-
Getting Started with NetScaler
-
Solutions for Telecom Service Providers
-
Load Balance Control-Plane Traffic that is based on Diameter, SIP, and SMPP Protocols
-
Provide Subscriber Load Distribution Using GSLB Across Core-Networks of a Telecom Service Provider
-
Authentication, authorization, and auditing application traffic
-
Basic components of authentication, authorization, and auditing configuration
-
-
Web proxy support for outbound calls to IDP or third party endpoints
-
Web Application Firewall protection for VPN virtual servers and authentication virtual servers
-
On-premises NetScaler Gateway as an identity provider to Citrix Cloud™
-
Authentication, authorization, and auditing configuration for commonly used protocols
-
Troubleshoot authentication and authorization related issues
-
-
-
-
-
-
Configure DNS resource records
-
Configure NetScaler as a non-validating security aware stub-resolver
-
Jumbo frames support for DNS to handle responses of large sizes
-
Caching of EDNS0 client subnet data when the NetScaler appliance is in proxy mode
-
Use case - configure the automatic DNSSEC key management feature
-
Use Case - configure the automatic DNSSEC key management on GSLB deployment
-
-
-
Source IP address whitelisting for GSLB communication channels
-
Use case: Deployment of domain name based autoscale service group
-
Use case: Deployment of IP address based autoscale service group
-
-
Persistence and persistent connections
-
Advanced load balancing settings
-
Gradually stepping up the load on a new service with virtual server–level slow start
-
Protect applications on protected servers against traffic surges
-
Retrieve location details from user IP address using geolocation database
-
Use source IP address of the client when connecting to the server
-
Use client source IP address for backend communication in a v4-v6 load balancing configuration
-
Set a limit on number of requests per connection to the server
-
Configure automatic state transition based on percentage health of bound services
-
-
Use case 2: Configure rule based persistence based on a name-value pair in a TCP byte stream
-
Use case 3: Configure load balancing in direct server return mode
-
Use case 6: Configure load balancing in DSR mode for IPv6 networks by using the TOS field
-
Use case 7: Configure load balancing in DSR mode by using IP Over IP
-
Use case 10: Load balancing of intrusion detection system servers
-
Use case 11: Isolating network traffic using listen policies
-
Use case 12: Configure Citrix Virtual Desktops for load balancing
-
Use case 13: Configure Citrix Virtual Apps and Desktops for load balancing
-
Use case 14: ShareFile wizard for load balancing Citrix ShareFile
-
Use case 15: Configure layer 4 load balancing on the NetScaler appliance
-
-
Processed insights
-
-
-
Authentication and authorization for System Users
-
-
-
Configuring a CloudBridge Connector Tunnel between two Datacenters
-
Configuring CloudBridge Connector between Datacenter and AWS Cloud
-
Configuring a CloudBridge Connector Tunnel Between a Datacenter and Azure Cloud
-
Configuring CloudBridge Connector Tunnel between Datacenter and SoftLayer Enterprise Cloud
-
Configuring a CloudBridge Connector Tunnel Between a NetScaler Appliance and Cisco IOS Device
-
CloudBridge Connector Tunnel Diagnostics and Troubleshooting
This content has been machine translated dynamically.
Dieser Inhalt ist eine maschinelle Übersetzung, die dynamisch erstellt wurde. (Haftungsausschluss)
Cet article a été traduit automatiquement de manière dynamique. (Clause de non responsabilité)
Este artículo lo ha traducido una máquina de forma dinámica. (Aviso legal)
此内容已经过机器动态翻译。 放弃
このコンテンツは動的に機械翻訳されています。免責事項
이 콘텐츠는 동적으로 기계 번역되었습니다. 책임 부인
Este texto foi traduzido automaticamente. (Aviso legal)
Questo contenuto è stato tradotto dinamicamente con traduzione automatica.(Esclusione di responsabilità))
This article has been machine translated.
