-
Getting Started with NetScaler
-
Solutions for Telecom Service Providers
-
Load Balance Control-Plane Traffic that is based on Diameter, SIP, and SMPP Protocols
-
Provide Subscriber Load Distribution Using GSLB Across Core-Networks of a Telecom Service Provider
-
Authentication, authorization, and auditing application traffic
-
Basic components of authentication, authorization, and auditing configuration
-
-
Web proxy support for outbound calls to IDP or third party endpoints
-
Web Application Firewall protection for VPN virtual servers and authentication virtual servers
-
On-premises NetScaler Gateway as an identity provider to Citrix Cloud™
-
Authentication, authorization, and auditing configuration for commonly used protocols
-
Troubleshoot authentication and authorization related issues
-
-
-
-
-
-
Configure DNS resource records
-
Configure NetScaler as a non-validating security aware stub-resolver
-
Jumbo frames support for DNS to handle responses of large sizes
-
Caching of EDNS0 client subnet data when the NetScaler appliance is in proxy mode
-
Use case - configure the automatic DNSSEC key management feature
-
Use Case - configure the automatic DNSSEC key management on GSLB deployment
-
-
-
Source IP address whitelisting for GSLB communication channels
-
Use case: Deployment of domain name based autoscale service group
-
Use case: Deployment of IP address based autoscale service group
-
-
Persistence and persistent connections
-
Advanced load balancing settings
-
Gradually stepping up the load on a new service with virtual server–level slow start
-
Protect applications on protected servers against traffic surges
-
Retrieve location details from user IP address using geolocation database
-
Use source IP address of the client when connecting to the server
-
Use client source IP address for backend communication in a v4-v6 load balancing configuration
-
Set a limit on number of requests per connection to the server
-
Configure automatic state transition based on percentage health of bound services
-
-
Use case 2: Configure rule based persistence based on a name-value pair in a TCP byte stream
-
Use case 3: Configure load balancing in direct server return mode
-
Use case 6: Configure load balancing in DSR mode for IPv6 networks by using the TOS field
-
Use case 7: Configure load balancing in DSR mode by using IP Over IP
-
Use case 10: Load balancing of intrusion detection system servers
-
Use case 11: Isolating network traffic using listen policies
-
Use case 12: Configure Citrix Virtual Desktops for load balancing
-
Use case 13: Configure Citrix Virtual Apps and Desktops for load balancing
-
Use case 14: ShareFile wizard for load balancing Citrix ShareFile
-
Use case 15: Configure layer 4 load balancing on the NetScaler appliance
-
-
-
-
Authentication and authorization for System Users
-
-
-
Configuring a CloudBridge Connector Tunnel between two Datacenters
-
Configuring CloudBridge Connector between Datacenter and AWS Cloud
-
Configuring a CloudBridge Connector Tunnel Between a Datacenter and Azure Cloud
-
Configuring CloudBridge Connector Tunnel between Datacenter and SoftLayer Enterprise Cloud
-
Configuring a CloudBridge Connector Tunnel Between a NetScaler Appliance and Cisco IOS Device
-
CloudBridge Connector Tunnel Diagnostics and Troubleshooting
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
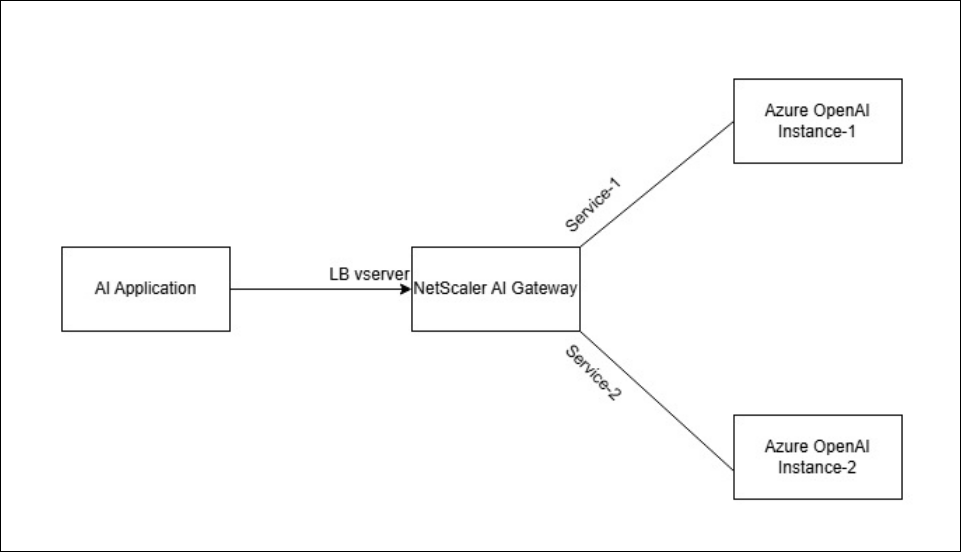
Configure load balancing for AI models
Token quota awareness ensures efficient distribution of requests across models while controlling cost and performance. NetScaler AI Gateway supports two load balancing methods:
- Token latency–based load balancing: Routes traffic to the backend with the lowest response time while considering token usage.
