die auf der Instanz installierte SSL-Karte ist ausgefallen.
-
Flash-Fehler. Auf der NetScaler-Instanz wurden Compact-Flash-Fehler festgestellt.
-
NIC-Verluste. Die von der NIC-Karte verworfenen Pakete haben den oberen Schwellenwert in der NetScaler-Instanz überschritten.
-
Weitere Informationen zu diesen Systemressourcenfehlern finden Sie unter Das Instanz-Dashboard.
-
Indikatoren für kritische Ereignisse
Die folgenden kritischen Ereignisse werden durch die Ereignisse unter der Ereignisverwaltungsfunktion von NetScaler Console identifiziert, die mit kritischer Schwere konfiguriert sind.
-
HA-Synchronisierungsfehler. Die Konfigurationssynchronisierung zwischen den NetScaler-Instanzen in Hochverfügbarkeit ist auf dem sekundären Server fehlgeschlagen.
-
HA keine Heartbeats. Der primäre Server in einem Paar von NetScaler-Instanzen in Hochverfügbarkeit empfängt keine Heartbeats vom sekundären Server.
-
HA schlechter sekundärer Zustand. Der sekundäre Server in einem Paar von NetScaler-Instanzen in Hochverfügbarkeit befindet sich im Zustand “Down”, “Unknown” oder “Stay secondary”.
-
HA-Versionskonflikt. Die Version der NetScaler-Software-Images, die auf einem Paar von NetScaler-Instanzen in Hochverfügbarkeit installiert sind, stimmt nicht überein.
-
Cluster-Synchronisierungsfehler. Die Konfigurationssynchronisierung zwischen den NetScaler-Instanzen im Cluster-Modus ist fehlgeschlagen.
-
Cluster-Versionskonflikt. Die Version der NetScaler-Software-Images, die auf den NetScaler-Instanzen im Cluster-Modus installiert sind, stimmt nicht überein.
-
Cluster-Propagierungsfehler. Die Propagierung von Konfigurationen auf alle Instanzen in einem Cluster ist fehlgeschlagen.
Hinweis
Sie können Ihre Liste kritischer SNMP-Ereignisse erstellen, indem Sie die Schweregrade der Ereignisse ändern. Weitere Informationen zum Ändern der Schweregrade finden Sie unter Meldeschwere von Ereignissen, die auf NetScaler-Instanzen auftreten, ändern.
Weitere Informationen zu Ereignissen in NetScaler Console finden Sie unter Ereignisse.
-
-
SSL-Konfigurations-Indikatoren
-
Nicht empfohlene Schlüsselstärke. Die Schlüsselstärke der SSL-Zertifikate entspricht nicht den NetScaler®-Standards.
-
Nicht empfohlener Aussteller. Der Aussteller des SSL-Zertifikats wird von Citrix nicht empfohlen.
-
SSL-Zertifikate abgelaufen. Das in der NetScaler-Instanz installierte SSL-Zertifikat ist abgelaufen.
-
SSL-Zertifikate laufen bald ab. Das in der NetScaler-Instanz installierte SSL-Zertifikat läuft in der nächsten Woche ab.
-
Nicht empfohlene Algorithmen. Die Signaturalgorithmen der in der NetScaler-Instanz installierten SSL-Zertifikate entsprechen nicht den NetScaler-Standards.
-
Weitere Informationen zu SSL-Zertifikaten finden Sie unter SSL-Dashboard.
-
Konfigurationsabweichungs-Indikatoren
-
Konfigurationsabweichungsvorlage. Es gibt eine Abweichung (ungespeicherte Änderungen) in der Konfiguration von den Audit-Vorlagen, die Sie mit spezifischen Konfigurationen erstellt haben, die Sie auf bestimmten Instanzen prüfen möchten.
-
Konfigurationsabweichung Standard. Es gibt eine Abweichung (ungespeicherte Änderungen) in der Konfiguration von den Standardkonfigurationsdateien.
-
Weitere Informationen zu Konfigurationsabweichungen und zum Ausführen von Audit-Berichten zur Überprüfung von Konfigurationsabweichungen finden Sie unter Audit-Berichte anzeigen.
NetScaler-Kapazitätsprobleme anzeigen
Wenn eine NetScaler-Instanz den Großteil ihrer verfügbaren Kapazität verbraucht hat, kann es beim Verarbeiten des Client-Datenverkehrs zu Paketverlusten kommen. Dieses Problem führt zu einer geringen Leistung in einer NetScaler-Instanz. Durch das Verständnis solcher NetScaler-Kapazitätsprobleme können Sie proaktiv zusätzliche Lizenzen zuweisen, um die NetScaler-Leistung zu stabilisieren.
So zeigen Sie NetScaler-Kapazitätsprobleme an:
- Navigieren Sie zu Infrastructure > Infrastructure Analytics.
- Erweitern Sie die Instanz, für die Sie Kapazitätsprobleme anzeigen möchten.
Die NetScaler Console fragt diese Ereignisse alle fünf Minuten von der NetScaler-Instanz ab und zeigt die Paketverluste oder die Erhöhungen des Ratenbegrenzungszählers an, falls vorhanden. Die Probleme werden nach den folgenden Kapazitätsparametern kategorisiert:
- Durchsatzlimit erreicht – Die Anzahl der Pakete, die in der Instanz verworfen wurden, nachdem das Durchsatzlimit erreicht wurde.
- PE CPU-Limit erreicht – Die Anzahl der Pakete, die auf allen NICs verworfen wurden, nachdem das PE CPU-Limit erreicht wurde.
- PPS-Limit erreicht – Die Anzahl der Pakete, die in der Instanz verworfen wurden, nachdem das PPS-Limit erreicht wurde.
- SSL-Durchsatzratenlimit – Die Häufigkeit, mit der das SSL-Durchsatzlimit erreicht wurde.
- SSL-TPS-Ratenlimit – Die Häufigkeit, mit der das SSL-TPS-Limit erreicht wurde.
Die NetScaler Console berechnet den Instanz-Score anhand des definierten Kapazitätsschwellenwerts.
-
Niedriger Schwellenwert – 1 Paketverlust oder Erhöhung des Ratenbegrenzungszählers
-
Hoher Schwellenwert – 10000 Paketverluste oder Erhöhungen des Ratenbegrenzungszählers
Wenn eine NetScaler-Instanz den Kapazitätsschwellenwert überschreitet, wird der Instanz-Score beeinträchtigt.
Wenn Pakete verworfen werden oder der Ratenbegrenzungszähler erhöht wird, wird ein Ereignis unter der Kategorie NetScalerCapacityBreach generiert. Um diese Ereignisse anzuzeigen, navigieren Sie zu Accounts > System Events.
Wert der Gesundheitsindikatoren
Die Indikatoren werden basierend auf ihren Werten wie folgt in Indikatoren mit hoher Priorität und Indikatoren mit niedriger Priorität eingeteilt:
Die Gesundheitsindikatoren innerhalb derselben Indikatorengruppe haben unterschiedliche Gewichtungen. Ein Indikator kann stärker zu einem niedrigeren Instanz-Score beitragen als ein anderer Indikator. Zum Beispiel senkt eine hohe Speicherauslastung den Instanz-Score stärker als eine hohe Festplattenauslastung, eine hohe CPU-Auslastung und NIC-Verluste. Wenn auf einer Instanz eine größere Anzahl von Indikatoren erkannt wird, ist der Instanz-Score geringer.
Der Wert eines Indikators wird basierend auf den folgenden Regeln berechnet. Der Indikator gilt als auf eine der folgenden drei Arten erkannt:
-
Basierend auf einer Aktivität. Zum Beispiel wird ein Systemressourcen-Indikator ausgelöst, wenn ein Stromausfall auf der Instanz auftritt, und dieser Indikator reduziert den Wert des Instanz-Scores. Wenn der Indikator gelöscht wird, wird die Strafe aufgehoben, und der Instanz-Score steigt.
-
Basierend auf der Überschreitung des Schwellenwerts. Zum Beispiel wird ein Systemressourcen-Indikator ausgelöst, wenn die NIC-Karte Pakete verwirft und der Schwellenwert überschritten wird.
-
Basierend auf der Überschreitung des niedrigen und hohen Schwellenwerts. Hier kann ein Indikator auf zwei Arten ausgelöst werden:
-
Wenn der Wert des Indikators zwischen dem niedrigen und hohen Schwellenwert liegt, wird eine teilweise Strafe auf den Instanz-Score erhoben.
-
Wenn der Wert den hohen Schwellenwert überschreitet, wird eine volle Strafe auf den Instanz-Score erhoben.
-
Es wird keine Strafe auf den Instanz-Score erhoben, wenn der Wert unter einen niedrigen Schwellenwert fällt.
-
Zum Beispiel ist die CPU-Auslastung ein Systemressourcen-Indikator, der ausgelöst wird, wenn der Nutzungswert den niedrigen Schwellenwert und auch wenn der Wert den hohen Schwellenwert überschreitet.
Infrastruktur-Analysen-Dashboard
Navigieren Sie zu Infrastructure > Infrastructure Analytics.