Dieser Artikel wurde maschinell übersetzt. (Haftungsausschluss)
Ce article a été traduit automatiquement. (Clause de non responsabilité)
Este artículo ha sido traducido automáticamente. (Aviso legal)
この記事は機械翻訳されています.免責事項
이 기사는 기계 번역되었습니다.책임 부인
Este artigo foi traduzido automaticamente.(Aviso legal)
这篇文章已经过机器翻译.放弃
Questo articolo è stato tradotto automaticamente.(Esclusione di responsabilità))
Translation failed!
Processed insights
NetScaler records the application traffic flow events such as HTTP requests and responses in the form of counters and transactions. When this data is sent to NetScaler Console or other observability tools, the receiving tool processes the data and provides actionable insights. For example, NetScaler Console processes all transactions and generates Web Insight reports. However, this method poses challenges as significant data must be transferred from NetScaler to observability tools and logics must be created to obtain insights.
From NetScaler release 14.1-29.x onwards, NetScaler can process the raw data and generate processed insights that can be sent outside NetScaler. The following are the advantages of NetScaler generating processed insights:
- The data transferred from NetScaler to NetScaler Console or any other observability tool is minimum.
- Aggregation and filtering of data can be done according to the use case from the source itself. For example, aggregate data based on a client or a URL.
- The data transferred is easily consumable on observability tools without any processing.
- Dashboards on NetScaler Console or other observability tools can be built efficiently.
Processed insights from NetScaler® using stream analytics
The performance of a website or an application depends on how well you optimize the delivery of the content. Stream analytics aggregates the real-time statistics of the website or application traffic based on the expressions provided in an entity called, selector. For example, a selector can be a client IP or a URL. You can configure a stream identifier that specifies the selector to be used, the statistics collection interval, the sample count, and the field on which the records must be sorted. You can sort the data based on the requests and create a list of top records, such as, top URLs, top clients. These top records are known as top N, where N is the number or count of records listed.
NetScaler processes the top N records that are generated by the stream analytics and provides insights. You can also export the stream analytics data to NetScaler Console or any other observability tool.
Based on the data generated by the stream identifier, you can take the required actions, such as optimizing the traffic, limiting bandwidth consumption for user or client. For more information, see Configure policy for optimizing traffic and How to limit bandwidth consumption for user or client device.
When configuring stream identifiers, you can sort the values based on the following parameters:
- Number of requests
- Bandwidth utilization
- Number of connections
- Response time
If no parameter is provided, the “Number of requests” parameter is selected by default, and the records are sorted in descending order.
Notes:
- You can bind one stream identifier to multiple virtual servers and collect statistics from multiple virtual servers for the same stream selector expressions.
- You can export a maximum of 1000 Top N records per stream identifier.
- Stream identifier aggregates result data as stream sessions, based on the evaluation of the selector expression. The total length of the stream session is limited to 60 characters and the length is equally shared among the number of selector expressions. For example, if the selector has 5 expressions, each expression output gets 12 characters.
- You can configure export of stream analytics data through syslog and through analytics profile at the same time.
Configure stream analytics using the CLI
To configure stream analytics using the CLI, perform the following steps:
-
Configure stream selector.
add stream selector <name> <rule> ... <!--NeedCopy-->Example: To collect statistics aggregated at client IP and URL, run the following command:
> add stream selector myselector HTTP.REQ.URL CLIENT.IP.SRC Done > show stream selector myselector Name: myselector Expressions: 1) HTTP.REQ.URL 2) CLIENT.IP.SRC Done > <!--NeedCopy--> -
Configure an identifier for the selector.
add stream identifier <identifier name> <selector name> -interval <int in mins> -sort <req> -Log SYSLOG -LogInterval <int in mins> -LogLimit <int> <!--NeedCopy-->Example: To get statistics for each Client IP and URL and export them to
SYSLOG, run the following command:add stream identifier TopTalkers myselector -interval 5 -log SYSLOG -loginterval 10 -loglimit 10 <!--NeedCopy--> -
Create a responder policy to collect stats for the given identifier.