- Round robin load balancing: Evenly distributes requests across all backends regardless of token consumption. By integrating token quota awareness into these strategies, the gateway prevents overload, optimizes resource utilization, and maintains predictable service quality.
-
Create a front-end and a backend AI gateway profile. The front-end profile is bound to the load balancing virtual server. While the backend profile is bound to the service which NetScaler uses to connect to the Large Language Model (LLM).
-
Front-end profile
add aigwprofile <FrontendProfileName> -endpointType azureopenai –profileType frontend <!--NeedCopy-->Example:
add aigwprofile azureoai_frontend_profile -endpointType azureopenai -profileType frontend <!--NeedCopy--> -
Backend profile for each AzureOpenAI model deployment if you need different quota limits on them
add aigwprofile <BackendProfileName> -endpointType azureopenai –profileType backend -tokenQuota <TokenQuota> -quotaRefreshFrequency <IntervalInMinsAfterWhichTokenQuotaIsRefreshed> -authToken <authtokenstring> <!--NeedCopy-->In this configuration:
-
-tokenQuota <TokenQuota>: Token capacity of the backend server. -
-quotaRefreshFrequency <IntervalInMinsAfterWhichTokenQuotaIsRefreshed>: Quota refresh rate, in minutes. -
-authToken <authtokenstring>: Authorization token or API key to connect with LLM/AI model services.
Example:
add aigwprofile azureoai_backend_profile1 -endpointType azureopenai -profileType backend -tokenQuota 12000 -authToken {TokenString1} add aigwprofile azureoai_backend_profile2 -endpointType azureopenai -profileType backend -tokenQuota 24000 -authToken {TokenString2} <!--NeedCopy--> -
-
-
Create two servers for two gpt-5.1 deployments of an AzureOpenAI endpoint if it is an FQDN.
add server <ServerName> <!--NeedCopy-->Example:
add server AzureAI-1-Svr dep-1.openai.azure.com add server AzureAI-2-Svr dep-2.openai.azure.com <!--NeedCopy--> -
Create two services, one for each deployment, and attach the backend
aigwprofileto it. Provide the IP address or FQDN and the port of the AzureOpenAI instance.Or
Create a service group, one for each deployment. Attach the backend
aigwprofileto it and bind the members to a service group.add servicegroup <ServiceGroupName> <Protocol> -aigwProfileName <BackendProfileName> bind servicegroup <serviceGroupName> (<IP>@ | <serverName>) <port> <!--NeedCopy-->Example:
add servicegroup AzureAI-SG-1 SSL -aigwProfilename azureoai_backend_profile1 add servicegroup AzureAI-SG-2 SSL -aigwProfilename azureoai_backend_profile2 bind servicegroup AzureAI-SG-1 AzureAI-1-Svr 443 bind servicegroup AzureAI-SG-2 AzureAI-2-Svr 443 <!--NeedCopy--> -
Create an load balancing virtual server and provide a virtual IP and port on which the load balancing virtual server is listening and attach the front-end
aigwprofileto it.add lb vserver <LbVserverName> SSL <IP> <Port> -aigwProfileName <NameOfFrontendAIGWProfile> -lbmethod <LoadBalancingMethod> <!--NeedCopy-->Example:
add lb vserver AzureOpenAIGpt5.1 SSL 10.0.0.1 443 -aigwProfileName azureoai_frontend_profile -lbmethod leastllmtokenlatency <!--NeedCopy-->Note:
-
You must create one load balancing virtual server per model. Do not bind models of different services to the same load balancing virtual server.
-
Ensure that the server authentication and server certificates are enabled for the LLM endpoint service.
add ssl certKey <certkeyName> -cert <path_to_cert_file> -key <path_to_key_file> bind ssl service <service_name> -certkeyName <CA_certkeyName> -CA add ssl profile <profile_name> -serverAuth ENABLED bind ssl service <service_name> -profileName <profile_name> <!--NeedCopy-->Example:
bind ssl service <highlight>AzureAI-1</highlight> -certkeyName <CA_certkeyName> -CA <!--NeedCopy-->
-
-
Bind the model deployment services or service group to the load balancing virtual server.
bind lb vserver <LbVserverName> <ServiceGroupName> <!--NeedCopy-->Example:
bind lbvserver AzureOpenAIGpt5.1 AzureAI-SG-1 bind lbvserver AzureOpenAIGpt5.1 AzureAI-SG-2 <!--NeedCopy-->
You now have load balancing virtual server load balancing the LLM queries to 2 deployments of gpt-5.1 on AzureOpenAI. Load balancing virtual server serves the LLM requests to the endpoint having least token latency and maintains quota limits at each service Level.
Points to note
- Front-end
aigwprofiletakes only 1 parameter-endpointtype. - Backend
aigwprofiletakes 2 mandatory parameters-endpointtypeandtokenQuota; and 2 optional parameters-authTokenandquotarefreshfrequency. - You can only set the
aigwProfileNameparameter duringaddoperation of the load balancing and service entity.setorunsetoperation of theaigwProfileNameparameter is not supported.
Share
Share
In this article
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.