Die Infrastruktur-Analysen können in einem Circle Pack-Format oder einem Tabellen-Format angezeigt werden. Sie können zwischen den beiden Formaten wechseln.
- In der Tabellenansicht können Sie nach einer Instanz suchen, indem Sie den Hostnamen oder die IP-Adresse in die Suchleiste eingeben.
- Standardmäßig zeigt die Seite “Infrastruktur-Analysen” das Übersichtsfenster auf der rechten Seite der Seite an.
- Klicken Sie auf das Einstellungen-Symbol, um das Einstellungen-Fenster anzuzeigen.
- In beiden Ansichtsformaten zeigt das Übersichtsfenster Details zu allen Instanzen in Ihrem Netzwerk an.
Circle-Pack-Ansicht
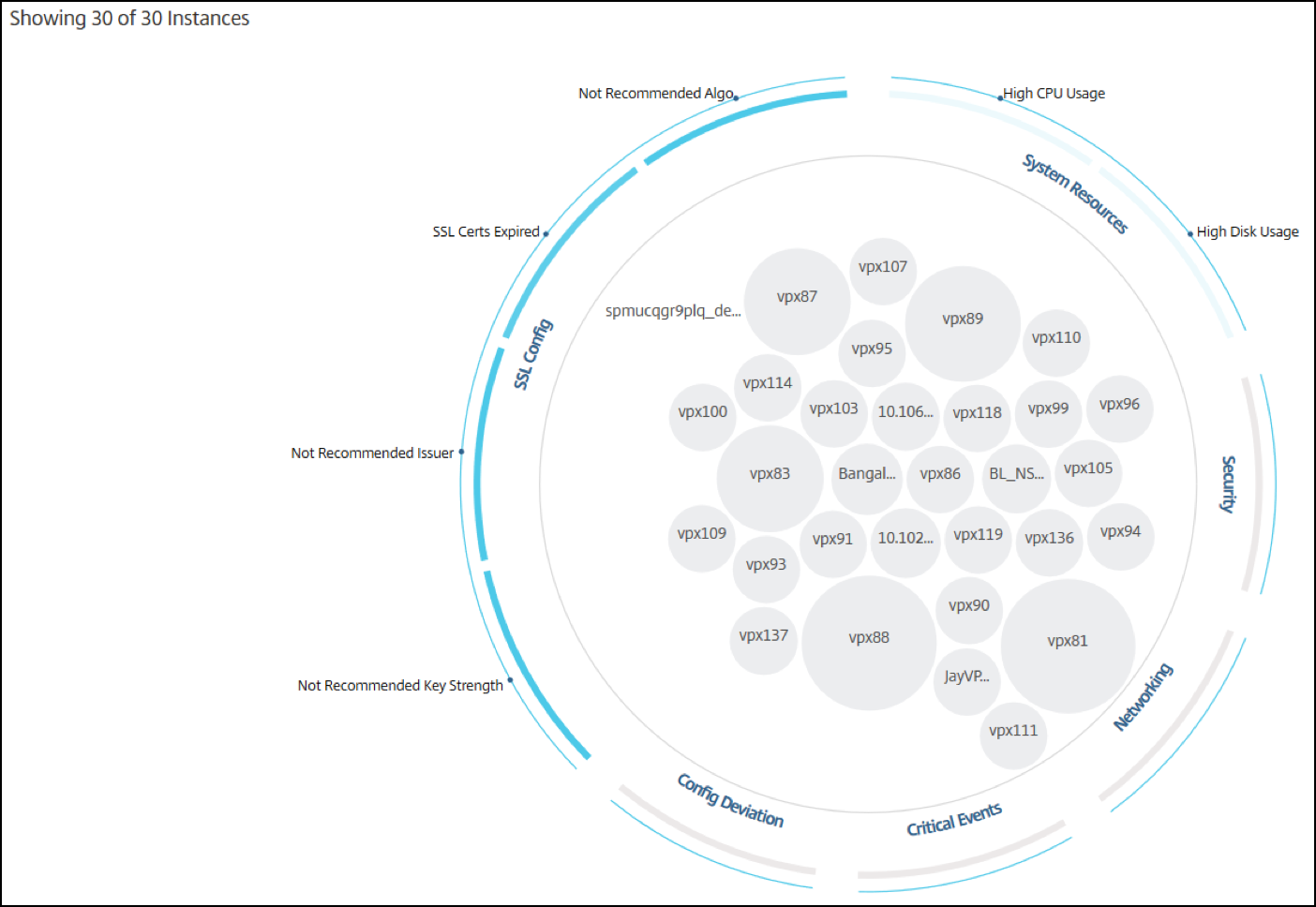
Circle-Packing-Diagramme zeigen Instanzgruppen als dicht organisierte Kreise. Sie zeigen oft Hierarchien, in denen kleinere Instanzgruppen entweder ähnlich wie andere in derselben Kategorie gefärbt oder in größere Gruppen verschachtelt sind. Circle Packs stellen hierarchische Datensätze dar und zeigen verschiedene Ebenen in der Hierarchie und wie sie miteinander interagieren.
Instanzkreise
Farbe. Jede Instanz wird im Circle Pack als farbiger Kreis dargestellt. Die Farbe des Kreises zeigt den Zustand dieser Instanz an.
- Grün – Instanz-Score liegt zwischen 100 und 80. Die Instanz ist fehlerfrei.
- Gelb – Instanz-Score liegt zwischen 80 und 50; es wurden einige Probleme festgestellt, die überprüft werden müssen.
- Rot – Instanz-Score liegt unter 50. Die Instanz befindet sich in einem kritischen Zustand, da auf dieser Instanz mehrere Probleme festgestellt wurden.
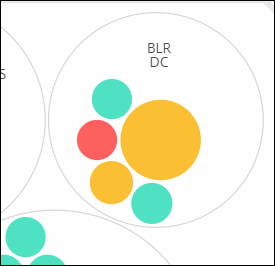
Größe. Die Größe dieser farbigen Kreise gibt die Anzahl der auf dieser Instanz konfigurierten virtuellen Server an. Ein größerer Kreis weist auf eine größere Anzahl virtueller Server hin.
Sie können den Mauszeiger über jeden der Instanzkreise (farbige Kreise) bewegen, um eine Zusammenfassung anzuzeigen. Der Hover-Tooltip zeigt den Hostnamen der Instanz, die Anzahl der aktiven virtuellen Server und die Anzahl der auf dieser Instanz konfigurierten Anwendungen an.
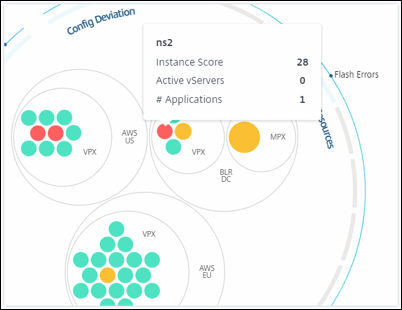
Gruppierte Instanzkreise
Das Circle Pack besteht zunächst aus Instanzkreisen, die basierend auf den folgenden Kriterien gruppiert, verschachtelt oder in einem anderen Kreis verpackt sind:
-
der Standort, an dem sie bereitgestellt werden
-
der Typ der bereitgestellten Instanzen – VPX, MPX, SDX und CPX
-
das virtuelle oder physische Modell der NetScaler-Instanz
-
die auf den Instanzen installierte NetScaler-Image-Version
Die folgende Abbildung zeigt ein Circle Pack, bei dem die Instanzen zuerst nach dem Standort oder Rechenzentrum, in dem sie bereitgestellt werden, gruppiert und dann weiter nach ihrem Typ, VPX und MPX, gruppiert werden.
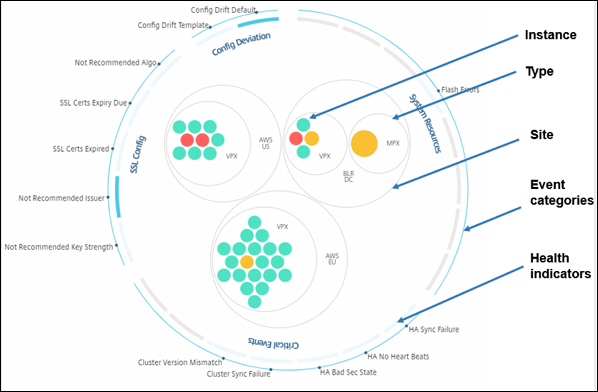
Alle diese verschachtelten Kreise sind von zwei äußersten Kreisen umgeben. Die beiden äußeren Kreise stellen die vier Kategorien von Ereignissen dar, die von der NetScaler Console überwacht werden (Systemressourcen, kritische Ereignisse, SSL-Konfiguration und Konfigurationsabweichung) und die beitragenden Gesundheitsindikatoren.
Geklusterte Instanzkreise
NetScaler Console überwacht viele Instanzen. Um die Überwachung und Wartung dieser Instanzen zu erleichtern, ermöglicht Ihnen Infrastructure Analytics, diese auf zwei Ebenen zu clustern. Das heißt, die Instanzgruppierungen können innerhalb einer anderen Gruppierung verschachtelt werden.