add responder policy <resp policy name> "analytics.stream(\"<identifier name>\").collect_stats" NOOP <!--NeedCopy-->Example:
add responder policy TopTalkers "analytics.stream(\"TopTalkers\").collect_stats" NOOP <!--NeedCopy--> -
Bind the responder policy to the target virtual server for which the traffic is to be analyzed by the identifier. To enable the same stream identifier to process traffic from multiple virtual servers, bind the responder policy to all the virtual servers.
bind lb vserver dnslb -policyName <resp policy name> -priority 1 -gotoPriorityExpression NEXT -type REQUEST <!--NeedCopy-->Example:
bind lb vserver dnslb -policyName TopTalkers -priority 1 -gotoPriorityExpression NEXT -type REQUEST <!--NeedCopy-->
Configure stream analytics using the GUI
To configure stream analytics through the GUI, perform the following steps:
-
Navigate to AppExpert > Action Analytics > Selectors.
-
In the details pane, click Add and set the Name and Expressions parameter.
-
Click Insert and then click Create.
-
Navigate to AppExpert > Action Analytics > Stream Identifiers.
-
In the details pane, click Add. In the Configure Stream Identifier page, set the following parameters, and click Create.
- Name
- Selector
- Interval
- Sample Count
- Sort
-
Navigate to AppExpert > Responder > Policies. On the Responder Policies page, click Add.
-
On the Create Responder Policy page, enter a name for the responder policy.
-
In the Expression editor, configure the condition for the responder policy. For example, ‘sys.check_limit(“limit_one_login”)’ and click Create.
-
Navigate to Traffic Management > Load Balancing > Virtual Servers.
-
On the Load Balancing Virtual Servers page, select the virtual server to which you want to bind the responder policy, and then click Open.
-
In the Configure Virtual Server (Load Balancing) dialog box, select the Policies tab. Select the checkbox next to the name of the policy that you want to bind to this virtual server and click OK.
Export of stream analytics data using syslog through CLI
To export the stream analytics data using syslog, perform the following steps by using the NetScaler CLI:
-
Create a syslog server endpoint. You can create multiple syslog servers for multiple log levels.
add audit syslogAction <syslog servername> <server ip address> -logLevel ALL -managementlog ALL -mgmtlogLevel ALL -dateFormat YYYYMMDD -userDefinedAuditlog YES -transport TCP -streamAnalytics <ALL/NONE> <!--NeedCopy-->Example:
add audit syslogAction topk_syslog_server 10.106.44.6 -logLevel ALL -managementlog ALL -mgmtlogLevel ALL -dateFormat YYYYMMDD -userDefinedAuditlog YES -transport TCP -streamAnalytics <enabled/disabled> <!--NeedCopy--> -
Create a syslog policy for the syslog server created in step 5.
add audit syslogPolicy <syslog policy> <syslog servername> <!--NeedCopy-->Example:
add audit syslogPolicy topk_syslog true topk_syslog_server <!--NeedCopy--> -
Bind the syslog policy at the right level.
bind syslogGlobal -policyName <syslog policy> -priority 1 <!--NeedCopy-->Example:
bind syslogGlobal -policyName topk_syslog -priority 1 <!--NeedCopy-->
Export of stream analytics data using syslog through GUI
To export the stream analytics data using syslog, perform the following steps by using the NetScaler GUI:
-
Navigate to Configuration > System > Auditing > Syslog.
-
In the Policies tab, click Add.
-
Enter a name for the policy, select Advanced Policy and click Add to create an auditing server.
-
Enter the required details in the Create Auditing server, select Stream Analytics, and click Create.
-
On the Syslog Auditing page, select the policy, and click Advanced Policy Global Bindings.
-
Select the policy, priority, and SYSTEM_GLOBAL from the Global Bind Type drop-down list. Click Bind.