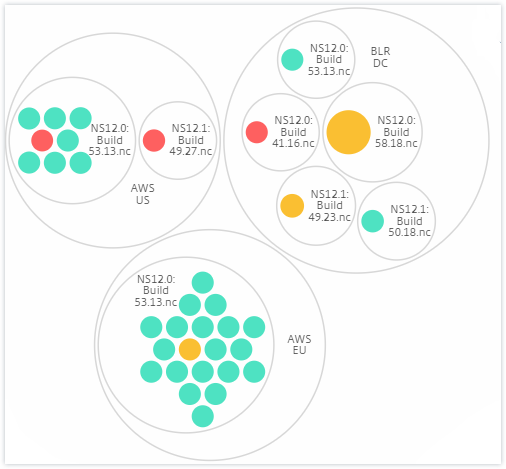
Zum Beispiel hat das BLR-Rechenzentrum zwei Arten von NetScaler-Instanzen – VPX und MPX – die dort bereitgestellt werden. Sie können die NetScaler-Instanzen zuerst nach ihrem Typ gruppieren und dann alle Instanzen nach dem Standort, an dem sie gruppiert sind, gruppieren. Sie können nun leicht erkennen, wie viele Arten von Instanzen an den von Ihnen verwalteten Standorten bereitgestellt werden.
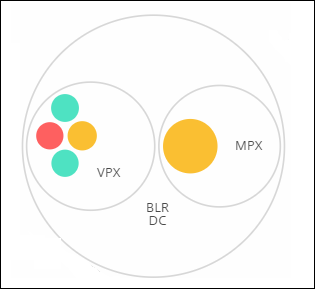
Einige weitere Beispiele für zweistufiges Clustering sind:
Standort und Modell:
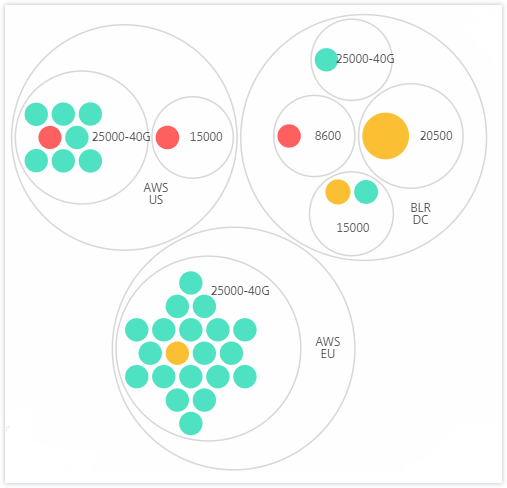
Typ und Version:
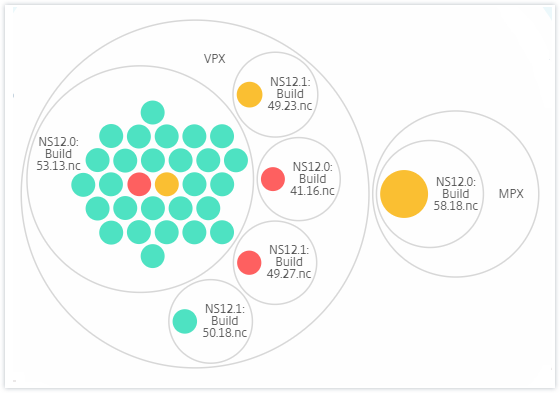
Standort und Version:
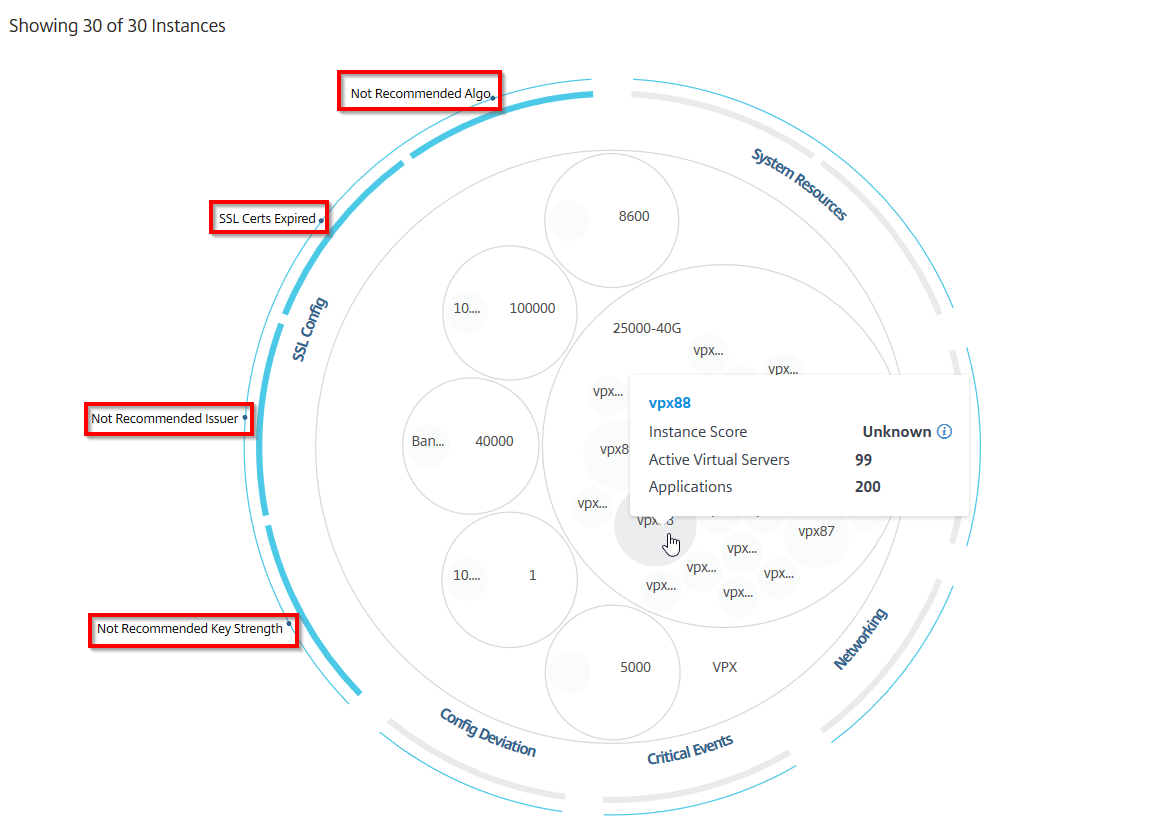
So verwenden Sie das Circle Pack
Klicken Sie auf jeden der farbigen Kreise, um diese Instanz hervorzuheben.
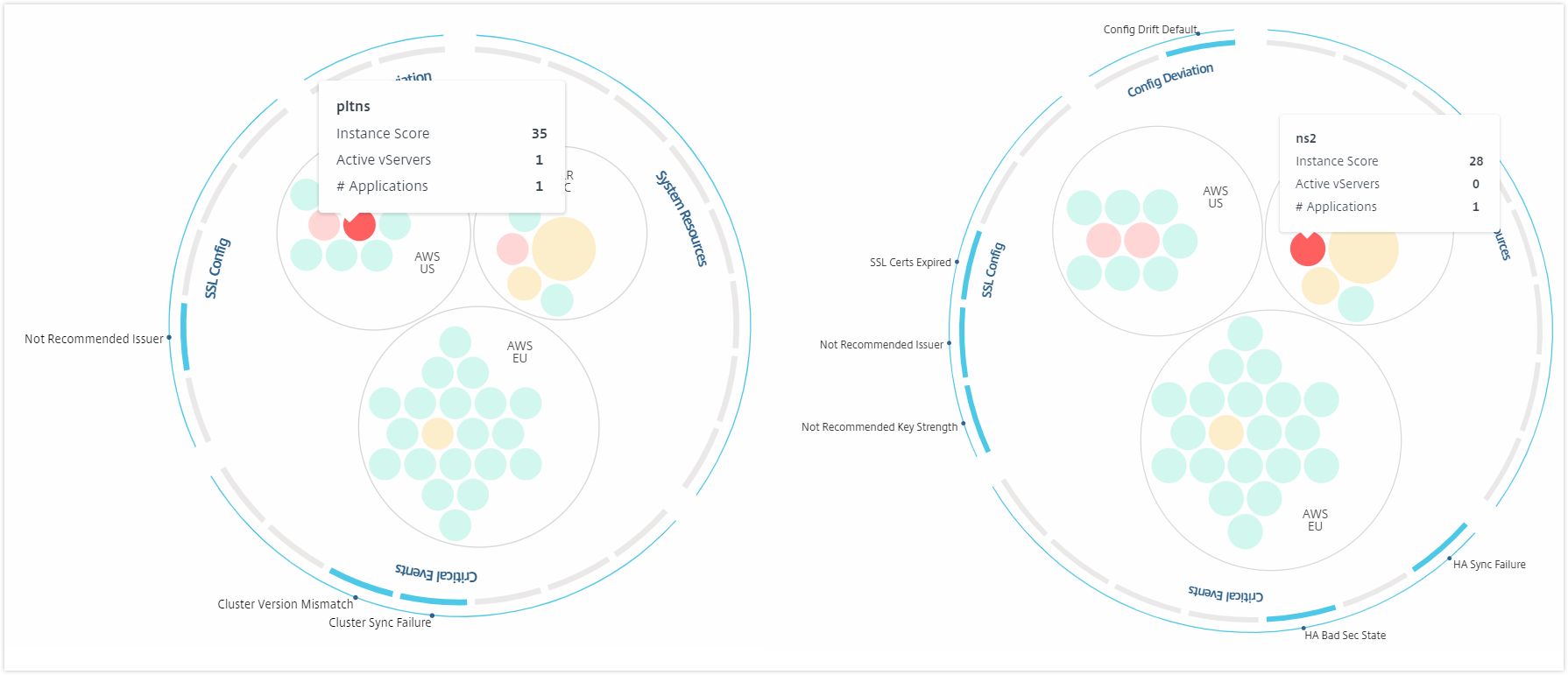
Abhängig von den Ereignissen, die in dieser Instanz aufgetreten sind, werden nur die entsprechenden Gesundheitsindikatoren auf den äußeren Kreisen hervorgehoben. Zum Beispiel zeigen die folgenden beiden Bilder des Circle Packs unterschiedliche Sätze von Risikoindikatoren, obwohl beide Instanzen sich in einem kritischen Zustand befinden.
Sie können auch auf die Gesundheitsindikatoren klicken, um weitere Details zur Anzahl der Instanzen zu erhalten, die diesen Risikoindikator gemeldet haben. Klicken Sie beispielsweise auf Not recommended Algo, um den Zusammenfassungsbericht dieses Risikoindikators anzuzeigen.
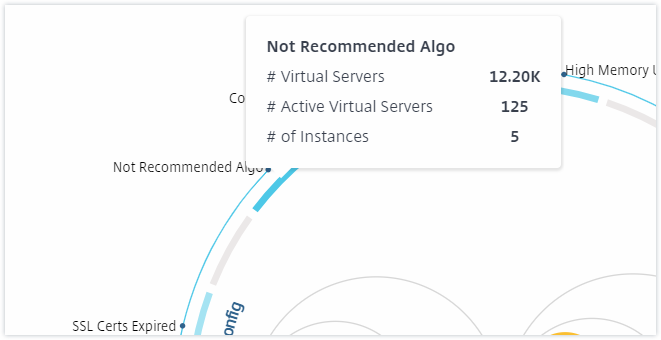
Tabellenansicht
Die Tabellenansicht zeigt die Instanzen und deren Details in einem Tabellenformat an. Die angezeigten Details sind wie folgt:
-
Hostname der Instanz
-
Die IP-Adresse der Instanz
-
Zustand der Instanz
-
Instanz-Score
-
Anzahl der auf dieser Instanz konfigurierten virtuellen Server
-
Anzahl der auf dieser Instanz konfigurierten Anwendungen
-
Gesamtzahl der Risikoindikatoren
-
Das Ereignis, das am stärksten zu einem niedrigeren Instanz-Score beiträgt
Die Instanzen, die sich im kritischen Zustand befinden, stehen am Anfang der Tabelle, gefolgt von den Instanzen, die überprüft werden müssen, und dann den gesünderen Instanzen.
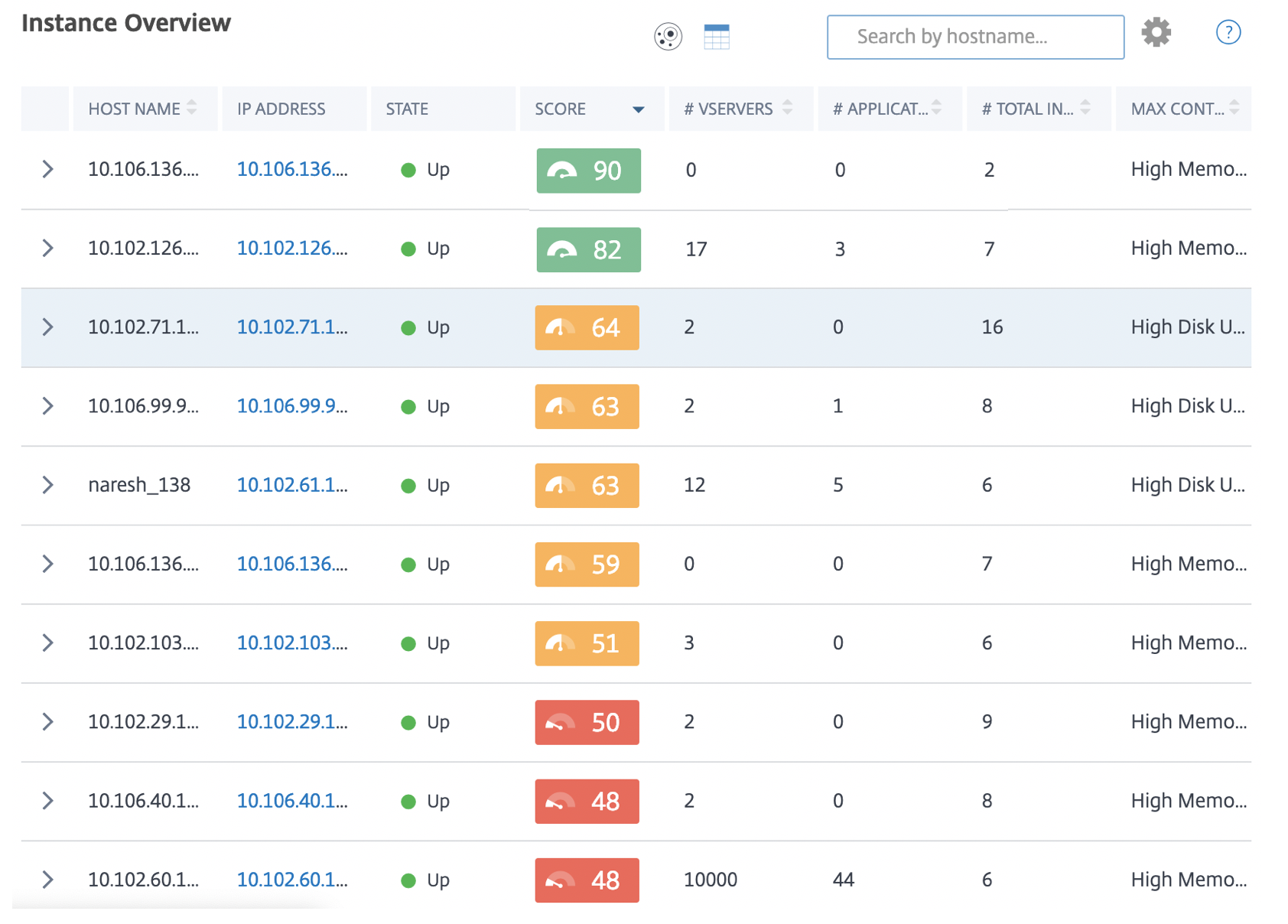
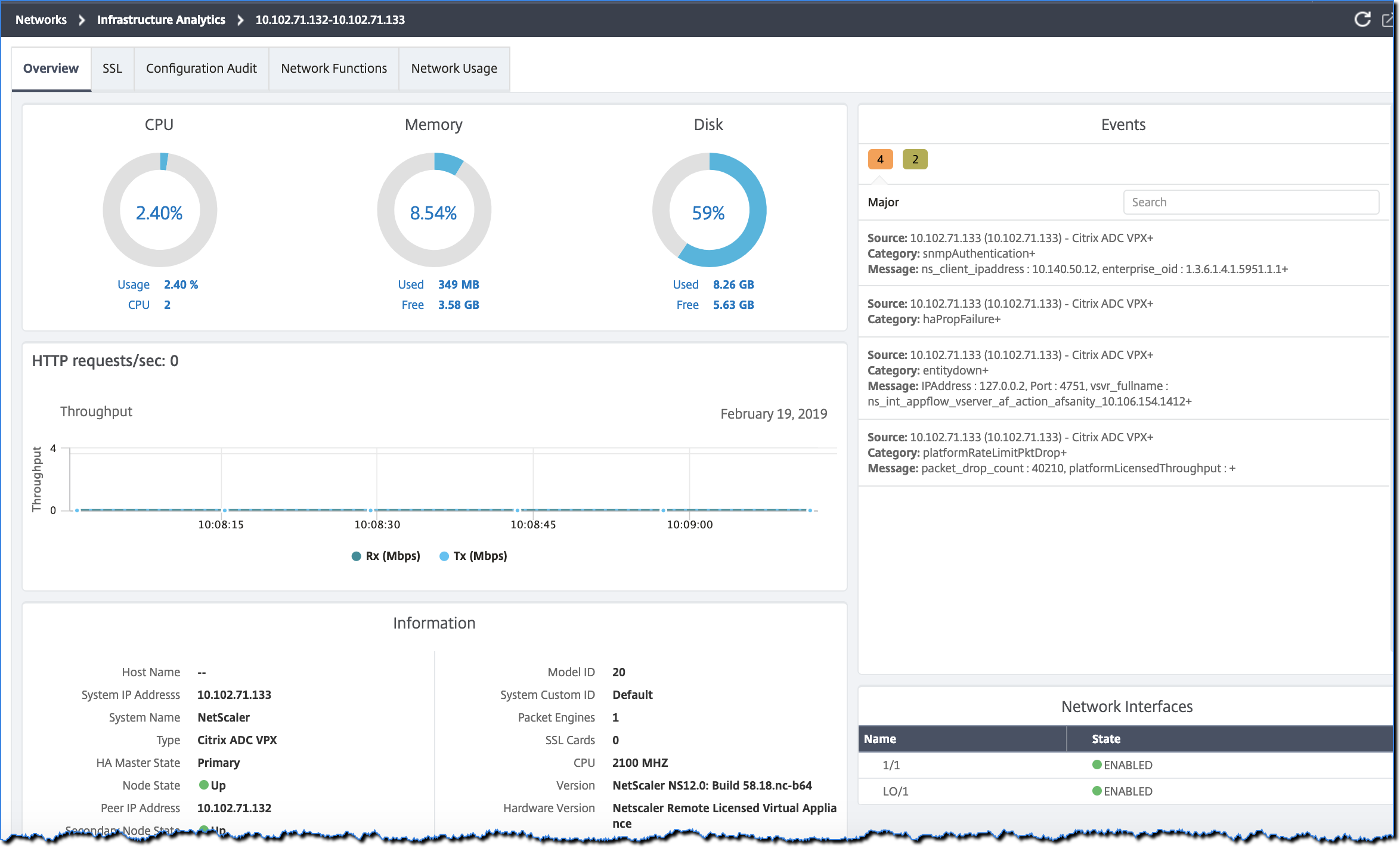
Klicken Sie in der Tabellenansicht auf die IP-Adresse der Instanz, um weitere Details dieser Instanz als Dashboard-Anzeige zu sehen. Das Instanz-Dashboard bietet einen Überblick über die Instanz, wo Sie die CPU-, Speicher- und Festplattenauslastung der Instanz sehen können. Sie können auch Details zur SSL-Zertifikatsverwaltung, Konfigurationsprüfung, Netzwerkfunktionen und einen Netzwerkbericht sehen, der die detaillierte Netzwerknutzung der Instanz zeigt. Scrollen Sie weiter nach unten, um die Liste der auf dieser Instanz aktivierten Funktionen und Modi zu sehen.