Export stream analytics data to Observability tools using the CLI
You can export the stream analytics data in JSON format to third-party observability tools, such as Splunk. To export stream analytics data by using the NetScaler CLI, perform the following steps:
-
Create an analytics profile of type
streaminsightand enable thetopnparameter.add analytics profile <profile-name> -collectors Splunk -type streaminsight -topn ENABLED <!--NeedCopy-->Example:
add analytics profile Splunk_Prof -collectors Splunk -type streaminsight -topn ENABLED <!--NeedCopy--> -
Bind the stream identifier to the analytics profile.
bind stream identifier <identifier-name> -analyticsprofile <profile-name> <!--NeedCopy-->Example
bind stream identifier TopTalkers -analyticsprofile Splunk_Prof <!--NeedCopy--> -
Add a responder policy.
add responder policy <policy-name> <expression> <!--NeedCopy-->Example:
add responder policy TopTalkers "analytics.stream(\"TopTalkers\").collect_stats" NOOP <!--NeedCopy--> -
Bind the responder policy to the load balancing virtual server.
bind lb vserver <vserver-name> -policyName <policy-name> -priority 1 -gotoPriorityExpression NEXT -type REQUEST <!--NeedCopy-->Example:
bind lb vserver dnslb -policyName TopTalkers -priority 1 -gotoPriorityExpression NEXT -type REQUEST <!--NeedCopy--> -
Verify the configuration by running the
show analytics profile <name>andshow stream identifier globalidentifiercommands.Example 1: In the following example, the reference count indicates the stream identifiers associated with the analytics profile.
> sh analytics profile Splunk_Prof 1) Name: Splunk_Prof Collector: Splunk_ssl Profile-type: streaminsight TopN: ENABLED Data Format File: splunk_format.txt Authentication Token : ffc4a9d8c60f238e89eafcc9827991fal3302c41b2el455e4e2e262 Endpoint URL: /services/collector/event Endpoint Content-type: application/json Reference Count: 2 Managementlog: NONE Done <!--NeedCopy-->Example 2: The following is a sample output of
sh stream identifier globalidentifier:> sh stream identifier globalidentifier Name: globalidentifier Selector: clientipsrc Expressions: 1) CLIENT.IP.SRC Sample Count: 1 Interval: 1 min Log : SYSLOG Log Interval : 1 min Log Limit : 500 Sort by : BANDWIDTH Appflow logging: DISABLED SNMP trap: DISABLED Track Ack only pkts: DISABLED <!--NeedCopy-->
Export of stream analytics data to Observability tools using the GUI
You can export the stream analytics data in JSON format to third-party observability tools, such as Splunk. To export the stream analytics data by using the NetScaler GUI, perform the following steps:
-
Create an analytics profile of type
streaminsightand enable thetopNparameter.- Navigate to System > Profiles > Analytics Profiles and click Add.
-
On the Create Analytics Profile page, provide the following details:
- Enter a name for the profile.
- From the Collectors list, select the service that you created.
- Select a STREAM INSIGHT from the Type list.
- Enter the Analytics Auth Token that you received from the Observability endpoint such as Splunk.
- Enter the details for Analytics Endpoint URL, Analytics Endpoint Content Type, and Analytics Endpoint Metadata.
- Selecct topN.
- Select the Management Logs that you want to export and also the Output Mode in which you want to export.
- Click Create.
-
Navigate to Configuration > AppExpert > Action Anlytics > Stream Identifiers.
-
Select one or more required stream identifiers and click Show Bindings.
-
Click Bind. Select the analytics profile of type
streaminsightand click Bind.
The stream analytics data gets exported through the collector configured on the analytics profile of type streaminsight.