Sie können auch auf den Pfeil am Anfang jeder Zeile klicken, um die Zeile für weitere Details zu erweitern.
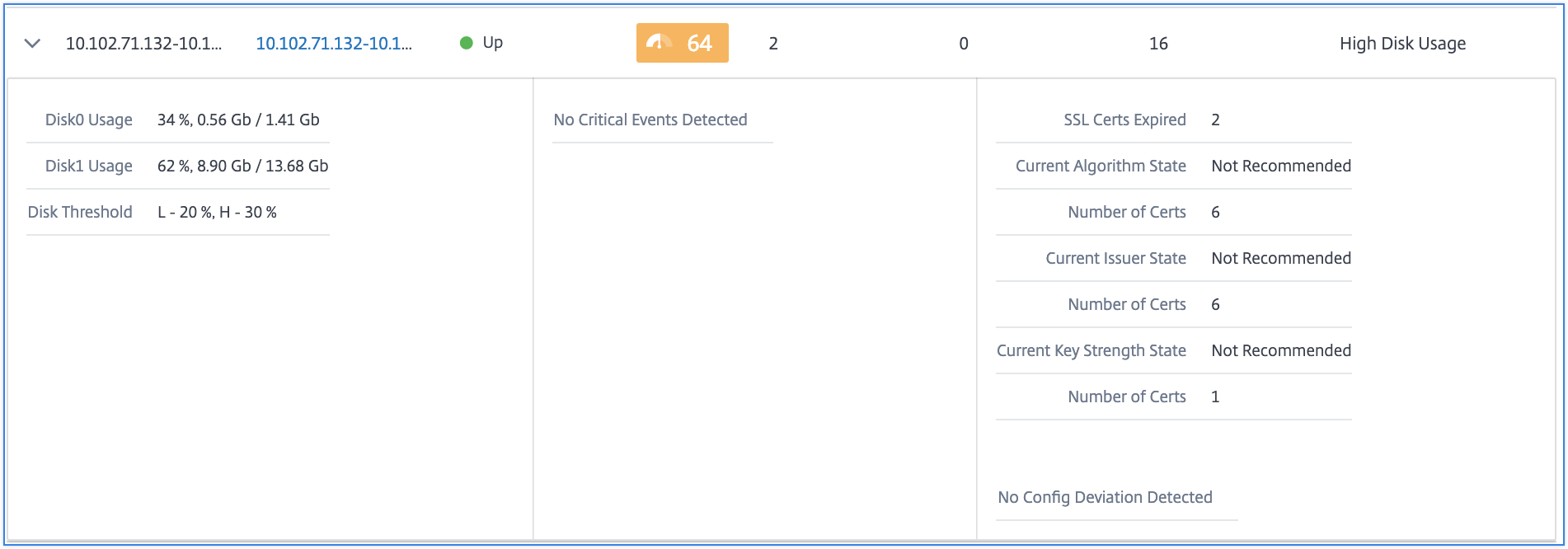
Die erweiterte Tabellenzeile zeigt die Fehler an, die auf der Instanz für alle Kategorien aufgetreten sind. Im obigen Beispiel können Sie sehen, dass Fehler bei Systemressourcen, SSL-Konfiguration und Abweichungen in Konfigurationsdateien aufgetreten sind. Es wurden jedoch keine kritischen Ereignisse von der Instanz gemeldet.
So verwenden Sie das Übersichtsfenster
Das Übersichtsfenster hilft Ihnen, sich effizient und schnell auf die Instanzen zu konzentrieren, die überprüft werden müssen oder sich in einem kritischen Zustand befinden. Das Fenster ist in drei Registerkarten unterteilt – Übersicht, Instanzinformationen und Traffic-Profil. Die Änderungen, die Sie in diesem Fenster vornehmen, ändern die Anzeige sowohl im Circle Pack- als auch im Tabellenansichtsformat. Die folgenden Abschnitte beschreiben diese Registerkarten detaillierter. Die Beispiele in den folgenden Abschnitten helfen Ihnen, die verschiedenen Auswahlkriterien effizient zu nutzen, um die von den Instanzen gemeldeten Probleme zu analysieren.
Übersicht:
Die Registerkarte Übersicht ermöglicht es Ihnen, die Instanzen basierend auf Hardwarefehlern, Nutzung, abgelaufenen Zertifikaten und ähnlichen Indikatoren zu überwachen, die in den Instanzen auftreten können. Die Indikatoren, die Sie hier überwachen können, sind wie folgt:
-
CPU-Auslastung
-
Speicherauslastung
-
Festplattenauslastung
-
Systemausfälle
-
Kritische Ereignisse
-
Ablauf von SSL-Zertifikaten
Die folgenden Beispiele veranschaulichen, wie Sie mit dem Übersichtsfenster interagieren können, um die Instanzen zu isolieren, die Fehler melden.
Beispiel 1: Instanzen anzeigen, die sich in einem Überprüfungszustand befinden:
Wählen Sie das Kontrollkästchen Überprüfen, um nur die Instanzen anzuzeigen, die keine kritischen Fehler melden, aber dennoch Aufmerksamkeit benötigen.
Die Histogramme im Übersichtsfenster stellen eine aggregierte Anzahl von Instanzen dar, basierend auf Ereignissen mit hoher CPU-Auslastung, hoher Speicherauslastung und hoher Festplattenauslastung. Die Histogramme sind in 10 %, 20 %, 30 %, 40 %, 50 %, 60 %, 70 %, 80 %, 90 % und 100 % unterteilt. Bewegen Sie den Mauszeiger über eines der Balkendiagramme. Die Legende am unteren Rand des Diagramms zeigt den Nutzungsbereich und die Anzahl der Instanzen in diesem Bereich an. Sie können auch auf das Balkendiagramm klicken, um alle Instanzen in diesem Bereich anzuzeigen.
Beispiel 2: Instanzen anzeigen, die zwischen 10 % und 20 % des zugewiesenen Speichers verbrauchen:
Klicken Sie im Abschnitt zur Speicherauslastung auf das Balkendiagramm. Die Legende zeigt, dass der ausgewählte Bereich 10–20 % beträgt und 29 Instanzen in diesem Bereich arbeiten.
Sie können auch mehrere Bereiche in diesen Histogrammen auswählen.
Beispiel 3: Instanzen anzeigen, die in mehreren Bereichen viel Speicherplatz belegen:
Um Instanzen anzuzeigen, die zwischen 0 und 10 % des Speicherplatzes belegt haben, ziehen Sie den Mauszeiger über die beiden Bereiche.
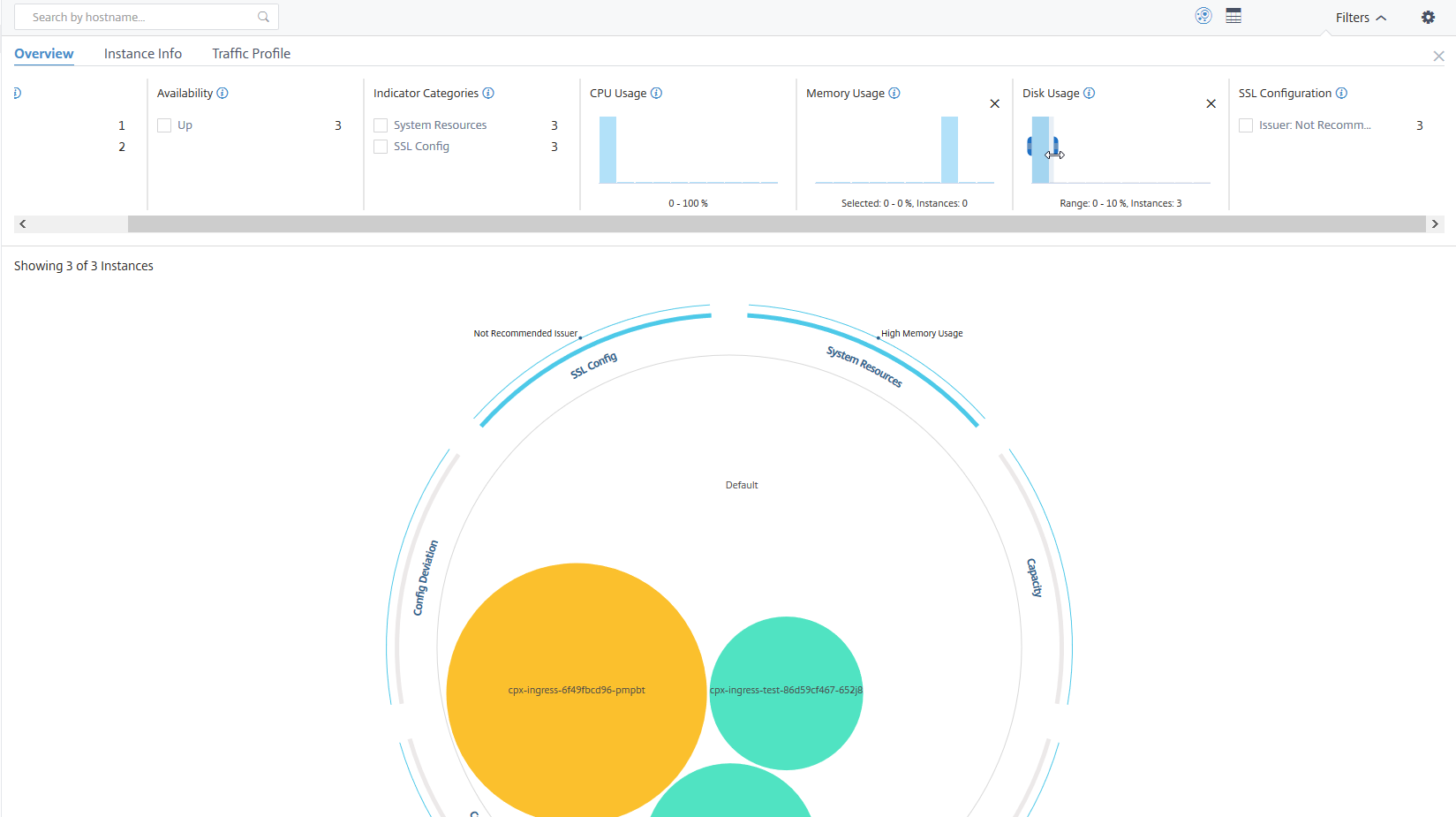
Hinweis
Klicken Sie auf “X”, um die Auswahl zu entfernen. Sie können auch auf Zurücksetzen klicken, um mehrere Auswahlen zu entfernen.
Die horizontalen Balkendiagramme im Übersichtsfenster zeigen die Anzahl der Instanzen an, die Systemfehler, kritische Ereignisse und den Ablaufstatus der SSL-Zertifikate melden. Aktivieren Sie das Kontrollkästchen, um diese Instanzen anzuzeigen.
Beispiel 4: Instanzen für abgelaufene SSL-Zertifikate anzeigen:
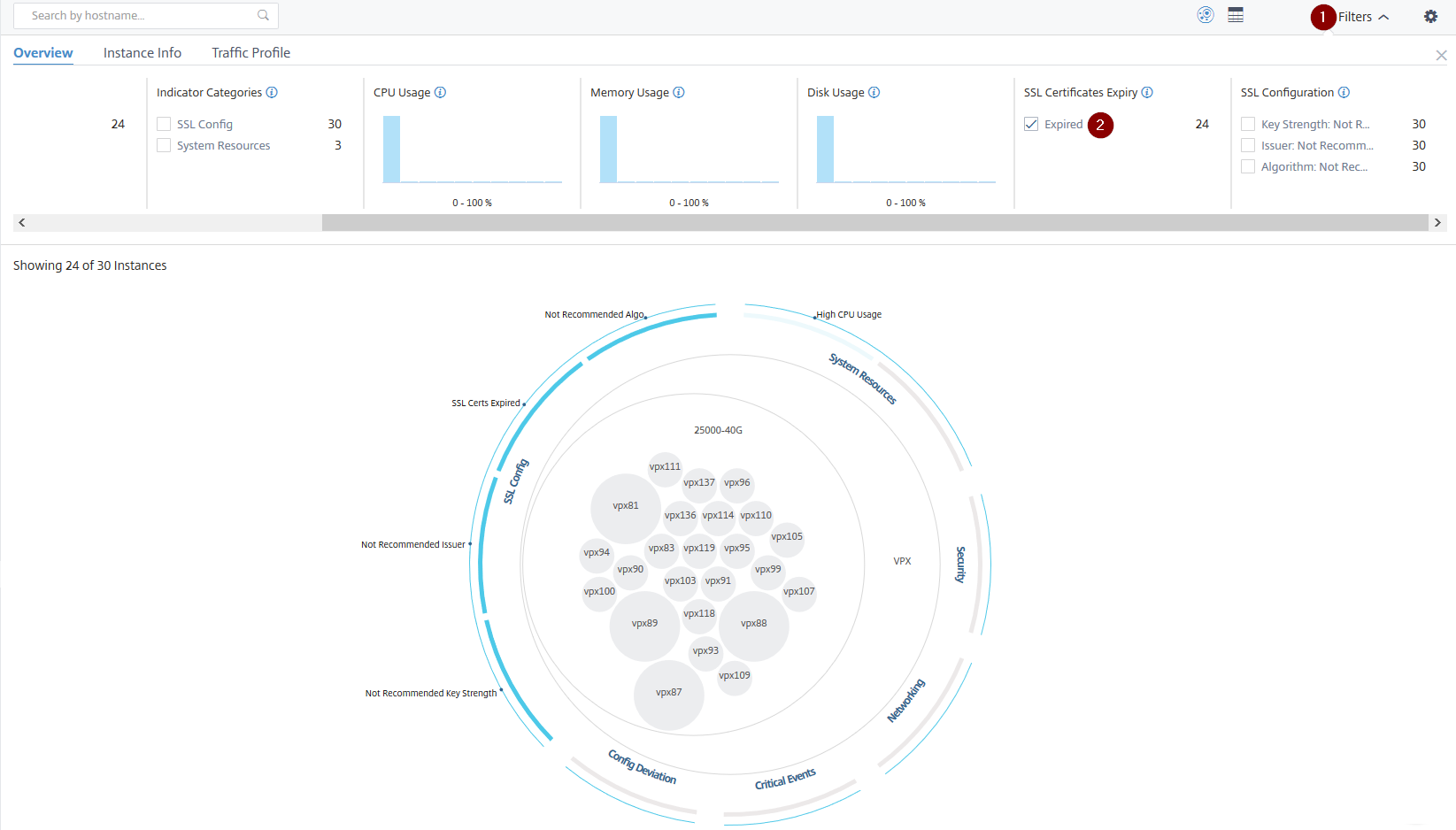
1 – Klicken Sie auf die Liste Filter.
2 – Wählen Sie im Abschnitt Ablauf von SSL-Zertifikaten das Kontrollkästchen Abgelaufen aus, um die Instanzen anzuzeigen.
Instanzinformationen
Das Fenster Instanzinformationen ermöglicht es Ihnen, Instanzen basierend auf dem Bereitstellungstyp, Instanztyp, Modell und der Softwareversion anzuzeigen. Sie können mehrere Kontrollkästchen auswählen, um Ihre Auswahl einzugrenzen.