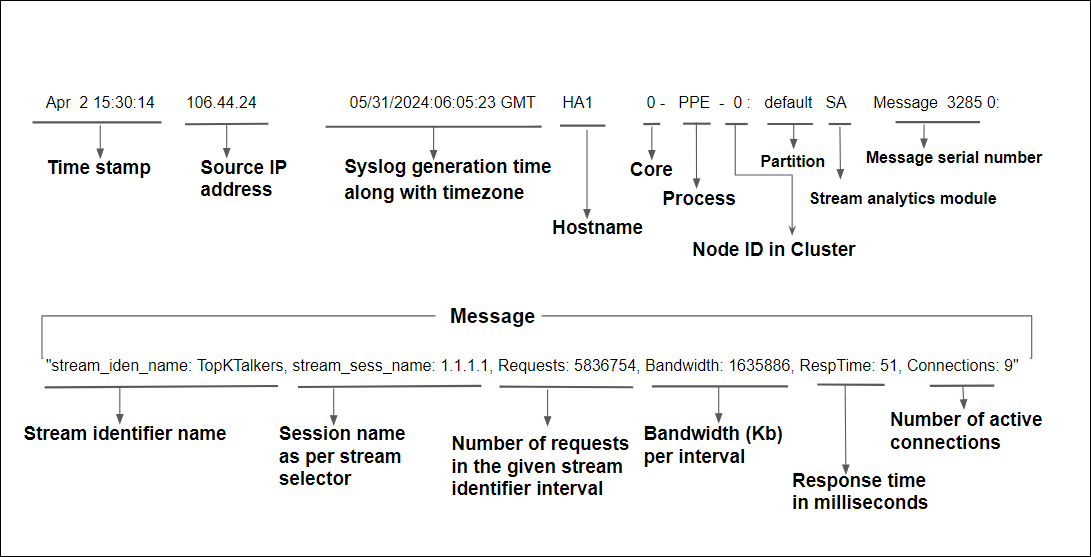
Sample stream analytics data sent in syslog
New audit log message module type for Stream Analytics = SA.
Apr 2 15:30:14 10.106.44.24 04/02/2024:09:58:28 GMT HA1 0-PPE-0 : default SA Message 3285 0 : "stream_iden_name: TopKTalkers, stream_sess_name: 1.1.1.1, Requests: 5836754, Bandwidth: 1635886, RespTime: 51, Connections: 9"
Apr 2 15:30:14 10.106.44.24 04/02/2024:09:58:28 GMT HA1 0-PPE-0 : default SA Message 3286 0 : "stream_iden_name: TopKTalkers, stream_sess_name: 2.2.2.2, Requests: 4939608, Bandwidth: 1384438, Resptime: 120, Connections: 7"
Apr 2 15:30:14 10.106.44.24 04/02/2024:09:58:28 GMT HA1 0-PPE-0 : default SA Message 3287 0 : "stream_iden_name: TopKTalkers, stream_sess_name: 3.3.3.3, Requests: 4293067, Bandwidth: 1203231, RespTime: 73, Connections: 8"
Apr 2 15:30:14 10.106.44.24 04/02/2024:09:58:28 GMT HA1 0-PPE-0 : default SA Message 3289 0 : "stream_iden_name: TopKTalkers, stream_sess_name: 4.4.4.4, Requests: 3834040, Bandwidth: 1074577, ResptTime: 109, Connections: 5"
<!--NeedCopy-->
The following image explains the stream analytics data sent in syslog:
Sample stream analytics data sent in JSON format to observability tools
The following image explains the stream analytics data sent in JSON format to Splunk:

Share
Share
In this article
-
Processed insights from NetScaler® using stream analytics
- Configure stream analytics using the CLI
- Configure stream analytics using the GUI
- Export of stream analytics data using syslog through CLI
- Export of stream analytics data using syslog through GUI
- Export stream analytics data to Observability tools using the CLI
- Export of stream analytics data to Observability tools using the GUI
- Sample stream analytics data sent in syslog
- Sample stream analytics data sent in JSON format to observability tools
This Preview product documentation is Cloud Software Group Confidential.
You agree to hold this documentation confidential pursuant to the terms of your Cloud Software Group Beta/Tech Preview Agreement.
The development, release and timing of any features or functionality described in the Preview documentation remains at our sole discretion and are subject to change without notice or consultation.
The documentation is for informational purposes only and is not a commitment, promise or legal obligation to deliver any material, code or functionality and should not be relied upon in making Cloud Software Group product purchase decisions.
If you do not agree, select I DO NOT AGREE to exit.