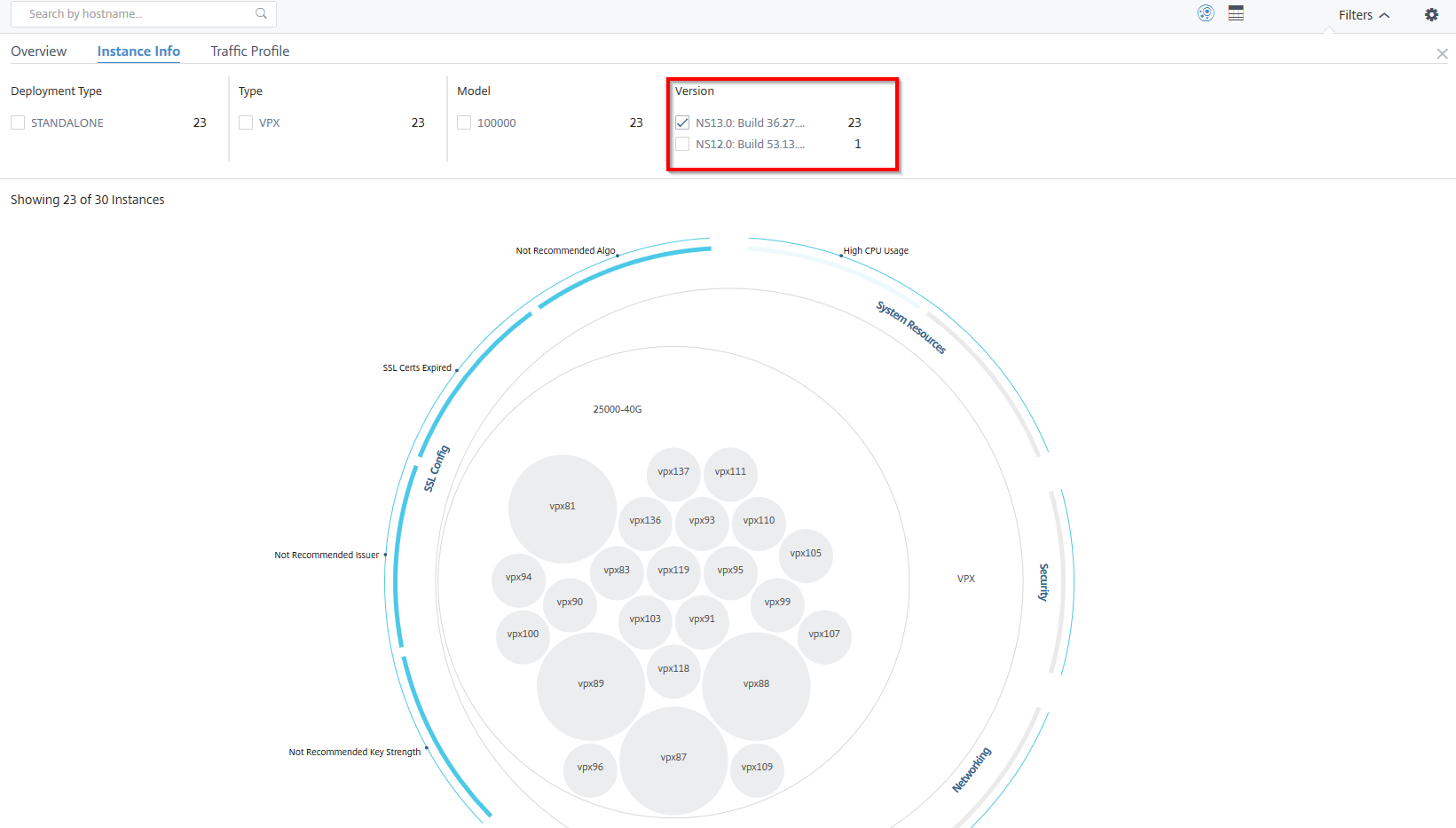
Beispiel 5: NetScaler VPX-Instanzen mit spezifischer Build-Nummer anzeigen:
Wählen Sie die Version aus, die Sie anzeigen möchten.
Traffic-Profil
Die Histogramme im Traffic-Profil-Fenster stellen eine aggregierte Anzahl von Instanzen dar, basierend auf dem lizenzierten Durchsatz der Instanzen, der Anzahl der Anfragen, Verbindungen und Transaktionen, die von den Instanzen verarbeitet werden. Wählen Sie das Balkendiagramm aus, um Instanzen in diesem Bereich anzuzeigen.
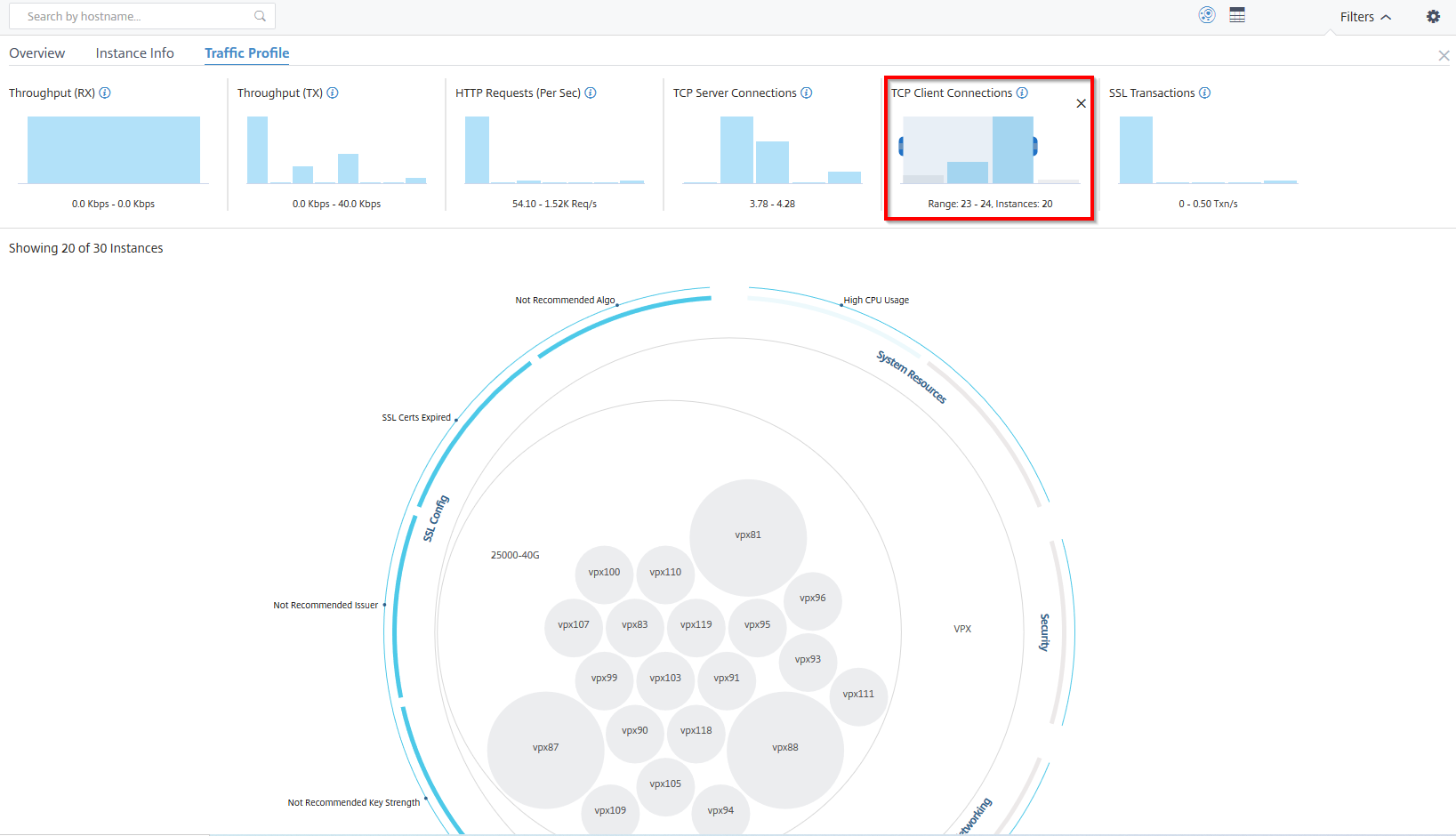
Beispiel 6: Instanzen anzeigen, die TCP-Verbindungen unterstützen:
Die folgende Abbildung zeigt die Anzahl der Instanzen, die TCP-Verbindungen unterstützen.
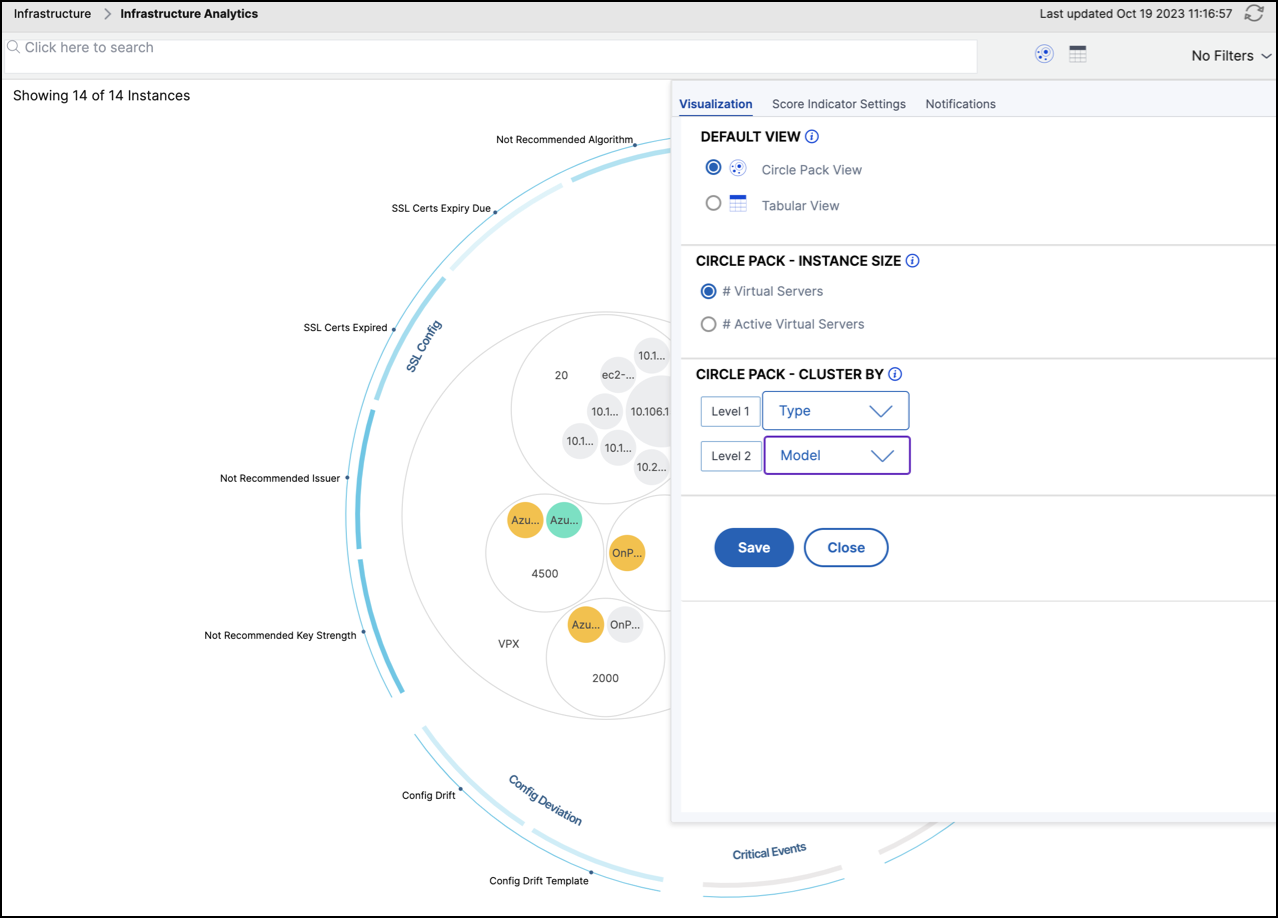
So verwenden Sie das Einstellungsfenster
Das Einstellungsfenster ermöglicht es Ihnen, die Standardansicht der Infrastruktur-Analysen festzulegen. Es ermöglicht Ihnen auch, die niedrigen und hohen Schwellenwerte für hohe CPU-Auslastung, hohe Festplattenauslastung und hohe Speicherauslastung festzulegen. Das Einstellungsfenster ist in zwei Registerkarten unterteilt – Ansicht und Score-Schwellenwerte.
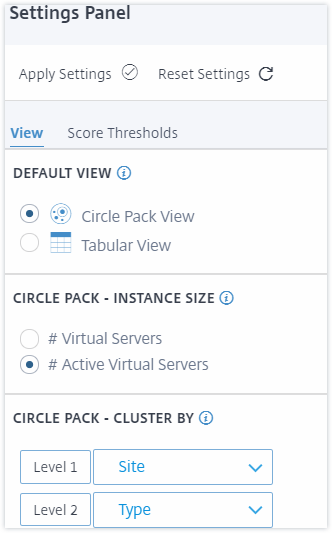
Ansicht
-
Standardansicht. Wählen Sie Circle Pack oder das Tabellenformat als Standardansicht auf der Analyse-Seite. Das von Ihnen ausgewählte Format ist das, was Sie sehen, wenn Sie die Seite in NetScaler Console aufrufen.
-
Circle Pack – Instanzgröße. Ermöglichen Sie, dass die Größe des Instanzkreises entweder durch die Anzahl der virtuellen Server oder die Anzahl der aktiven virtuellen Server bestimmt wird.
-
Circle Pack – Clustern nach. Legen Sie die zweistufige Clusterung der Instanzkreise fest. Weitere Informationen zur Instanzclusterung finden Sie unter Geklusterte Instanzkreise.
Score-Schwellenwerte
Sie können die niedrigen und hohen Schwellenwerte für hohe CPU-, Speicher- und Festplattenauslastung je nach den Traffic-Anforderungen in Ihrer Organisation ändern. Ziehen Sie die Griffe in jedem der Auswahl-Histogramme, um die Werte festzulegen.
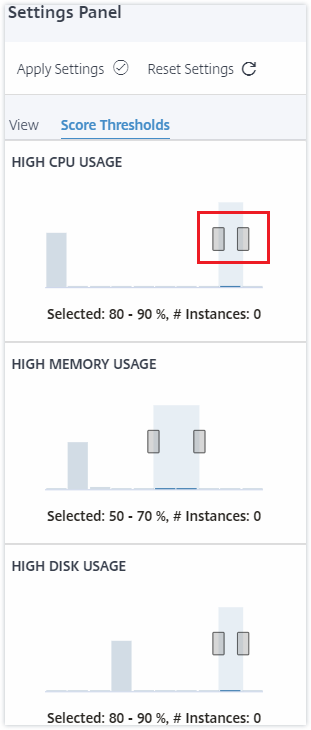
Hinweis
Klicken Sie auf Einstellungen anwenden, um diese Änderungen zu übernehmen, oder klicken Sie auf Zurücksetzen, um alle Änderungen zu entfernen.
So visualisieren Sie Daten auf dem Dashboard
Mithilfe von Infrastruktur-Analysen können Netzwerkadministratoren jetzt innerhalb weniger Sekunden die Instanzen identifizieren, die die meiste Aufmerksamkeit benötigen. Um die Datenvisualisierung detaillierter zu verstehen, betrachten wir den Fall von Chris, einem Netzwerkadministrator der ExampleCompany.
Chris verwaltet viele NetScaler-Instanzen in der Organisation. Einige der Instanzen verarbeiten hohen Traffic, und Chris muss diese genau überwachen. Chris bemerkt, dass einige Instanzen mit hohem Traffic nicht mehr den gesamten durch sie fließenden Traffic verarbeiten. Um diese Reduzierung zu analysieren, musste Chris früher mehrere Datenberichte aus verschiedenen Quellen lesen. Chris musste mehr Zeit damit verbringen, die Daten manuell zu korrelieren und festzustellen, welche Instanzen sich nicht in einem optimalen Zustand befinden und Aufmerksamkeit benötigen.
Chris nutzt die Funktion “Infrastruktur-Analysen”, um den Zustand aller Instanzen visuell zu sehen.
Die folgenden beiden Beispiele veranschaulichen, wie Infrastruktur-Analysen Chris bei Wartungsaktivitäten unterstützt:
Beispiel 1 – Zur Überwachung des SSL-Traffics:
Chris bemerkt im Circle Pack, dass eine Instanz einen niedrigen Instanz-Score hat und sich diese Instanz im Zustand “Kritisch” befindet. Chris klickt auf diese Instanz, um das Problem zu sehen. Die Instanzzusammenfassung zeigt an, dass ein SSL-Kartenfehler auf dieser Instanz vorliegt und die Instanz den SSL-Traffic nicht verarbeiten kann (der SSL-Traffic hat sich reduziert). Chris extrahiert diese Informationen und sendet einen Bericht an das Team, um das Problem sofort zu untersuchen.
Beispiel 2 – Zur Überwachung von Konfigurationsänderungen:
Chris bemerkt auch, dass sich eine andere Instanz im Zustand “Überprüfung” befindet und dass es kürzlich eine Konfigurationsabweichung gab. Wenn Chris auf den Risikoindikator für Konfigurationsabweichungen klickt, bemerkt Chris, dass RC4 Cipher, SSL v3, TLS 1.0 und TLS 1.1 bezogene Konfigurationsänderungen vorgenommen wurden, die möglicherweise auf Sicherheitsbedenken zurückzuführen sind. Chris bemerkt auch, dass das SSL-Transaktions-Traffic-Profil für diese Instanz gesunken ist. Chris exportiert diesen Bericht und sendet ihn an den Administrator zur weiteren Untersuchung.